Mission Fidelity, Academic Quality, Safeguarding, and School Stewardship Under Constraint
Research Publication by Kenneth A.C. Nwaimo
Institutional Affiliation: New York Center for Advanced Research (NYCAR)
Publication No.: NYCAR-TTR-2026-RP048
DOI: https://doi.org/10.5281/zenodo.20581862
Date: June 2026
Copyright © 2026 New York Center for Advanced Research (NYCAR) and Kenneth A.C. Nwaimo. All rights reserved.
Peer Review and Publication Statement:
Approved for NYCAR’s June 2026 institutional publication release following doctoral-level review for philosophy-of-education coherence, Catholic education relevance, Nigerian contextual grounding, source discipline, APA 7 presentation, diagnostic-model suitability, and professional readability. Independent reviewers also examined the research for conceptual depth, learner-dignity clarity, teacher-formation relevance, safeguarding seriousness, and public-trust value. The research is recommended for NYCAR publication.
Abstract
Catholic secondary education in Nigeria carries a demanding public responsibility because it must do more than prepare students for examinations. It must form young people in faith, conscience, discipline, intellectual seriousness, civic responsibility, and service while operating in a national school environment strained by insecurity, learning poverty, teacher instability, household financial pressure, digital inequality, examination pressure, weak public infrastructure, and growing concern about child protection. A successful Catholic secondary school in Nigeria is therefore not simply a school that produces high grades or attractive buildings. It is a governed educational community where Catholic identity, curriculum fidelity, teaching quality, safeguarding, parent partnership, financial discipline, student welfare, and measurable learning all hold together.
The research treats Catholic secondary school leadership as a moral and intellectual work of mission stewardship. Catholic identity is not reduced to prayer assemblies, uniforms, or religious symbols; nor is academic quality reduced to examination results. The central educational responsibility is to make faith formation, intellectual formation, safeguarding, affordability, teacher formation, and school improvement mutually reinforcing rather than competing obligations. Nigeria’s educational context makes that challenge urgent. UNICEF has reported millions of primary and junior secondary age children out of school, serious deficits in basic literacy and numeracy, and documented attacks affecting schools in parts of the country. Catholic schools cannot repair the national system alone, but they can model reliable practice where management is honest, pastoral, evidence-conscious, and locally accountable.
The analysis draws on Catholic educational teaching, Nigerian education policy sources, public information from Catholic and Jesuit secondary schools, UNICEF and World Bank education evidence, NERDC curriculum materials, the Catholic Secretariat of Nigeria’s education summit agenda, and safe-school guidance. Loyola Jesuit College Abuja and Jesuit Memorial College Port Harcourt are used as practical Nigerian Catholic reference cases, not as perfect templates. Comparative lessons are also drawn from the Cristo Rey work-study model and wider Catholic school identity materials to examine affordability, career exposure, and whole-person formation.
The paper develops a Catholic Secondary School Success Index, a teacher-stability risk equation, a safeguarding and school-safety exposure model, a learning-reliability model, and a family-affordability stress score. These tools are not presented as universal formulas. They are decision aids for bishops, proprietors, principals, boards, diocesan education secretariats, and school leaders who need to know whether their Catholic school is succeeding beyond reputation. The conclusion is direct: Catholic secondary education in Nigeria succeeds when mission becomes visible in classroom quality, student protection, teacher competence, moral formation, credible governance, careful finance, and a school culture where families can trust both the learning and the character being formed.
Keywords: Catholic education, secondary schools, Nigeria, school stewardship, safeguarding, teacher formation, Catholic identity, school leadership, learning outcomes, affordability, NYCAR
Contents
List of Tables
List of Figures
References
List of Tables
Table 1. Major challenges and management responses for Catholic secondary schools in Nigeria.
Table 2. Catholic Secondary School Success Index components.
Table 3. Case-study lessons for Nigerian Catholic secondary education.
Table 4. Three-year implementation sequence.
Table 5. Annual school review evidence checklist.
List of Figures
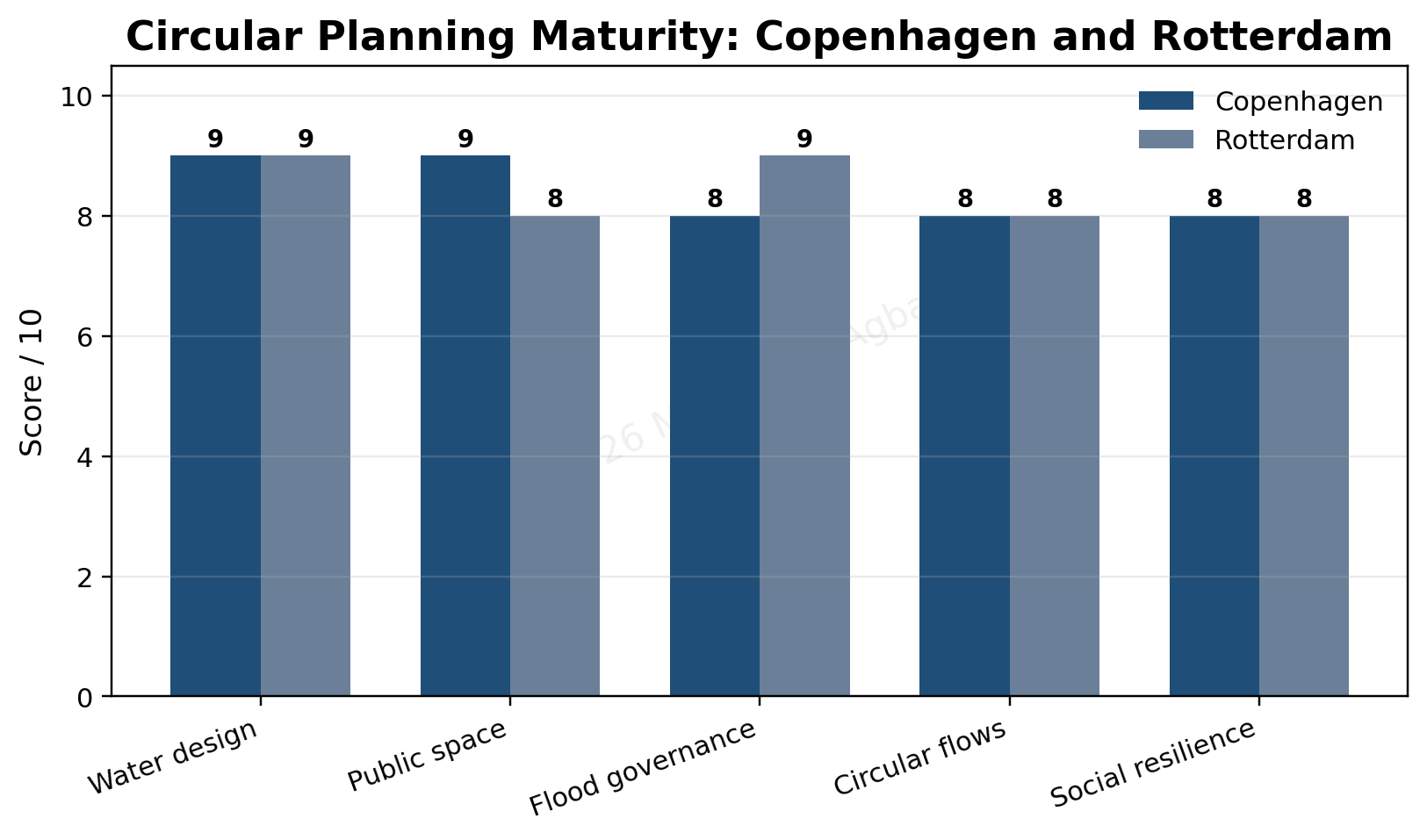
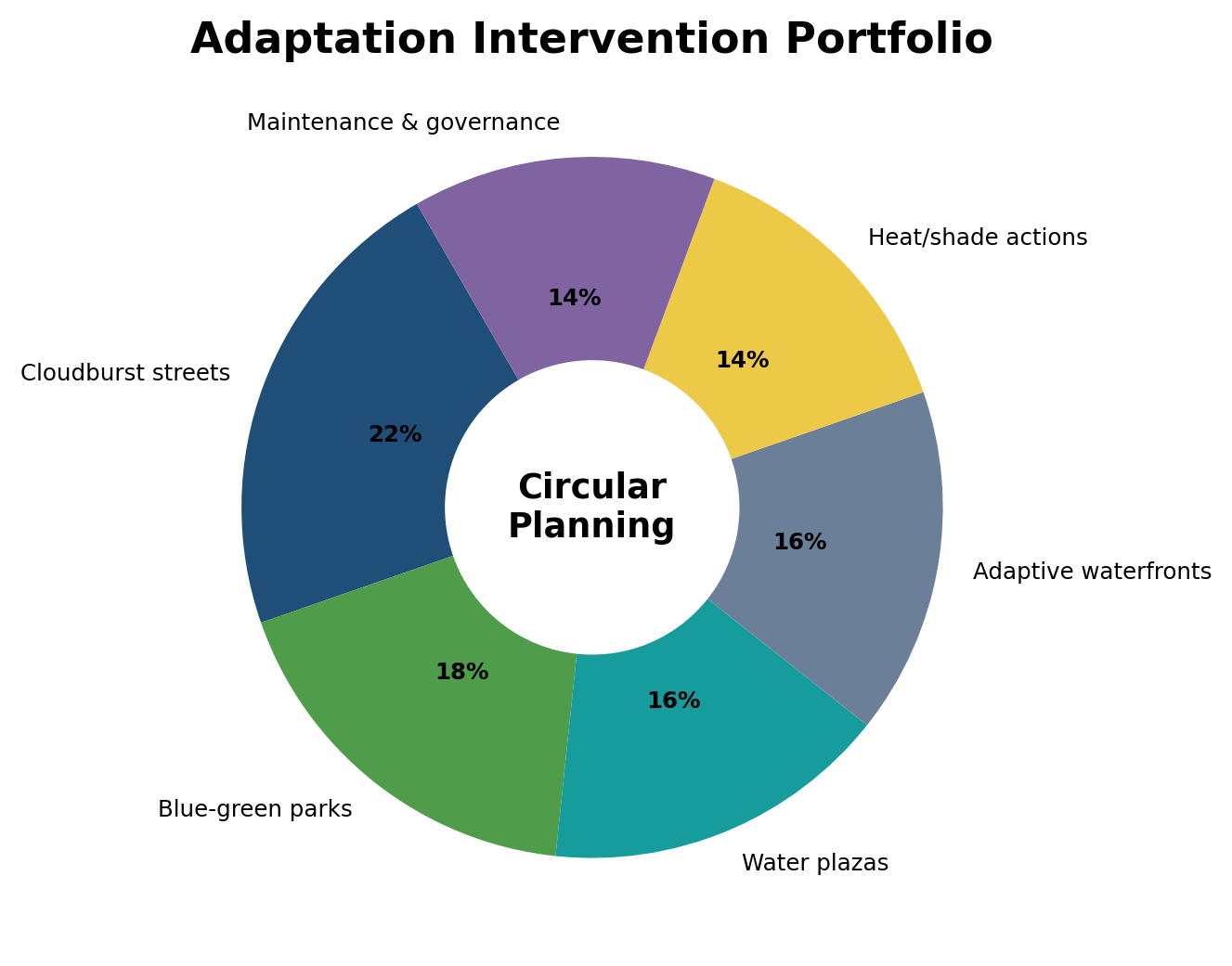
Figure 1. Pressure profile for Catholic secondary education in Nigeria.
Figure 2. Catholic Secondary School Success Index component weights.
Figure 3. Intervention priorities by urgency and management controllability.
Figure 4. Three-year Catholic secondary school improvement sequence.
Chapter 1: Introduction
Catholic secondary education in Nigeria cannot be treated as a soft extension of parish life or as a private version of government schooling with religious language attached. It carries a heavier burden. Parents send children to Catholic schools expecting academic seriousness, discipline, moral formation, safety, and some evidence that the school will not lose its soul while chasing examination rankings. Bishops and proprietors expect schools to serve evangelization and social development. Students expect a place where hard work has meaning and where adult authority is not arbitrary. Those expectations are legitimate, but they are difficult to meet under Nigerian conditions.
The pressure on secondary schools is not abstract. It appears in rising fees, teacher turnover, security anxieties, boarding supervision, parents struggling to pay in a difficult economy, students arriving with uneven literacy foundations, internet access that varies by household, and the pressure of external examinations. It also appears in the quieter moral questions: whether students are treated with dignity, whether corporal discipline has been replaced by wise formation, whether safeguarding files are current, whether weak students are supported before they are dismissed as unserious, and whether the Catholic identity of the school survives daily management choices.
This research is written for those responsible for Catholic secondary schools in Nigeria: bishops, diocesan education directors, religious congregations, principals, board members, chaplains, teachers, finance committees, parent associations, alumni groups, and serious researchers. It does not romanticize Catholic schooling. It assumes that Catholic education is credible only when it can be inspected in ordinary school life: classrooms, records, timetables, dormitories, staff meetings, fee policies, assessment evidence, liturgy, discipline, counseling, and parent communication.
1.1 Background to the Study
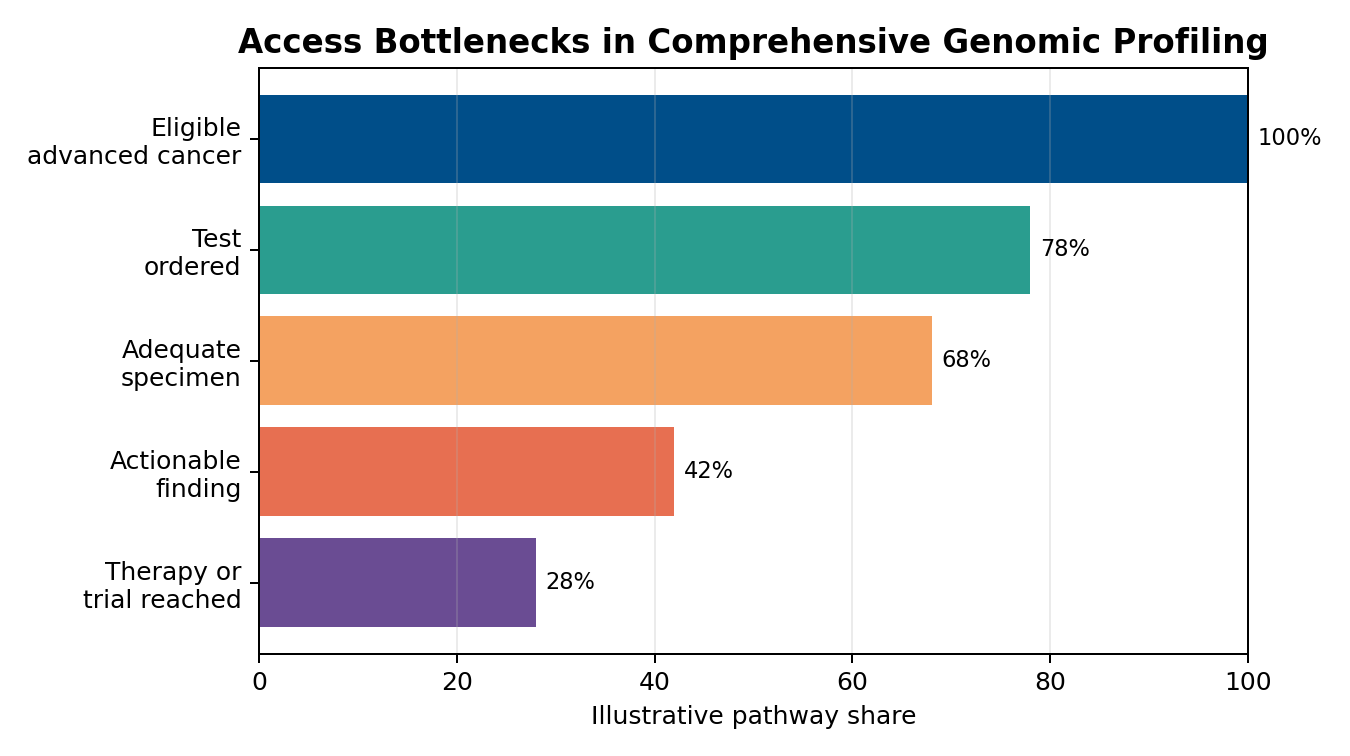
Nigeria’s secondary school system sits within a severe national education problem. UNICEF reported in September 2024 that 10.2 million children of primary school age and 8.1 million children of junior secondary school age were out of school, while 74 percent of children aged 7 to 14 lacked basic reading and mathematics skills (UNICEF Nigeria, 2024). Those figures do not describe only public schools. They describe the social environment in which Catholic schools recruit students, train teachers, engage families, and decide whether their mission will serve only families who can already afford quality or also vulnerable learners who need a credible pathway into formation and achievement.
Secondary schooling also sits at the point where earlier educational weakness becomes difficult to hide. A child who passed through weak primary instruction may arrive in junior secondary school without fluent reading, confident numeracy, disciplined study habits, or enough English language command to cope with science, mathematics, civic education, literature, and religious studies. Catholic school leaders can pretend that admission screening protects them from this problem, but that answer is too narrow for the mission. A Catholic school may be selective, but it cannot become indifferent to national learning failure.
The Nigerian curriculum context gives Catholic schools both obligation and room for leadership. The National Policy on Education sets out the state’s expectation that education should support national development, character, citizenship, and useful living (Federal Republic of Nigeria, 2013). The Nigerian Educational Research and Development Council (NERDC) provides curriculum materials for junior and senior secondary schooling, including the revised senior secondary curriculum resources (NERDC, n.d.). Catholic schools must meet these national requirements while adding a distinctive account of the person, moral responsibility, faith, service, and community. That double obligation requires careful management.
Catholic educational teaching deepens the point. The Vatican instruction on the identity of the Catholic school describes Catholic schools as historically responsive institutions called to serve present conditions while remaining faithful to Catholic identity (Congregation for Catholic Education, 2022). Pope Francis’s Global Compact on Education insists that education must be renewed around the person, the poor, the family, women, young people, ecology, and solidarity (Francis, 2020). A Nigerian Catholic secondary school should therefore be neither a narrow exam factory nor an unfocused faith environment. It must teach well and form well.
1.2 Problem Statement
The main problem is not that Catholic secondary schools in Nigeria lack mission language. Many have beautiful mottos, chapels, assemblies, feast-day celebrations, alumni pride, and discipline codes. The harder problem is whether these symbols are supported by institutional disciplines strong enough to deliver good education under pressure. A school can proclaim Catholic identity and still manage teachers poorly. It can demand discipline and still lack a child protection system. It can advertise excellence and still hide weak support for struggling learners. It can celebrate alumni success and still price itself away from the poor.
Private and faith-based schools often weaken in recognizable ways. Some depend too heavily on the personality of a strong principal instead of building durable habits of governance. Financial decisions may become reactive, driven by fee arrears, salary pressure, emergency repairs, and parent complaints rather than careful stewardship. Teachers may be expected to embody Catholic education without sustained formation, coaching, mentoring, or professional respect. Student welfare may also be narrowed to discipline while counseling, safeguarding, mental health, boarding supervision, and adolescent formation remain fragile.
The national setting compounds the problem. Insecurity has directly affected schooling in parts of Nigeria. UNICEF’s 2024 warning about school protection noted documented incidents in 2022 and 2023 and school closures in parts of Borno, Adamawa, and Yobe due to insecurity (UNICEF Nigeria, 2024). Even Catholic schools outside those highest-risk zones must treat safety as a serious governance responsibility. Boarding schools, in particular, cannot rely on reputation or prayer alone. They require risk assessment, visitor control, dormitory supervision, emergency communication, transport safety, and clear accountability.
There is also a moral problem of affordability. Catholic education historically served the poor as well as the aspiring middle class. Yet many Nigerian Catholic secondary schools now struggle with the cost of salaries, infrastructure, boarding, security, examination fees, technology, compliance, and facility maintenance. If a Catholic school raises fees without a scholarship plan, it may become financially stable while morally narrower. If it keeps fees low without paying teachers or maintaining safety, it may become accessible but weak. Successful leadership must handle this tension rather than hide it.
1.3 Aim and Objectives
The aim of this doctoral-level research is to examine how Catholic secondary schools in Nigeria can be run successfully under contemporary constraints while remaining faithful to Catholic identity, national curriculum expectations, child protection requirements, academic rigor, and social responsibility. Success is defined as more than prestige. It includes mission credibility, learning reliability, teacher stability, student safety, affordability, governance discipline, and measurable improvement.
The objectives are to clarify the distinctive management responsibilities of Catholic secondary schools in Nigeria; review Catholic educational principles and Nigerian education evidence; examine the operational challenges facing school leaders; analyze practical lessons from existing Catholic school models and relevant international cases; develop quantitative tools for school diagnosis; and offer a staged implementation plan that dioceses, religious proprietors, school boards, and principals can adapt to their context.
The paper does not pretend that one model can fit every Nigerian Catholic school. A rural day school, an urban boarding school, a diocesan school, a congregation-owned school, and a low-fee mission school do not carry identical conditions. The argument is that all of them need a disciplined management core: clear mission, competent teaching, safe systems, transparent finance, family partnership, teacher formation, student support, and evidence of learning.
1.4 Research Questions
Five research questions guide the research. How should a successful Catholic secondary school in Nigeria be defined beyond examination success and reputation? Which management conditions allow Catholic identity, academic quality, safeguarding, and affordability to support one another? How can school leaders measure whether learning, formation, safety, teacher stability, and parent trust are improving? What practical lessons can be drawn from Nigerian Catholic school cases and wider Catholic education practice? What staged plan can help school leaders strengthen their institutions without overwhelming staff or families?
The questions are intentionally practical. Catholic school leadership is not a matter for abstract praise. It is a matter of decisions: whom to hire, how to form teachers, how to assign chaplaincy, how to supervise dormitories, how to support struggling students, how to set fees, when to grant scholarship aid, what data to review, how to report safety concerns, how to involve parents, and how to protect the dignity of adolescents in a demanding environment.
1.5 Significance of the Study
This study matters because Catholic secondary schools continue to influence Nigerian family aspiration, moral formation, university preparation, and local leadership. Many graduates of Catholic schools become professionals, clergy, religious, public servants, entrepreneurs, teachers, and civic leaders. A weak Catholic school therefore does more than disappoint parents. It weakens a pipeline of conscience and competence that Nigeria badly needs.
The study also matters because Catholic schools stand at the intersection of Church credibility and public trust. When a Catholic school is well run, people see faith working through order, seriousness, compassion, and competence. When it is poorly run, people see religious language failing to protect students, support teachers, or tell the truth about performance. The credibility of the Church’s educational mission depends on everyday management more than on promotional materials.
For NYCAR, the contribution lies in turning Catholic school success into a serious institutional question. The research offers leaders diagnostic models, case analysis, and management recommendations without reducing Catholic education to corporate technique. It insists that mission and management belong together because young people are harmed when they are separated.
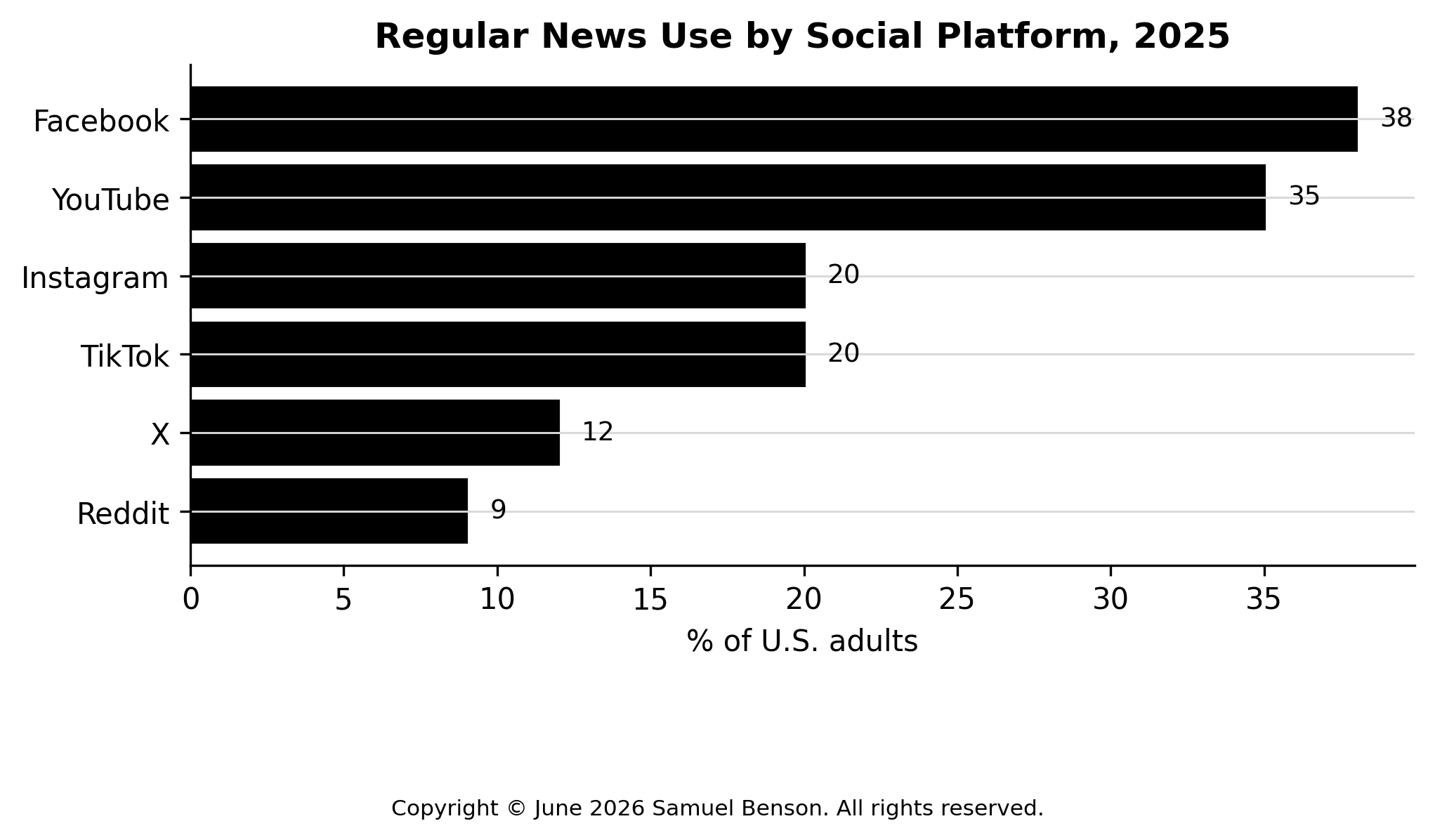
Figure 1. Pressure profile for Catholic secondary education in Nigeria.
Chapter 2: Literature Review
The literature relevant to Nigerian Catholic secondary education sits across several bodies of evidence: Catholic educational teaching, Nigerian education policy, global education data, safe-school practice, teacher development, school governance, adolescent welfare, and school finance. Treating these sources separately produces weak guidance. A principal does not experience them separately. Each morning, curriculum, teacher attendance, student discipline, fee arrears, worship, child protection, examinations, and parent concerns arrive together.
This review therefore reads the sources through the formation question: what must Catholic secondary school leaders do so that mission becomes reliable practice? The answer cannot be borrowed from one tradition alone. Catholic identity supplies the meaning of the school. Nigerian policy supplies national obligations. Education evidence supplies the warnings. Existing Catholic school cases show practical possibilities. Governance and diagnostic instruments help leaders examine whether the school is truly improving.
2.1 Catholic School Identity and Nigerian Context
Catholic school identity begins from a view of the human person. Education is not only training for employment or examination success. It is formation in truth, conscience, relationship, worship, service, and responsibility. The Vatican’s 2022 instruction on Catholic school identity emphasizes that Catholic schools must respond to changing social and cultural conditions while remaining faithful to their identity (Congregation for Catholic Education, 2022). That balance matters in Nigeria because schools cannot ignore insecurity, digital change, family pressure, plural religious environments, or employment uncertainty.
The Nigerian Catholic secondary school cannot preserve identity by retreating from national realities. It must teach the national curriculum, prepare students for public examinations, respond to technology, engage families across social classes, and interact with public authorities. At the same time, it should resist becoming only a private success machine. Catholic education loses something essential when it forms students to compete without forming them to serve.
Pope Francis’s Global Compact on Education strengthens this critique by placing the person, the family, the poor, women, young people, and ecological responsibility at the center of educational renewal (Francis, 2020). In Nigeria, those commitments translate into concrete school questions. Are girls protected and encouraged? Are poorer families visible in the school’s financial design? Are students learning civic responsibility and care for creation? Are parents partners rather than fee payers only?
2.2 National Policy, Curriculum, and Secondary School Expectations
The National Policy on Education remains an important point of reference because it defines education as a national development project, not only a private family service (Federal Republic of Nigeria, 2013). Secondary education is expected to prepare young people for useful living, higher education, citizenship, technical awareness, moral development, and social participation. Catholic schools may add explicit faith formation, but they do not stand outside these national obligations.
NERDC’s curriculum materials for junior and senior secondary education provide the formal content structure within which schools operate (NERDC, n.d.). A Catholic secondary school must therefore combine curriculum fidelity with formative depth. It should not use Catholic identity as an excuse for weak laboratory work, poor mathematics teaching, unstructured entrepreneurship education, or superficial civic education. Equally, it should not treat religious education as a ceremonial add-on while other subjects receive serious instructional attention.
Curriculum implementation is where many schools weaken. A syllabus may exist, but lesson planning, teacher mastery, assessment design, laboratory access, reading support, and feedback routines determine what students learn. Catholic school leaders need to inspect not only whether subjects are offered, but whether students are gaining competence in reading, writing, mathematics, science, digital literacy, moral reasoning, and communication.
2.3 Learning Poverty and the Secondary School Burden
UNICEF’s 2024 report that 74 percent of Nigerian children aged 7 to 14 lacked basic reading and mathematics skills should disturb secondary school leaders (UNICEF Nigeria, 2024). By secondary school, weak foundations become expensive. Students may memorize notes without understanding, avoid mathematics, read slowly, copy assignments, rely on lesson teachers, or pass through promotion systems without genuine mastery. A Catholic school that wants high examination results must still confront the foundation problem honestly.
The World Bank’s 2022 learning poverty update placed Sub-Saharan Africa’s rate near nine in ten children, underscoring the seriousness of basic reading failure across the region within which Nigeria sits (World Bank, 2022). Although learning poverty is measured at primary level, its effects reach secondary education. Teachers in JSS and SSS classrooms often face students whose age and class placement suggest readiness, while their literacy and numeracy skills say otherwise. Successful Catholic school stewardship must therefore build early diagnostic testing and remedial support into the first year of secondary school.
This is where Catholic education should show pastoral intelligence. A student who struggles academically should not be treated only as lazy, stubborn, or unsuitable for the school. Some students need structured reading support, numeracy catch-up, language development, study skills, counseling, and family engagement. Mercy does not mean lowering standards. It means refusing to confuse weak foundations with weak character.
2.4 Teacher Quality, Formation, and Stability
No Catholic school can outperform the quality and stability of its teachers for long. A strong mission statement cannot compensate for poor instruction. A beautiful chapel cannot teach algebra. Discipline cannot repair weak feedback. Teacher formation is therefore central to Catholic school success. The school must form teachers spiritually, professionally, and relationally.
Teacher pressure in Nigeria is intensified by inflation, migration, private tutoring markets, delayed salaries in some contexts, and competition from better-paying sectors. Catholic schools may expect teachers to be missionaries, but they should not use missionary language to excuse poor employment practice. A teacher who is underpaid, unsupported, overworked, and excluded from decision-making is unlikely to sustain excellent teaching. Recent Nigerian analysis ties these pressures to chronic teacher shortages and rising attrition, with pupil–teacher ratios well above recommended levels and several states failing to recruit teachers for years at a time (Athena Centre for Policy and Leadership, 2025).
Catholic school leaders should distinguish between teacher spirituality and teacher competence. Both matter. A teacher may be devout and poor at classroom explanation. Another may be academically strong but dismissive of adolescent dignity. Formation must include lesson design, assessment, classroom management, adolescent psychology, child protection, Catholic identity, use of technology, and professional ethics. The Catholic school teacher is not only a subject deliverer. The teacher is a witness, but witness without competence weakens trust.
2.5 Safeguarding, School Safety, and Boarding Welfare
School safety has become a national concern. UNICEF’s 2024 warning linked Nigeria’s education crisis to attacks on schools, documenting incidents in 2022 and 2023 and closures in Borno, Adamawa, and Yobe due to insecurity (UNICEF Nigeria, 2024). The Safe Schools Declaration sets out commitments to protect education from attack and sustain education during armed conflict (Safe Schools Declaration, 2015). At the national level, the Federal Ministry of Education has issued the National Policy on Safety, Security and Violence-Free Schools, with implementing guidelines that set a zero-tolerance standard for violence, bullying, and gender-based abuse and require school-level safety planning, prevention, and response (Federal Ministry of Education, 2021). This gives Nigerian schools, including Catholic ones, a concrete framework against which to test their own safeguarding arrangements rather than relying on goodwill. A Catholic secondary school in Nigeria must take such guidance seriously, even when located outside the most affected zones.
Safeguarding is broader than physical security. It includes protection from abuse, bullying, harmful punishment, sexual misconduct, neglect, emotional humiliation, unsafe transport, poor boarding supervision, and unreported incidents. A boarding school carries special responsibility because students live under institutional authority day and night. Dormitory supervision, medical care, visitor controls, food safety, bathing privacy, nighttime protocols, and complaint pathways are not minor administrative details.
Catholic schools must also handle discipline carefully. Discipline is necessary; humiliation is not. Formation requires boundaries, consequences, restitution, mentoring, and spiritual guidance. Where discipline depends on fear, secrecy, or arbitrary punishment, the school may produce compliance but not conscience. Catholic safeguarding should make it safe for a student to report harm without being accused of attacking the school’s reputation.
2.6 Finance, Affordability, and the Poor
Catholic schools face a hard financial equation. They must pay teachers, maintain facilities, secure campuses, support boarding, provide laboratories, fund chaplaincy, train staff, manage technology, and support indigent students. These costs are real. Yet Catholic education has a duty to remain connected to families who are not wealthy. Affordability is therefore not a public relations issue. It is a mission test.
The Catholic Secretariat of Nigeria’s 2024 Education Summit agenda included themes such as vulnerable persons in inclusive Catholic education, funding models, strategic partnerships, indigenous languages, artificial intelligence, and the Nigerian context of the Global Compact on Education (Nigeria Catholic Network, 2024). That agenda shows that Nigerian Church leadership understands the financial and social questions. The task is to translate summit conversation into school-level practice.
Scholarship policy is essential. A school that gives discounts informally may help some families, but it may also create resentment, favoritism, or hidden financial strain. A transparent scholarship fund, alumni bursary, parish-supported aid scheme, or work-linked support model may help schools preserve mission without destabilizing budgets. The Cristo Rey model, where students combine college-preparatory Catholic schooling with structured work experience to support access, is not directly transferable to every Nigerian setting, but its financial imagination is worth studying (Cristo Rey Network, n.d.).
2.7 Governance, Boards, and School Accountability
Catholic school governance often depends on the proprietor, principal, chaplain, religious congregation, board, parent association, and finance structure. When these roles are unclear, tension follows. A principal may carry responsibility without authority. A board may meet without evidence. A parish may influence the school informally without accountability. Parents may complain loudly but lack a structured channel. Teachers may experience decisions as sudden or personal.
Good governance does not make a school less Catholic. It makes mission more trustworthy. Decisions about fees, admissions, discipline, safeguarding, staffing, procurement, curriculum support, and capital projects should be recorded and reviewed. A Catholic school that cannot explain decisions invites suspicion even where leaders are honest. The same principle appears in Catholic governance work more broadly: stewardship must be visible enough to be trusted.
Boards and education committees should receive evidence, not only speeches. They should review learning outcomes, teacher retention, student welfare, safeguarding reports, fee arrears, scholarship use, parent complaints, alumni support, and facility risk. A board that only praises the principal is not governing. A board that only criticizes without helping solve constraints is also weak.
2.8 Digital Learning and Equity
Digital tools are now part of school operation: admissions, fees, records, communication, assignments, examination preparation, library access, lesson delivery, and parent engagement. But digital readiness varies widely among families and schools. The Nigerian Catholic school should avoid two errors. One error is rejecting technology as morally dangerous. The other is adopting technology without asking who is excluded.
Digital learning should begin with modest reliability: accurate student records, secure fee records, accessible parent communication, teacher lesson resources, digital safeguarding logs, and basic learning support. A school does not need to announce artificial intelligence before it can manage attendance, grade tracking, library use, reading support, and parent alerts properly. Technology should solve real school problems before it becomes a status symbol.
Digital equity also has a Catholic dimension. If assignments require online access that some students do not have, the school may widen inequality. If fee payment systems work only for banked parents with stable connectivity, poorer families may be embarrassed. If digital communication replaces human counseling, vulnerable families may disappear. Successful Catholic schools use technology to strengthen relationship, not to remove it.
2.9 Case Evidence and Practice Literature Gap
The Nigerian Catholic school cases available publicly offer useful but limited lessons. Loyola Jesuit College Abuja describes itself as a co-educational full boarding secondary school in the Jesuit tradition, opened in 1996, with teaching and supervision by Jesuits, the Sisters of the Holy Child Jesus, and lay staff (Loyola Jesuit College, n.d.). That case is useful because it shows the strength of a clear school tradition, boarding design, staff collaboration, and academic seriousness. It should not be treated as a simple template for all Catholic schools because cost, location, staffing, and infrastructure differ.
Jesuit Memorial College Port Harcourt presents itself through themes of whole-person education, faith, dialogue, curiosity, and excellence in the Ignatian tradition (Jesuit Memorial College, n.d.). The language matters because it resists a narrow view of schooling as examination preparation. A Catholic secondary school in Nigeria must form imagination, conscience, service, and intellectual competence together. The question is how to manage that formation under pressure.
The literature gap lies in integration. Catholic identity documents rarely provide Nigerian school stewardship tools. Nigerian education policy rarely addresses Catholic mission. School safety guidance may not speak to faith formation. Finance discussions may not address safeguarding. This paper responds by building a single success model for Catholic secondary education in Nigeria that joins mission, learning, safeguarding, staffing, finance, parent trust, and implementation.
Table 1. Major challenges and management responses for Catholic secondary schools in Nigeria.
| Challenge | Operational risk | Required Catholic management response |
| Insecurity and school safety | Learning disruption, parent fear, boarding exposure | Risk review, visitor control, emergency communication, safe-school partnerships, student reassurance |
| Teacher instability | Weak learning continuity, loss of school culture | Fair employment, induction, mentoring, appraisal, formation, and career pathway |
| Affordability pressure | Exclusion of poorer families and fee conflict | Transparent budgeting, scholarships, alumni aid, payment plans, and cost discipline |
| Learning deficits | Promotion without mastery and examination failure | Baseline testing, reading support, mathematics recovery, feedback, and honest assessment |
| Safeguarding weakness | Harm to students and loss of ecclesial trust | Training, reporting channels, records, supervision, background checks, and survivor-sensitive response |
Chapter 3: Methodology and Diagnostic Instruments
The methodology is documentary, integrative, and applied. It reviews Catholic educational teaching, Nigerian education evidence, public case information, safe-school guidance, and school stewardship concerns. It does not claim field interviews, proprietary school records, or confidential diocesan data. Its contribution is to convert available sources into a practical model that school leaders can use for self-examination and improvement.
A purely descriptive paper would not be enough because Catholic schools need tools, not only principles. The diagnostic instruments in this chapter do not pretend to measure grace, vocation, or conscience. They measure institutional conditions that can be observed: teacher stability, learning support, safeguarding, finance, family partnership, data use, and school improvement. The instruments serve prudential judgment; they do not replace it.
3.1 Research Design
The research design is appropriate for a doctoral-level institutional paper because the subject crosses theology, education management, public policy, child protection, finance, and school practice. The sources are read not as isolated authorities but as evidence for school leadership. The question is not whether Catholic education is good in principle. The question is how it can be run well in Nigeria under constraint.
The analytical procedure follows a coherent path rather than a mechanical sequence. The research identifies the national and ecclesial demands placed on Catholic secondary schools, examines public case evidence from Nigerian Catholic schools and relevant international Catholic models, develops diagnostic instruments for school self-examination, and proposes a staged renewal plan for proprietors, principals, boards, and diocesan education offices.
The design is intentionally modest about data. It does not rank schools or claim secret evidence. It offers a method that any serious Catholic school can adapt: gather local data, score the domains, discuss the results with responsible leaders, choose three priorities, and review progress annually.
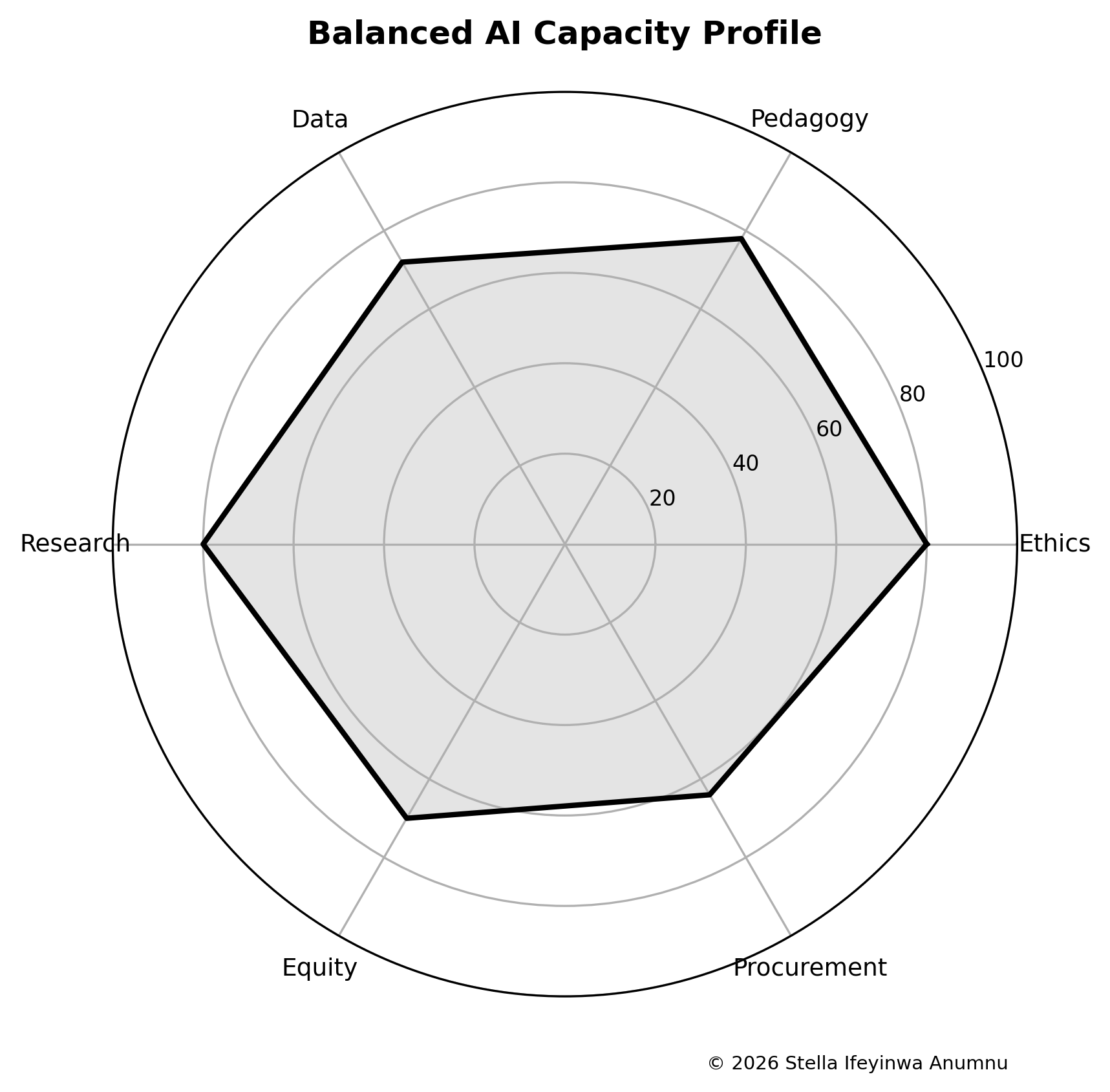
3.2 Catholic Secondary School Success Index
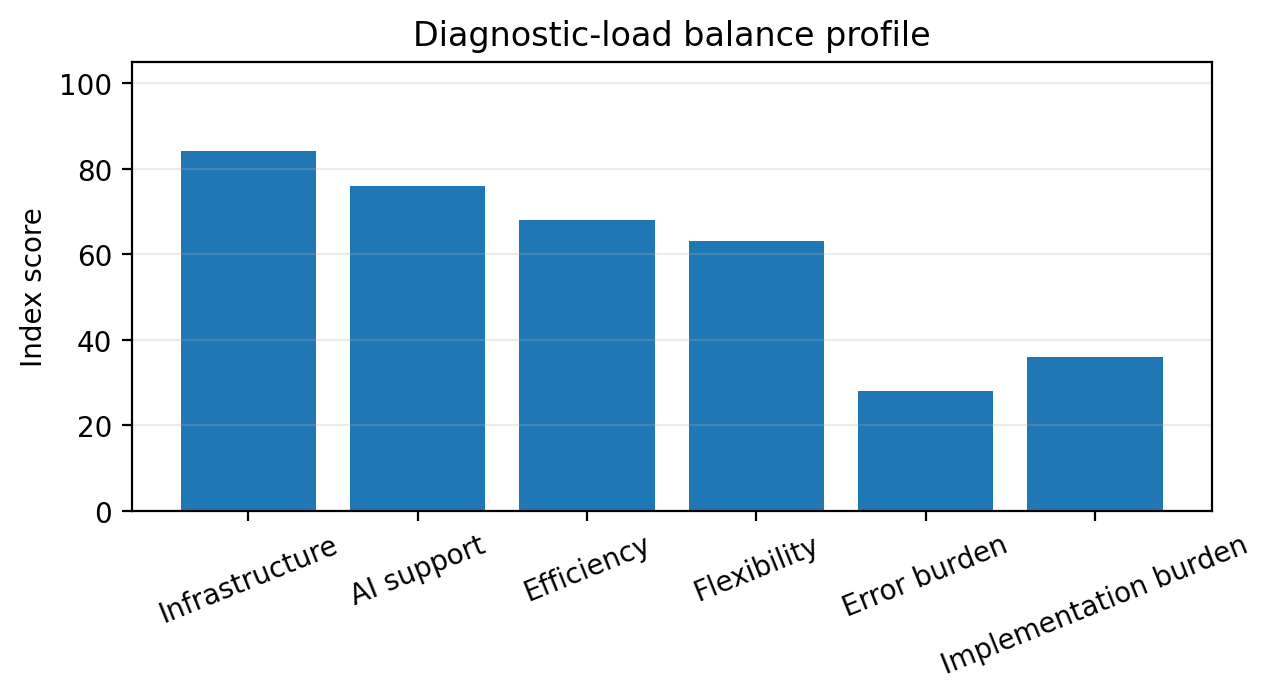
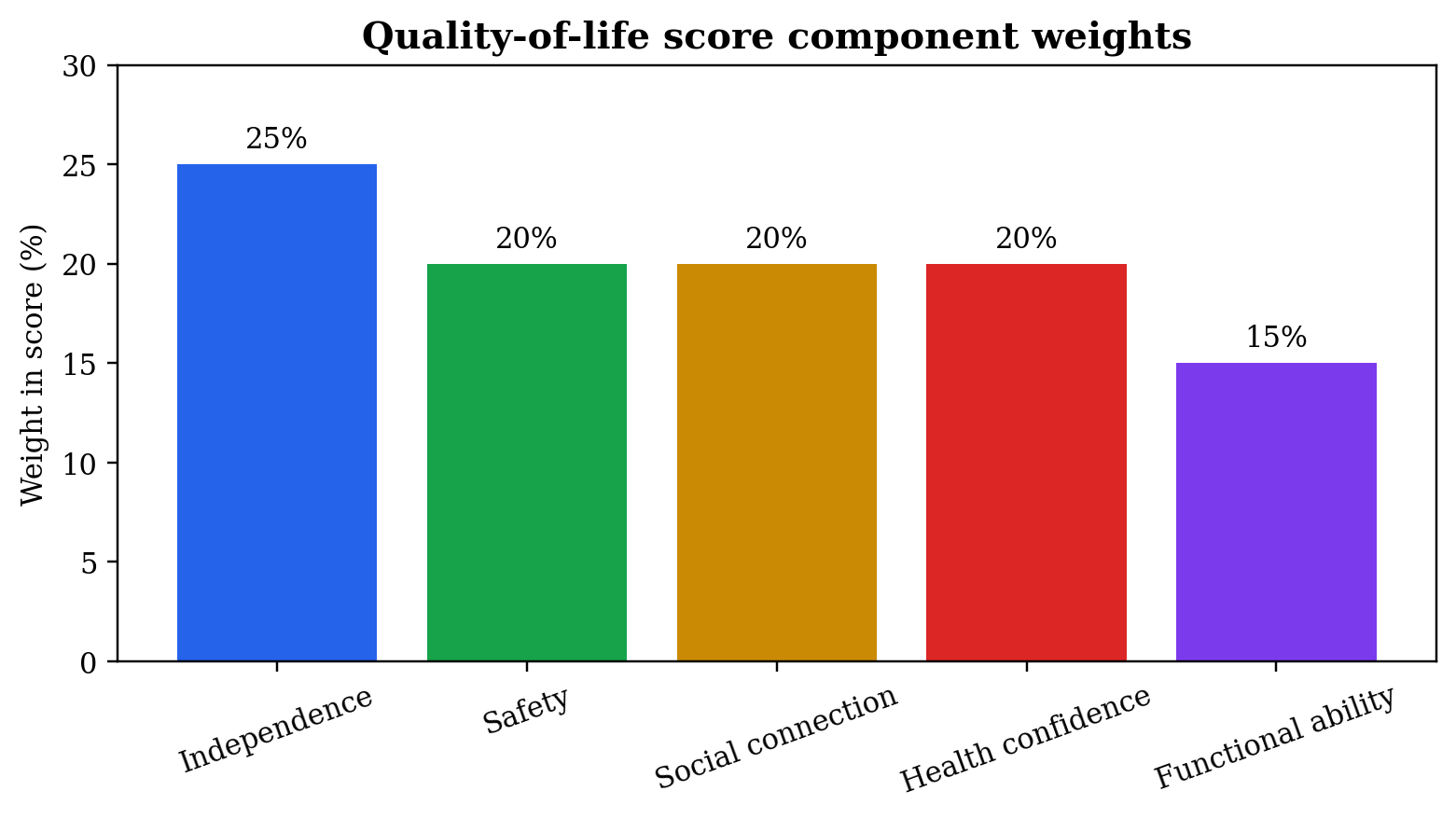
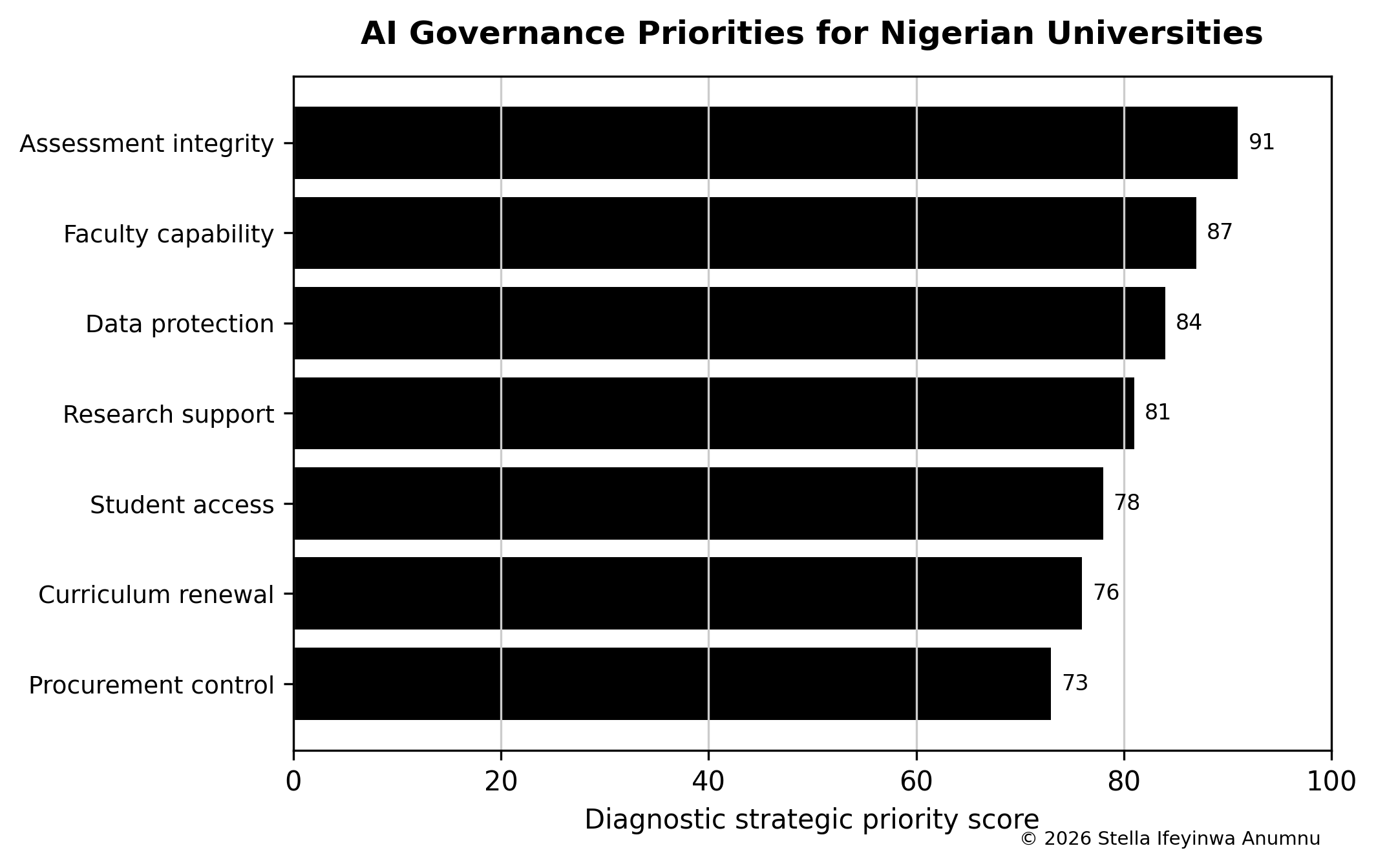
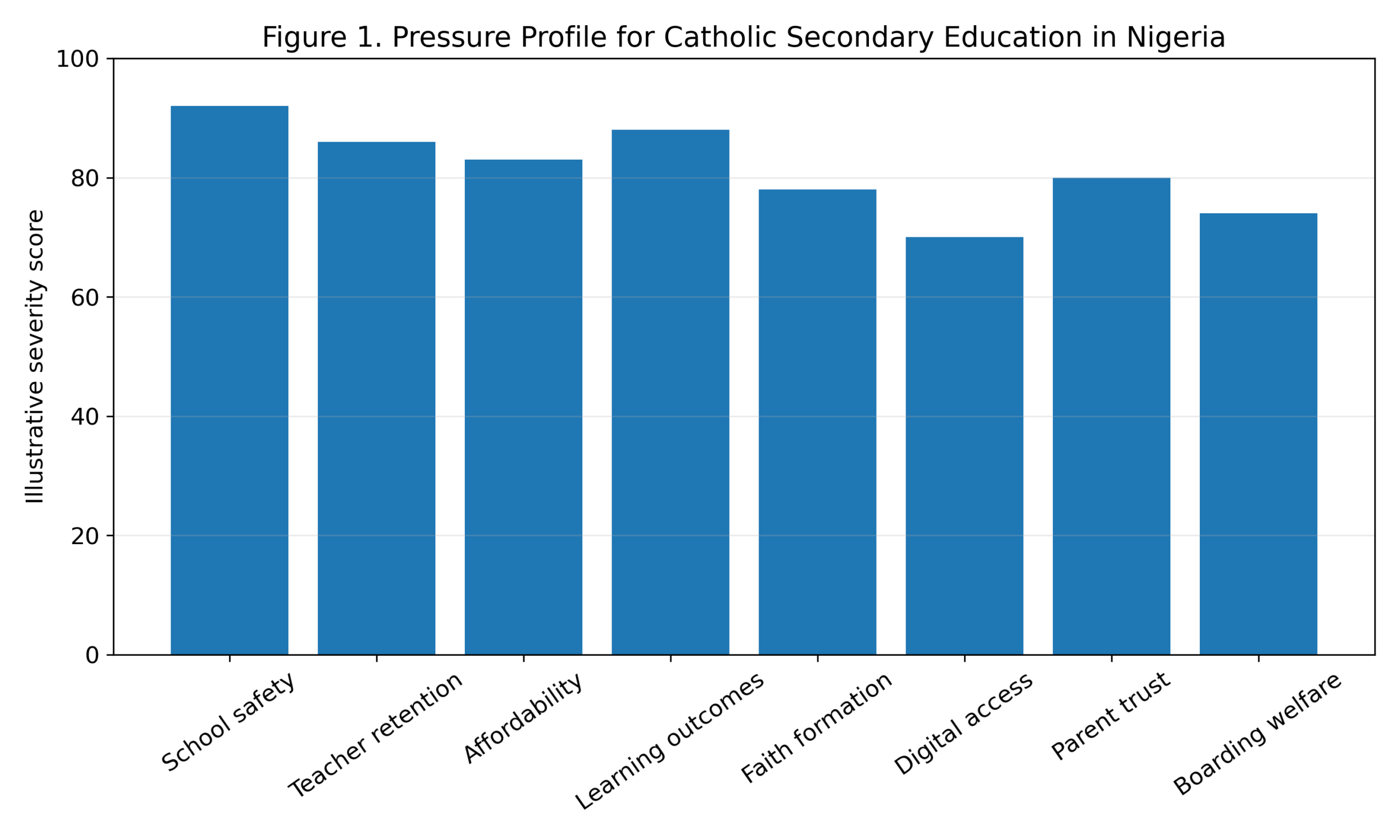
The Catholic Secondary School Success Index, abbreviated CSSSI, is a diagnostic tool for assessing whether a Catholic secondary school is strong across the domains that matter. The proposed formula is: CSSSI = 0.14MI + 0.16IQ + 0.13TS + 0.14SG + 0.11FD + 0.11SS + 0.08DU + 0.07FP + 0.06FR − 0.10CR. MI represents mission identity, IQ instructional quality, TS teacher stability, SG safeguarding, FD financial discipline, SS student support, DU data use, FP family partnership, FR facilities readiness, and CR contextual risk. Each component is scored from zero to one hundred.
The weight for instructional quality is highest because a school that does not teach well cannot defend its success with religious language. Mission identity and safeguarding are also heavily weighted because Catholic education has no credibility if formation is vague or children are unsafe. Teacher stability matters because learning quality and student culture depend on adults who remain long enough to know the school and its students. Contextual risk is subtracted because insecurity, severe poverty, infrastructure weakness, and local instability can reduce performance even when the school is well led.
The index should not be used for public ranking. It is an internal improvement tool. A school that scores low in student support should not be shamed; it should be helped. A school that scores high should not become complacent; it should inspect whether evidence supports the score. The point is to discipline conversation so that leaders stop relying only on reputation, anecdote, or examination results.
Table 2. Catholic Secondary School Success Index components.
| Component | Weight | Evidence question |
| Mission identity | 0.14 | Is Catholic formation visible in decisions, routines, discipline, service, and graduate expectations? |
| Instructional quality | 0.16 | Are students learning through strong teaching, feedback, assessment, and support? |
| Teacher stability | 0.13 | Can the school retain competent teachers and form them professionally? |
| Safeguarding | 0.14 | Are children protected through policy, training, supervision, and reporting? |
| Financial discipline | 0.11 | Does the budget support mission, salary reliability, scholarships, and maintenance? |
| Student support | 0.11 | Are adolescents supported through counseling, mentoring, chaplaincy, and welfare care? |
| Data use | 0.08 | Does leadership review reliable evidence rather than reputation alone? |
| Family partnership | 0.07 | Are parents treated as co-educators through clear communication and boundaries? |
| Facilities readiness | 0.06 | Are classrooms, boarding, laboratories, water, sanitation, and safety maintained? |
| Contextual risk (penalty) | −0.10 | Does scoring account for insecurity, severe poverty, infrastructure weakness, and local instability that can depress performance even under good leadership? |
Figure 2. Catholic Secondary School Success Index component weights.
3.3 Teacher Stability Risk Equation
Teacher stability can be estimated through a simple risk equation: TSR = SalaryStress + WorkloadPressure + FormationGap + LeadershipDistrust + HousingTransportBurden + CareerPathWeakness − MissionCommitment − ProfessionalSupport. A higher score indicates greater risk that teachers will leave, disengage, or perform below their ability. The equation reflects a practical truth: teacher turnover is rarely caused by money alone, though money matters.
A Catholic school that wants stable teachers should examine salary timing, workload, lesson preparation time, classroom resources, professional respect, principal feedback, spiritual formation, mentoring, and promotion possibilities. Teachers may remain in a school because they believe in the mission, but mission commitment should not be exploited. Catholic leadership must not demand sacrifice from teachers while avoiding fair employment practice.
This model is especially useful for diocesan education offices supervising multiple schools. If several schools report teacher instability, the problem may be systemic: salary bands, absence of teacher housing support, lack of induction, weak principal supervision, or poor professional formation. Treating each resignation as an individual problem hides institutional weakness.
3.4 Safeguarding and School-Safety Exposure Model
Safeguarding exposure can be modeled as SSE = ExternalThreat + StudentVulnerability + SupervisionGap + ReportingDelay + BoardingRisk + TransportRisk − ProtectiveControls − FormationQuality. The model is not a legal instrument. It helps school leaders think before harm occurs. In high-risk regions, external threat may dominate. In boarding schools, supervision and dormitory practice may be decisive. In day schools, transport and after-school movement may matter more.
Protective controls include trained safeguarding officers, written policies, background checks, visitor control, complaint channels, incident records, dormitory supervision, safe transport rules, emergency drills, and partnership with local security where necessary. Formation quality matters because adults and students must understand boundaries, dignity, reporting, and responsibility. A policy unknown to staff and students is weak protection.
The model should be reviewed at least once per term. Nigerian schools operate in changing conditions. A road that was safe last year may become risky. A boarding supervisor may leave. A new contractor may enter the campus. A student complaint may reveal a weak point. Successful school leadership treats safety as a living responsibility.
3.5 Learning Reliability Model
Learning reliability measures whether students are actually progressing, not only passing through the timetable. A possible model is LR = DiagnosticBaseline + TeachingQuality + FeedbackFrequency + RemediationIntensity + AssessmentIntegrity + ReadingSupport + NumeracySupport − PromotionPressure − ExamCramming. The negative terms matter. Promotion pressure and exam cramming can produce apparent progress while hiding weak understanding.
A Catholic school should establish baseline testing for new students, especially in reading, writing, and mathematics. It should track improvement by term, not only final grades. It should identify students at risk before external examinations. It should treat libraries, study halls, supervised prep, tutorial support, and teacher feedback as part of the learning system, not as decorations.
Assessment integrity is central. If internal assessments are too easy, copied, poorly marked, or inflated to satisfy parents, the school deceives itself. If assessments are punitive and unconnected to support, the school discourages weaker learners. The Catholic approach should be honest and remedial: tell the truth about performance, then help students improve.
3.6 Family Affordability Stress Score
Family affordability stress can be estimated as FASS = TuitionBurden + BoardingCost + TransportCost + ExaminationFees + UniformBookCost + EmergencyLevy − ScholarshipSupport − PaymentFlexibility − ParishAlumniAid. The model helps leaders see that fees are not the only cost. Parents may pay tuition but struggle with boarding supplies, transport, uniforms, textbooks, medical charges, or sudden levies.
A school should monitor fee arrears carefully without humiliating families. Patterns matter. If many good families are falling behind, the school should review cost design. If scholarship demand rises, the school should strengthen alumni giving, parish contributions, endowment planning, or targeted partnerships. A Catholic school that has no plan for affordability may slowly cease to be Catholic in social reach.
Payment flexibility must be governed. Informal arrangements made by private appeal can breed favoritism or confusion. A documented policy protects both families and school leaders. It allows compassion to be consistent rather than dependent on who knows whom.
3.7 Worked Example: Applying the Success Index
To show how the Catholic Secondary School Success Index works in practice, consider a hypothetical diocesan school scored by its leadership team across the ten domains, each rated from zero to one hundred. Suppose the school records mission identity at 78, instructional quality at 64, teacher stability at 55, safeguarding at 60, financial discipline at 70, student support at 52, data use at 40, family partnership at 66, facilities readiness at 58, and contextual risk at 65. These figures are illustrative, but they resemble the uneven profile many schools produce when they score themselves honestly rather than defensively, with reputation concentrated in a few visible domains and weakness hidden in the less visible ones.
Applying the weights gives the following contributions: mission identity 10.92, instructional quality 10.24, teacher stability 7.15, safeguarding 8.40, financial discipline 7.70, student support 5.72, data use 3.20, family partnership 4.62, and facilities readiness 3.48. These positive contributions sum to 61.43. The contextual-risk penalty, calculated as 0.10 multiplied by 65, removes 6.50 points. The resulting index is therefore 54.93, or roughly 55 on a scale where 100 would represent full strength across every domain with no contextual drag. Because the nine positive weights sum to one, the weighted positive total can never exceed 100, and the penalty term then expresses how much a hostile environment is pulling the school below its own internal performance.
The number itself matters less than what it exposes. The school’s reputation may rest on strong mission identity and sound finances, yet the index shows that data use, student support, and teacher stability are its weakest domains, and that a difficult local environment is subtracting meaningfully from its overall position. A leadership team reading this profile should resist both complacency and panic. The disciplined response is to choose three priorities, most plausibly data use, student support, and teacher stability, set measurable targets for each, and rescore after a defined period. Used this way, the index does not rank the school against others. It converts a vague sense that the school is doing well into a specific, improvable account of where mission is, and is not yet, visible in daily practice.
The example carries two cautions. The score is only as honest as the evidence behind each domain. If mission identity is rated 78 because the school has a chapel and a motto rather than because formation is documented in routines, service, and graduate expectations, the index will flatter the school and mislead its leaders. Each domain score should therefore be defended with the kind of evidence listed in the annual review checklist, not asserted from memory. The index is also most useful when it is repeated. A single score is a snapshot; a sequence of scores, gathered the same way each year, shows whether chosen priorities are actually moving and whether gains in one domain are quietly costing another. The discipline is not in producing a number but in returning to it, with the same seriousness, after the school has tried to improve.
Chapter 4: Case Studies and Nigerian Operating Lessons
Case studies in this chapter are used as practical school files. They are not advertisements and they are not evidence that one institution has solved all problems. Each case exposes a formation question relevant to Catholic secondary education in Nigeria: identity, formation, affordability, safe schooling, boarding, curriculum, and public trust.
The main Nigerian cases are Loyola Jesuit College Abuja, Jesuit Memorial College Port Harcourt, the Catholic Secretariat of Nigeria’s Education Summit, and the safe-schools policy environment. Comparative lessons are taken from the Cristo Rey model and Jesuit education’s graduate profile tradition. The goal is not to copy, but to learn what can be adapted.
4.1 Loyola Jesuit College Abuja
Loyola Jesuit College Abuja describes itself as a co-educational full boarding secondary school in the Jesuit tradition, opened with JSS 1 in 1996 and now serving students from JSS 1 to SSS 3, with supervision by Jesuits, the Sisters of the Holy Child Jesus, lay teachers, and staff (Loyola Jesuit College, n.d.). Several management lessons follow from that description. First, the school’s identity is not vague. It belongs to a tradition with defined educational habits. Second, boarding is treated as part of the school’s formation design, not only accommodation. Third, collaboration between religious and lay staff is built into the institutional description.
A Catholic school leader reading this case should resist superficial imitation. The lesson is not that every school must be full boarding or Jesuit. The lesson is that a successful Catholic school needs a recognizable educational tradition, disciplined supervision, and a shared adult culture. Students learn from routines as much as from classrooms. In a boarding school, routines include rising time, prayer, study, meals, recreation, hygiene, prep, dormitory order, counseling, liturgy, and supervised freedom.
The case also raises the question of scale. A school with a controlled enrollment can often preserve quality more easily than a school expanding without staff, facilities, or supervision. Nigerian Catholic schools under fee pressure may be tempted to increase intake beyond what their systems can carry. Successful leadership knows when growth threatens formation.
4.2 Jesuit Memorial College Port Harcourt
Jesuit Memorial College Port Harcourt presents itself around whole-person formation, faith, dialogue, curiosity, excellence, artistic expression, and service in the Ignatian tradition (Jesuit Memorial College, n.d.). That public language is significant because it refuses to reduce schooling to examination performance. A Catholic school should form mind, imagination, conscience, faith, and character together.
The practical lesson is that whole-person formation must be scheduled. Schools often say they educate the whole person while leaving arts, sports, counseling, service, and spiritual direction vulnerable to exam pressure. A truly Catholic timetable makes room for liturgy, formation, academic work, club life, sports, reading, service, and reflection. It also protects students from being treated as examination machines.
JMC’s public language of dialogue and reflection is also important in Nigeria’s plural society. Catholic secondary education should form students who can think, listen, disagree responsibly, and serve across religious and ethnic differences. Christian identity should deepen respect, not produce narrowness. Such formation must appear in classroom discussion, discipline, community service, and staff conduct.
4.3 Catholic Secretariat of Nigeria Education Summit
The Catholic Secretariat of Nigeria’s 2024 Education Summit was framed around the Global Compact on Education in the Nigerian context and included themes such as vulnerable persons in inclusive Catholic education, innovative funding, strategic partnerships, indigenous languages, artificial intelligence, digital division, and curriculum formulation (Nigeria Catholic Network, 2024). That agenda is valuable because it shows that Catholic education leaders in Nigeria are not unaware of the main pressures.
Summits, however, do not run schools. The practical question is what happens after the speeches. Diocesan education offices should translate summit themes into templates, training modules, finance guides, safeguarding checklists, scholarship models, language support plans, and digital readiness tools. A school principal facing fee arrears and teacher turnover needs more than a summit theme. He or she needs usable support.
The summit case points toward a national Catholic education data system. If dioceses and congregations collected comparable data on enrollment, fee arrears, scholarships, teacher retention, learning outcomes, safeguarding compliance, and examination performance, Church leadership could respond with better evidence. Without data, Catholic education planning remains dependent on isolated stories.
4.4 Safe Schools and Insecurity
Nigeria’s involvement in safe-school discussions matters because education has been directly affected by violence and school abductions. The Safe Schools Declaration commits states to protect education during armed conflict and restrict the military use of schools (Safe Schools Declaration, 2015). Catholic schools should read these materials not as government policy alone, but as practical guidance for their own risk planning.
The Catholic school safety question differs by region. A school in a high-risk zone may require perimeter security, transport coordination, emergency drills, risk communication, and close ties with local authorities. A school in a lower-risk area still needs safeguarding, visitor rules, medical response, fire safety, dormitory supervision, and data protection. All schools need a crisis communication plan that does not leave parents dependent on rumors.
Insecurity also affects learning indirectly. Parents may withdraw students, teachers may fear postings, boarding schools may face extra costs, and students may carry anxiety. Catholic schools should therefore integrate safety with pastoral care. A school that secures its gate but ignores students’ fear has not completed the task.
4.5 Cristo Rey and Affordability Imagination
The Cristo Rey Network in the United States uses a Catholic college-preparatory model in which students from families of limited means participate in structured work-study as part of the financing and formation of their education (Cristo Rey Network, n.d.). The model cannot simply be transplanted into Nigeria without legal, labor, cultural, and economic adaptation. Yet it challenges Nigerian Catholic schools to think more creatively about affordability and employability.
A Nigerian adaptation might not involve weekly corporate placements for all students. It could involve alumni-funded bursaries, supervised entrepreneurship projects, holiday internships for senior students, partnerships with Catholic hospitals and businesses, agricultural projects, technology clubs linked to local employers, or school-based enterprise that teaches responsibility without exploiting students. The deeper lesson is that affordability and formation can be connected if governed carefully.
Catholic schools should be careful here. Work-linked models must protect minors, avoid cheap labor, comply with law, preserve study time, and maintain dignity. But the idea that students can learn responsibility, workplace discipline, and social contribution while supporting access deserves serious thought in a country where many families struggle to pay fees.
Table 3. Case-study lessons for Nigerian Catholic secondary education.
| Case | Relevant lesson | Nigeria adaptation caution |
| Loyola Jesuit College Abuja | Clear Catholic tradition, boarding supervision, staff collaboration, and controlled learning environment | Not every school can copy its cost, scale, location, or boarding model |
| Jesuit Memorial College Port Harcourt | Whole-person formation through faith, dialogue, imagination, and excellence | Public language must become timetable, staffing, counseling, and assessment practice |
| CSN Education Summit | National Catholic attention to funding, vulnerable learners, indigenous languages, and digital division | Summit themes must become templates, training, and diocesan follow-up |
| Safe Schools Declaration | Protection of education requires preparation, risk review, and continuity planning | Security practice must be localized by region and school type |
| Cristo Rey Network | Affordability can be joined to work exposure and career formation | Any Nigerian adaptation must protect minors and comply with law |
Chapter 5: Formation-Centered Governance for Catholic Secondary Education
Running a successful Catholic secondary school in Nigeria requires more than a good principal. It requires a way of working that survives examination seasons, fee pressure, staff changes, security incidents, parent demands, and adolescent crises. The school must know what it is trying to form, how it will teach, how it will protect students, how it will pay teachers, how it will inspect learning, and how it will tell the truth about weakness.
This chapter sets out the practical domains of a successful school. They should be reviewed together because weakness in one area travels into others. Poor finance affects teacher stability. Teacher instability affects learning. Weak safeguarding damages trust. Weak parent communication increases conflict. Poor facilities affect safety. Weak Catholic identity turns the school into a private exam center.
5.1 Mission Identity That Can Be Observed
Catholic identity must be visible in more than names, statues, uniforms, and prayer routines. It should appear in how teachers treat weaker students, how discipline is handled, how fees are discussed, how students serve the poor, how staff are formed, how leaders speak when mistakes occur, and how the school handles truth. A chapel on campus is important, but the whole school must learn to live from what the chapel signifies.
A school should define its graduate profile. By graduation, what should a Catholic secondary school student know, love, practice, and resist? The answer should include academic competence, moral judgment, prayerful awareness, respect for human dignity, civic responsibility, digital prudence, service, and resilience. Jesuit education’s graduate profile tradition, often summarized around growth, intellectual competence, faith, love, and justice, offers one useful example of such specificity (Jesuit Schools Network, n.d.).
Mission review should be part of the school year. Leaders can ask: Are students participating meaningfully in liturgy and service? Are teachers able to explain the school’s Catholic purpose? Are discipline records consistent with human dignity? Are poorer students visible? Does the school’s academic culture form honesty, or does it tolerate cheating because results matter? Mission becomes credible when it can answer these questions.
5.2 Instructional Quality and Academic Reliability
A Catholic secondary school cannot call itself successful if teaching is weak. Academic reliability begins with teacher mastery, lesson preparation, use of textbooks and laboratories, feedback, homework design, reading culture, and honest assessment. External examination results matter, but they should not be the only evidence. A school can produce high results through selection and pressure while failing to develop ordinary learners.
Leaders should conduct lesson observations not to intimidate teachers but to protect learning. Observations should ask whether objectives are clear, explanation is strong, students are thinking, notes are meaningful, questions reveal understanding, and feedback reaches weak learners. Departmental meetings should review student work, not only cover schemes. A mathematics department should know which topics students are failing and why. An English department should know whether students can write a coherent argument.
The school should avoid two extremes. One is harsh academic pressure that treats students as results. The other is sentimental tolerance of poor performance. A Catholic school should be demanding and supportive. It should tell students the truth about their work and give them structured help to improve.
5.3 Teacher Recruitment and Formation
Teacher recruitment should test competence, character, communication, and teachability. A Catholic school should not hire only because a teacher is available, cheap, or recommended by a familiar person. Recruitment is a mission decision. The wrong teacher can damage learning, discipline, safeguarding, and the moral tone of the school.
Induction matters. New teachers should be introduced to the school’s Catholic identity, safeguarding rules, assessment standards, classroom expectations, communication norms, and student support process. They should know how discipline is handled, where to report concerns, how to use data, and how to seek help. Too many schools assume teachers will learn the culture by observation. That is unreliable.
Formation should continue. Monthly professional sessions, departmental coaching, peer observation, retreat days, child protection training, digital skills, and leadership development can sustain teacher quality. Catholic schools should not rely on fear to manage teachers. They should rely on clear standards, feedback, fair correction, and community.
5.4 Student Support and Adolescent Formation
Secondary school students are adolescents, not small adults. They carry academic pressure, emotional change, peer influence, family expectation, sexuality questions, faith questions, anxiety, social media exposure, and sometimes trauma. A Catholic school that treats every adolescent struggle as indiscipline will miss serious needs. Student support should include counseling, chaplaincy, mentoring, health services, study support, and clear referral pathways.
Boarding schools need particular care. Students living away from home require trusted adults, dormitory routines, privacy, medical response, recreation, and channels for raising concerns. Dormitories should not become hidden spaces where bullying, humiliation, or neglect are normalized. The boarding master or mistress is not only a supervisor. That role carries pastoral and safeguarding weight.
Student voice should be managed responsibly. Students should have ways to speak about learning, welfare, bullying, food, facilities, and spiritual life. Listening to students does not mean surrendering authority. It means that adults do not rely on assumptions about what students experience.
5.5 Finance and Resource Discipline
Financial discipline begins with knowing the real cost of running the school. Salaries, utilities, boarding food, security, laboratory supplies, library resources, maintenance, taxes, technology, examination costs, insurance where applicable, staff formation, scholarships, and emergency reserves should be visible. A school that sets fees by guesswork or crisis will eventually injure trust.
Budgeting should be mission-linked. If Catholic identity is a priority, formation and chaplaincy need resources. If safeguarding is a priority, training and systems need resources. If science education is a priority, laboratories need resources. If the poor are part of the mission, scholarships need resources. Budgets reveal whether mission language is serious.
The school should publish appropriate financial information to its board and proprietor and communicate fee policies respectfully to parents. Parents do not need every internal detail, but they deserve clarity about why costs exist and how the school uses resources. Secrecy around fees produces suspicion. Transparency, even when painful, strengthens trust.
5.6 Parent Partnership and Community Trust
Parents are not customers in a simple market sense. They are co-educators, fee supporters, advocates, critics, and partners in formation. The Catholic school should avoid treating parents either as threats or as people whose demands must always be satisfied. Parent partnership requires clear boundaries and genuine communication.
Communication should be planned. Parents should receive academic reports that tell the truth, welfare updates when necessary, fee communication that is respectful, safeguarding information, digital-use policies, and guidance on supporting study at home. Parent meetings should not be ceremonial. They should include evidence about learning, discipline, spiritual formation, and school priorities.
Alumni and parish communities also matter. Alumni can support scholarships, mentoring, career talks, libraries, laboratories, and infrastructure. Parish communities can support poorer students, chaplaincy, and moral formation. A Catholic secondary school should not behave as if it belongs only to fee-paying families. It belongs to the wider mission of the Church.
Chapter 6: Staged Renewal Plan for Nigerian Catholic Secondary Schools
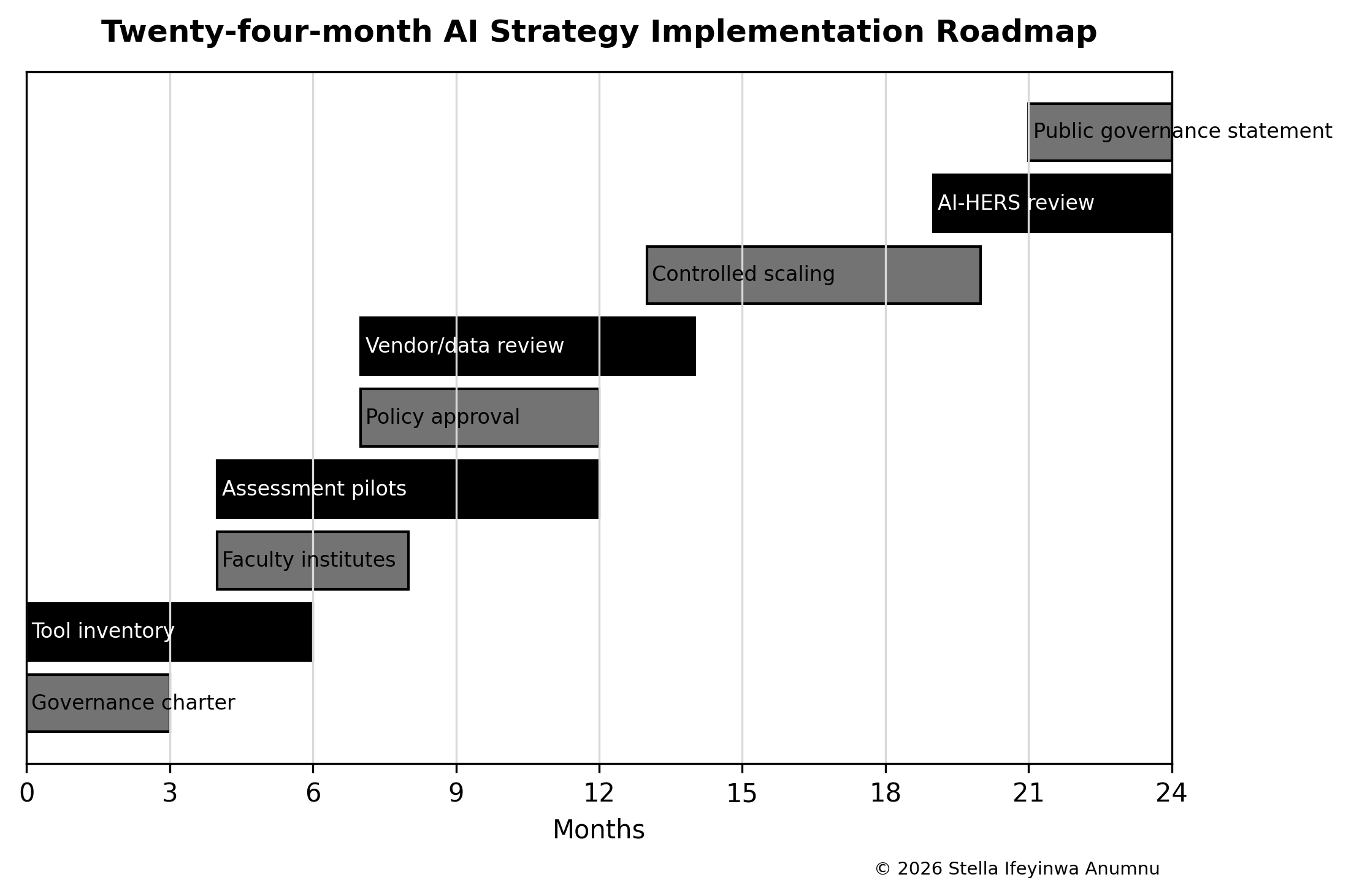
Successful reform fails when leaders try to fix everything at once. Catholic school improvement should be sequenced. The first task is to stabilize what is unsafe or unreliable. The second is to standardize essential routines. The third is to strengthen teaching and formation. The fourth is to scale the practices that work across diocesan or congregation-owned school networks.
This chapter proposes a three-year plan. It is not rigid. Schools should adapt it to size, location, resources, and risk. The principle remains: do fewer things seriously, review evidence, and move only when the school can carry the next step.
6.1 Opening 100 Days: Stabilize the School
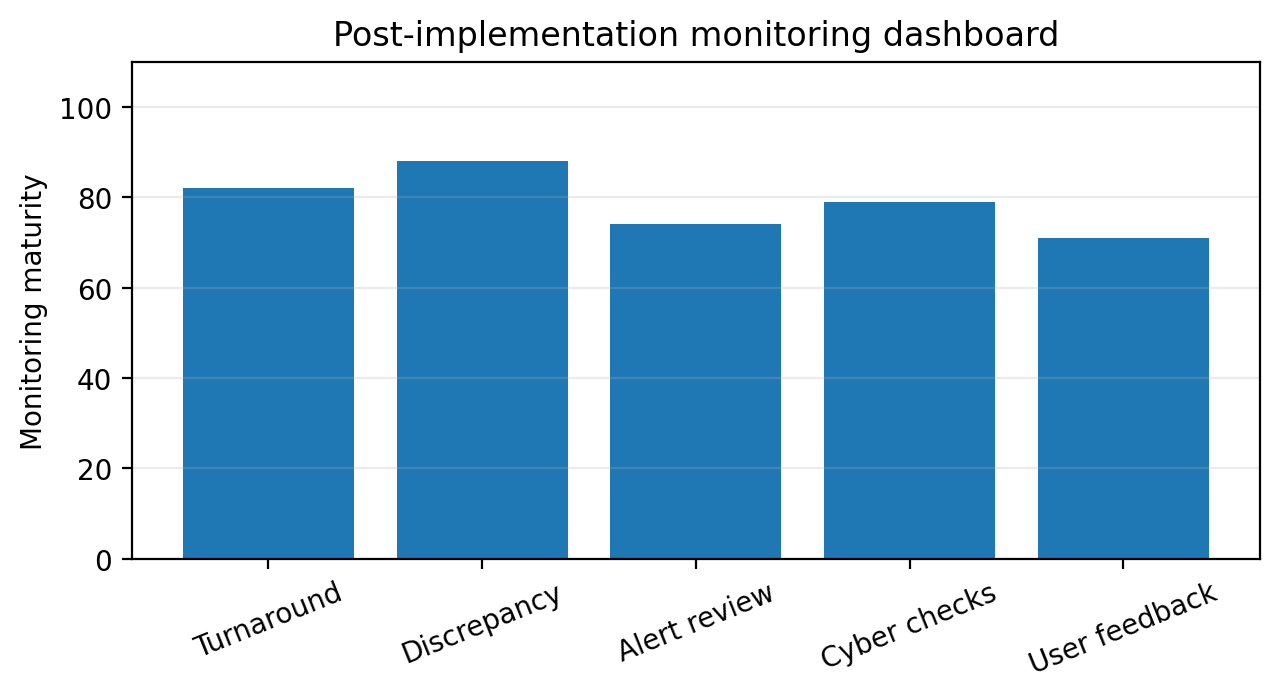
The first 100 days should focus on safety, data, finance, and immediate teaching risks. Leaders should review safeguarding policies, emergency contacts, visitor control, dormitory supervision, transport rules, teacher attendance, fee arrears, student enrollment, examination classes, and facility hazards. The purpose is not to produce a glossy plan. The purpose is to identify risks that can harm students or cripple the school.
A simple school diagnostic should be completed. How many teachers are full time? Which subjects have staffing gaps? Which students are failing more than one core subject? Which families are in serious arrears? Which dormitories or classrooms need urgent repair? Are safeguarding officers trained? Are incident records kept? Does the school have emergency communication with parents? These questions should be answered before leaders announce major reforms.
The first 100 days should also set a new tone. Leaders should explain that improvement will be evidence-based and humane. Teachers should not be blamed for every weakness, but they should know that standards matter. Parents should be respected, but they should know that the school will not be managed by pressure alone. Students should see that discipline and care can exist together.
6.2 Opening Year: Standardize Essential Practice
During the first year, the school should standardize lesson planning, assessment, safeguarding records, staff appraisal, parent communication, fee policy, scholarship process, and boarding supervision. Standardization does not mean rigidity. It means that essential practices do not depend on individual mood. A student should not receive a different level of safety or teaching quality because of which adult happens to be present.
Departments should develop termly learning reviews. Each department should identify weak topics, strong topics, students needing support, and teachers needing coaching. The principal should meet department heads with evidence. This is not a witch hunt. It is professional practice. Learning improves when teachers and leaders look at actual student work.
Safeguarding training should become annual. Every adult on campus, including non-teaching staff, should understand boundaries, reporting, visitor rules, and student dignity. Students should know how to report concerns. Parents should know whom to contact. The school should record and review incidents without panic or concealment.
6.3 Years Two and Three: Strengthen and Scale
The second year should deepen academic support, teacher formation, scholarships, alumni engagement, digital records, and student mentoring. The school should begin to see patterns: which subjects improve, which teachers need support, which students benefit from remediation, which families need financial planning, and which routines are working. Leaders can then invest more confidently.
By the third year, the school should be able to scale what works. A diocese or congregation can use data from one school to help another. A strong science teaching routine can be shared. A safeguarding template can become common. A scholarship fund can be widened. Teacher formation can be organized across a network. Success should not remain trapped in one school.
Scaling should remain humble. A practice that works in Abuja may need adaptation in a rural state. A boarding routine that works in one congregation’s school may not fit a day school. The principle is adaptation with evidence, not copying with pride.
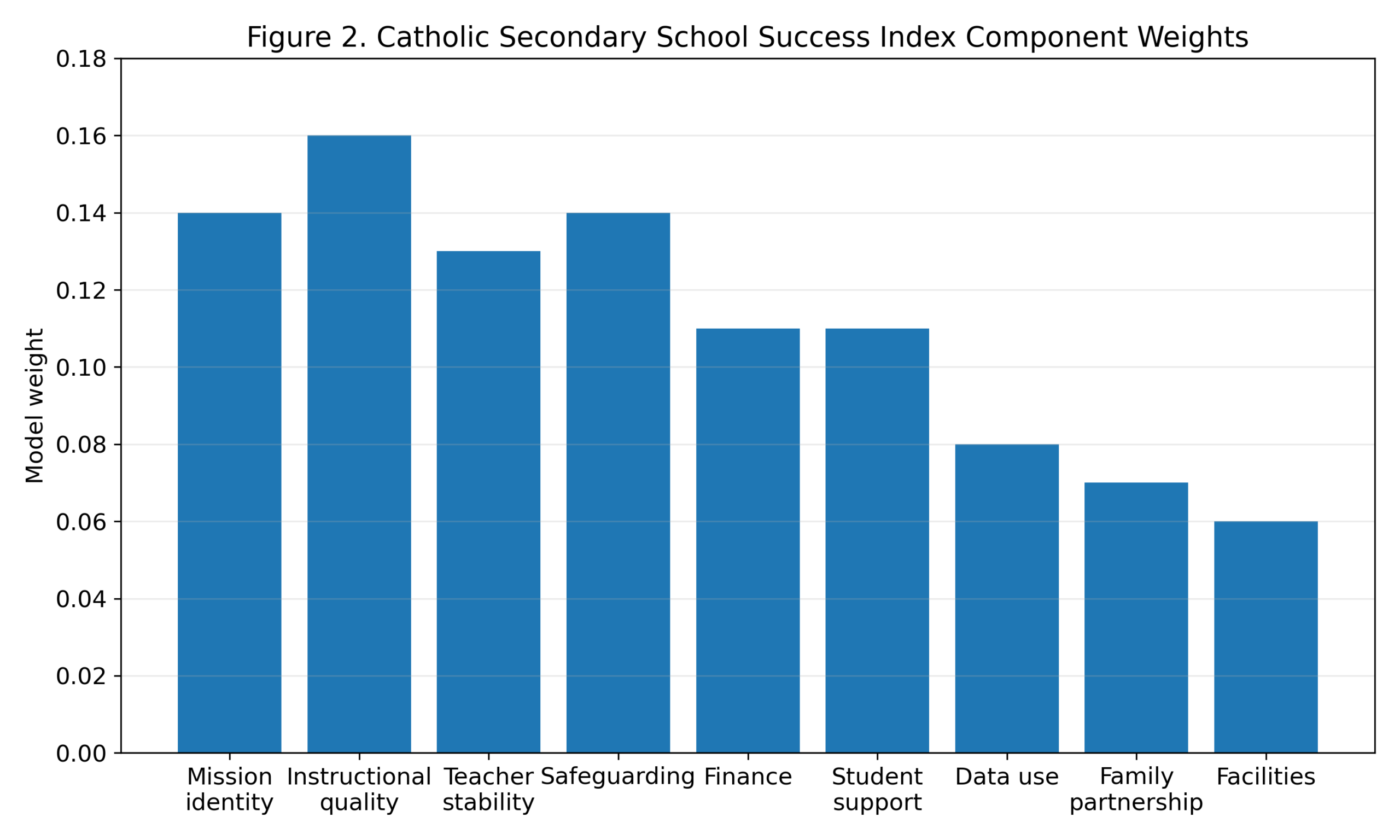
Figure 3. Intervention priorities by urgency and management controllability.
Table 4. Three-year implementation sequence.
| Period | Main work | Evidence to review | Avoid |
| 0–3 months | Safety, data, finance, teacher and examination risk review | Risk log, staff list, arrears, student baseline, urgent facilities | Announcing broad reform without evidence |
| 4–9 months | Standardize lesson planning, safeguarding, parent communication, appraisal | Department reviews, incident records, parent responses, teacher feedback | Creating paperwork that does not change practice |
| 10–18 months | Strengthen remediation, teacher formation, counseling, alumni support | Learning growth, retention, scholarship use, student voice | Scaling weak routines |
| 19–36 months | Share effective practice across schools and deepen mission access | Network data, bursary reports, inspection summaries, training outcomes | Copying without adaptation |
6.4 Diocesan and Proprietor Responsibilities
No Catholic secondary school should be left alone to carry every burden. Dioceses, religious congregations, and proprietors should provide policy support, leadership formation, finance guidance, safeguarding oversight, teacher development, and periodic review. If the proprietor only collects reports or intervenes during crisis, governance is too thin.
Diocesan education offices should collect basic comparable data from Catholic schools: enrollment, fees, scholarships, teacher turnover, examination results, safeguarding compliance, infrastructure risks, and student welfare indicators. This data should be used for support, not mere control. Schools should see the education office as a source of seriousness and help.
Proprietors should also protect principals. A principal asked to run a school without authority over staffing, fees, discipline, safety, or budget is being set up to fail. Responsibility and authority must match. If a principal is accountable for outcomes, the principal must have enough room to manage.
Chapter 7: Discussion
The preceding chapters show that Catholic secondary education in Nigeria succeeds when its parts reinforce one another. The school’s Catholic identity must be tied to instruction. Instruction must be tied to teacher formation. Teacher formation must be tied to finance. Finance must be tied to affordability. Safeguarding must be tied to governance. Parent trust must be tied to communication. None of these domains can be treated as decorative.
The strongest schools are not those with the loudest claims. They are those that can show evidence: students learning, teachers staying, vulnerable students protected, parents informed, finances reviewed, discipline humane, and mission visible in daily routines. This is why Catholic school stewardship is a pastoral responsibility.
7.1 Examination Success Is Not Enough
Nigeria’s school culture often rewards examination success above every other measure. WAEC and NECO results matter because they influence university access, family pride, and public reputation. A Catholic secondary school should take them seriously. But examination success can become dangerous when it becomes the only public measure of school quality.
A school may achieve strong results through selection, expulsion of weaker students, exam-focused cramming, excessive pressure, or parental tutoring. Such results may impress outsiders while hiding the school’s actual contribution. Catholic schools should ask a deeper question: how much did students grow because of the school? Value added matters. A child entering with weak reading who becomes confident and disciplined is a major success, even if that achievement does not appear in a ranking table.
Academic excellence should therefore be joined to formation. Students should learn to study honestly, write clearly, reason morally, serve generously, pray sincerely, and respect difference. The Catholic graduate should not be only admitted to university. The graduate should be prepared to live as a responsible Christian and citizen.
7.2 The Affordability Dilemma
Affordability is one of the hardest questions because there are no painless answers. High-quality schooling costs money. Low fees without subsidies can lead to unpaid teachers, poor facilities, weak security, and false economy. High fees without scholarships can turn Catholic education into a service for the comfortable. Both outcomes are dangerous.
The scale of household pressure is not a matter of impression. The National Bureau of Statistics found that about 63 percent of people in Nigeria, some 133 million, were multidimensionally poor, with deprivation markedly higher in rural areas than in cities and with children carrying the heaviest burden (National Bureau of Statistics, 2022). A school that sets fees without reckoning with this reality is not being prudent; it is quietly selecting which families it will serve. Catholic leaders should therefore treat affordability data as governance information, reviewing arrears patterns, scholarship demand, and the social profile of new intakes alongside academic results, so that the question of who can still afford the school is answered with evidence rather than assumption.
The way forward is financial truth. Schools should know their costs, publish clear fee policies, raise funds with integrity, build scholarships, and manage expenses carefully. Dioceses should help schools create bursary funds and alumni networks. Wealthier Catholic schools should consider solidarity arrangements with poorer mission schools, especially in teacher formation and learning resources.
The poor should not be used only in speeches. If they are part of Catholic education’s mission, they must appear in budgets, admissions, scholarships, partnerships, and planning. Otherwise, the school’s identity becomes socially narrow.
7.3 Catholic Identity and Plural Nigeria
Nigeria’s religious and ethnic diversity requires Catholic schools to form students who are firm in faith and respectful in society. Catholic identity should not mean hostility toward others. It should give students a deeper reason to respect human dignity, pursue justice, and serve across difference. In a country marked by religious tension, this formation is not optional.
The Vatican’s emphasis on dialogue in Catholic school identity is important here (Congregation for Catholic Education, 2022). Dialogue does not weaken Catholic identity. It allows students to practice truth with charity. A Catholic school that forms students to think, listen, and serve can contribute to national peace more effectively than a school that only produces high examination scores.
Religious formation should be intellectually serious. Students should learn Scripture, doctrine, Catholic social teaching, moral reasoning, prayer, and service. They should also be helped to confront corruption, tribalism, violence, materialism, sexual pressure, digital harm, and ecological neglect. A Catholic school must speak to the world students actually inhabit.
7.4 Data Without Dehumanization
The models proposed in this paper require data, but Catholic schools must handle data carefully. Students are not scores. Teachers are not retention units. Families are not arrears categories. Data should help leaders see persons more clearly, not reduce them to files.
A school should collect data on attendance, grades, reading growth, behavior incidents, safeguarding concerns, scholarships, teacher turnover, and parent communication. It should also listen to students and teachers. Numbers can show patterns; human conversation explains meaning. A student’s repeated lateness may reflect indiscipline, transport failure, family poverty, or anxiety. Management must investigate before judging.
Data should be confidential, truthful, and used for improvement. If teachers learn that data will only be used to punish, they may hide weakness. If parents learn that data will be used to shame children, trust will collapse. Catholic school data practice should be honest and merciful.
7.5 The Principal as Mission Executor
The principal is the daily custodian of school culture. Bishops, proprietors, and boards may set direction, but the principal translates direction into timetable, staffing, discipline, meetings, parent communication, academic review, and student welfare. A weak principal can damage even a strong school tradition. A strong principal can stabilize a school under difficult conditions.
Principal formation should therefore be deliberate. Catholic principals need preparation in theology of education, school finance, safeguarding, curriculum, teacher supervision, adolescent formation, conflict management, data use, parent relations, and public communication. They also need spiritual support. The role can become lonely, especially when parents, teachers, students, and proprietors all expect different things.
A successful principal is not only strict. Strictness without wisdom breeds fear. A successful principal is clear, fair, evidence-conscious, pastoral, and courageous enough to make unpopular decisions when student welfare or mission requires it.
Chapter 8: Recommendations
Recommendations must be practical because Catholic school leaders do not need decorative advice. They need steps that can survive actual school conditions. The following recommendations are intended for schools, diocesan education offices, religious congregations, boards, parent bodies, alumni groups, and policymakers willing to support Catholic secondary education seriously.
The recommendations should be implemented in sequence. A school that tries to launch every reform at once may produce fatigue. Each school should begin with its most serious risk and its most realistic improvement path.
8.1 For Catholic School Proprietors
Proprietors should establish minimum standards for Catholic secondary schools under their authority. These should include safeguarding policy, teacher induction, annual financial review, school board terms of reference, academic review, student support, and emergency planning. Minimum standards protect the mission from uneven local practice.
Proprietors should also conduct annual school visitations that examine evidence, not appearances. The visitation team should review classrooms, records, safeguarding files, dormitories, fee policy, staff morale, student voice, parent communication, and academic data. A short narrative report should follow each visit, with three agreed improvement actions.
A diocesan or congregation-wide teacher formation program should be created. Small schools may not have the resources to train teachers alone. Shared formation can reduce cost and strengthen identity. It can also build a Catholic teacher community across schools.
Proprietors should also hold their schools accountable for who they are reaching, not only for the results they post. In a country where roughly two-thirds of people are multidimensionally poor and children bear the heaviest share of that deprivation, a Catholic school that drifts toward serving only families who can comfortably pay has quietly narrowed its mission (National Bureau of Statistics, 2022). Proprietors should require each school to report the social profile of its intake, the size and use of its scholarship or bursary provision, and its arrears patterns, and should fund a modest cross-school solidarity arrangement so that mission access does not depend entirely on the wealth of a particular school’s catchment. Affordability handled this way becomes a governed commitment rather than an occasional act of charity.
8.2 For Principals and School Boards
Principals and boards should adopt the CSSSI model as an annual self-review tool. The review should be evidence-based. Each component should be scored with documents, data, and discussion. The school should then select three priorities for the year, assign responsible persons, and set review dates.
Boards should receive training. Many board members are willing but unclear about their duties. They need to understand finance, safeguarding, academic data, confidentiality, school mission, and oversight boundaries. A board that does not understand its role can either interfere too much or contribute too little.
Principals should establish a weekly leadership rhythm. This may include academic review, welfare review, finance review, operations review, and mission review. The rhythm should be light enough to sustain and strong enough to prevent drift. Schools fail when important matters are noticed only after they become crises.
8.3 For Teachers and Formation Teams
Teachers should receive structured induction into Catholic education. This should include the school’s mission, child protection, assessment standards, classroom management, student dignity, digital conduct, and professional expectations. New teachers should be mentored for at least one term.
Departments should meet with student work, not only lesson notes. Teachers should review scripts, assignments, projects, and test performance together. This practice turns professional development into school reality. It also helps younger teachers learn from stronger colleagues.
Formation teams should include chaplains, counselors, senior teachers, and student leaders where appropriate. Faith formation should not be confined to Mass and morning prayer. It should include service, reflection, moral conversation, vocation awareness, and care for the poor.
Formation cannot substitute for retention. With national analyses pointing to chronic teacher shortages, high pupil-to-teacher ratios, and recurring failures to recruit, Catholic schools should treat the conditions that keep good teachers as a managed priority rather than an afterthought (Athena Centre for Policy and Leadership, 2025). That means predictable and timely salaries, reasonable workloads, induction for new staff, mentoring, and a visible path for advancement, so that the teachers a school has formed are not steadily lost to better-resourced employers.
8.4 For Parents, Alumni, and Parish Communities
Parents should be treated as partners in formation. Schools should communicate clearly about academic expectations, discipline, safeguarding, digital use, fees, and student welfare. Parents should also be invited to support reading culture, career exposure, scholarship funds, and moral formation at home.
Alumni should be organized beyond reunion events. They can support mentorship, scholarships, laboratories, career talks, internships, libraries, and school improvement. A strong alumni network can become one of the most important resources for sustaining Catholic education under financial pressure.
Parish communities should reconnect with schools. Catholic secondary schools should not become isolated fee-paying enclaves. Parishes can support poorer students, provide pastoral presence, encourage vocations, and integrate students into service. This relationship should be organized, not sentimental.
8.5 For Policymakers and Public Authorities
Public authorities should recognize the contribution of Catholic schools to national education and social development. Non-state schools are part of Nigeria’s education reality. Where regulation is needed, it should be clear and fair. Where collaboration is possible, it should support teacher development, school safety, curriculum improvement, and child protection.
Government and security agencies should strengthen safe-school measures, especially in areas vulnerable to attack or kidnapping. Catholic schools cannot carry national security alone. They need timely information, emergency coordination, and credible protection. School safety is a public good.
A practical first step is alignment with existing national instruments rather than the creation of parallel systems. The National Policy on Safety, Security and Violence-Free Schools already defines minimum expectations for prevention, supervision, reporting, and response, and Catholic proprietors and boards should adopt it as the baseline against which each school’s safeguarding arrangements are audited and improved (Federal Ministry of Education, 2021). Where dioceses run several schools, a common safeguarding standard built on this policy would protect students more reliably than school-by-school improvisation and would make weak points easier to detect before harm occurs.
Policy should also support scholarships, tax incentives for educational philanthropy, teacher development partnerships, and digital inclusion. If Catholic schools are expected to contribute to national development, the policy environment should not treat them only as fee-paying private entities.
Figure 4. Three-year Catholic secondary school improvement sequence.
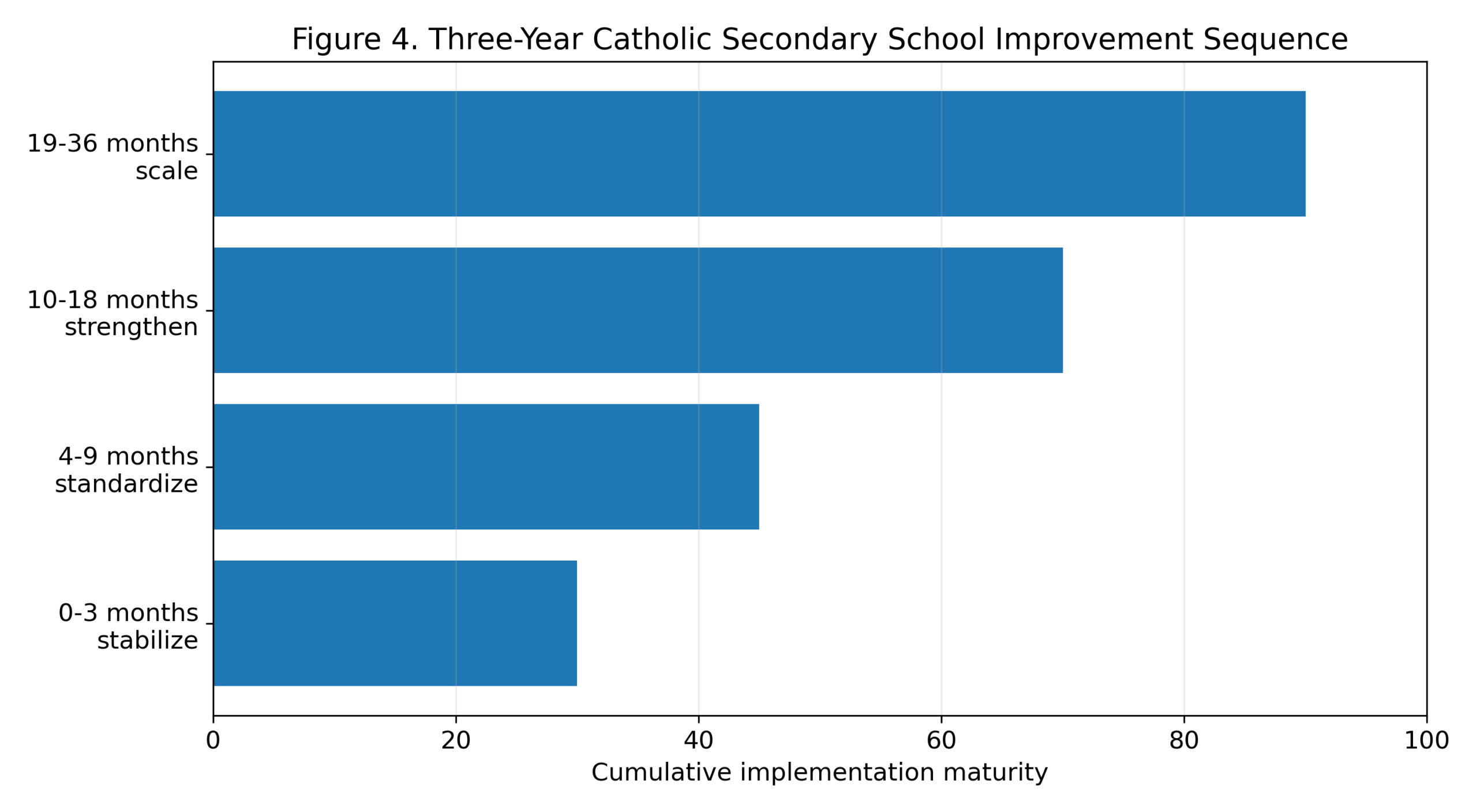
Chapter 9: Conclusion
Catholic secondary education in Nigeria can succeed, but only if success is defined with enough seriousness. A school that forms faith without intellectual quality is incomplete. A school that produces high scores without moral formation is incomplete. A school that is safe but unaffordable has narrowed its mission. A school that is affordable but poorly managed has betrayed families in another way. Catholic success requires a difficult balance.
This research has argued that the balance can be managed. It requires mission clarity, instructional reliability, teacher formation, safeguarding, financial discipline, student support, data use, family partnership, facilities readiness, and contextual risk awareness. These are not secular distractions from Catholic education. They are the means through which Catholic education becomes trustworthy.
9.1 Final Professional Judgment
The future of Catholic secondary education in Nigeria will not be protected by nostalgia. It will be protected by schools that can teach well, govern honestly, protect students, support teachers, serve poorer families, and form graduates who can carry conscience into Nigerian public life. The Church does not need schools that only look respectable. It needs schools that can be trusted.
Running such schools is difficult. It requires money, skill, prayer, planning, courage, and humility. Yet the difficulty is exactly why the work matters. In a country where many children are outside school or inside weak schools, a serious Catholic secondary school becomes more than a private institution. It becomes a public witness that education can still form the person, serve the nation, and honor God through competent care.
The diagnostic tools offered in this research are means to that end, not ends in themselves. A success index, a teacher-stability estimate, a safeguarding exposure model, a learning-reliability measure, and an affordability score are useful only if they make leaders look honestly at what they would otherwise prefer not to see, and only if they prompt action that protects students and supports teachers. A school may score itself, debate the results, and still fail its students if nothing changes afterward. The final judgment, therefore, is practical rather than ceremonial: a Catholic secondary school in Nigeria is succeeding when its mission can be observed in the ordinary evidence of classrooms, records, dormitories, and budgets, and when the families who entrust their children to it have good reason for that trust.
Chapter 10: Practical Formation Standards for Catholic Secondary Schools
The preceding model becomes useful only when it reaches ordinary school operations. Catholic school failure is often hidden inside small routines that no one reviews carefully: admissions interviews, dormitory supervision, prep time, lesson notes, fee follow-up, examination registration, staff duty rosters, sickbay records, and parent complaints. Good governance should reach these places without suffocating them. This chapter translates the argument into practical playbooks that a Nigerian Catholic secondary school can adapt by size, location, and resources.
The playbooks are not meant to replace local policy. They are prompts for disciplined review. A school may already be strong in some areas and weak in others. The point is to help leaders inspect daily practice with enough patience to see what is actually happening. Catholic education becomes credible in the repetition of good routines.
10.1 Admissions, Equity, and Student Fit
Admissions should not be treated only as a test of who can score high enough or pay quickly enough. A Catholic secondary school should ask whether the student can benefit from the school, whether the school can support the student, and whether admission practice is consistent with mission. Screening is legitimate; exclusion without pastoral thought is not. A school may need entrance tests, interviews, previous records, and parent meetings, but these should be interpreted with caution because many Nigerian children arrive from unequal primary school backgrounds.
An admissions process should include academic baseline, family conversation, health information, boarding readiness where applicable, safeguarding documentation, and financial clarity. It should also include some form of scholarship review before the school year begins. If scholarships are handled only after parents plead, the school will favor families with confidence and access. A written process gives poorer families a fairer chance.
Student fit should not be confused with social polish. A shy rural student, a student from a low-income home, or a student with weak spoken English may still become one of the school’s strongest graduates if supported properly. Catholic education should be careful not to mistake privilege for promise. Admissions should protect standards while leaving room for grace, growth, and social mission.
10.2 Boarding, Food, Health, and Daily Supervision
Boarding is one of the most demanding forms of Catholic school trust. Parents hand over not only academic instruction but daily living. The school becomes responsible for sleep, hygiene, food, illness, recreation, friendships, discipline, emotional distress, and spiritual routine. A boarding school that treats boarding as logistics rather than formation will eventually face hidden problems.
Dormitory supervision should be written and reviewed. Who is responsible at night? How are illnesses reported? How are younger students protected from bullying? Where are complaints recorded? How are students allowed to contact parents? What happens if a student is persistently withdrawn? Who supervises bathing areas, laundry routines, and medication? These questions are not excessive. They are the minimum due to children living under institutional care.
Food and health deserve serious attention. Poor food quality damages morale and concentration. Weak sickbay records can hide recurring illness. A Catholic school should know whether students are eating well, sleeping enough, receiving timely care, and living in clean conditions. A student who feels unseen in the boarding house will not experience the school’s faith language as credible.
10.3 Reading Culture, Library Use, and Language Formation
A serious Catholic secondary school should build a reading culture deliberately. Many Nigerian students encounter English as the language of instruction while thinking, praying, joking, and living in other languages. This multilingual reality is not a weakness. It becomes a weakness only when schools ignore language development and expect students to perform complex academic tasks without enough reading support.
The library should not be a locked room used during inspection. It should be part of the timetable. Students should read fiction, history, biography, science, Catholic literature, African literature, newspapers, and well-chosen digital materials. Reading periods, book reviews, debates, writing clubs, and guided note-making can strengthen learning across subjects. A student who reads well can survive many weaknesses; a student who reads poorly will struggle even with good teachers.
Language formation should include writing. Students need to write essays, reports, reflections, laboratory notes, arguments, and prayers with clarity. Teachers across subjects should correct expression without humiliating students. Catholic education values truth; weak language often prevents students from expressing truth with precision.
10.4 Science, Mathematics, and Practical Learning
Catholic schools in Nigeria have often been respected for discipline and academic seriousness, but the next stage requires stronger practical learning. Science should not be taught as copied notes and memorized definitions. Mathematics should not be taught as fear. Entrepreneurship should not become a subject students pass without learning initiative. Laboratories, projects, local problem-solving, and supervised practice should become part of serious secondary education.
A school does not need world-class facilities to begin improvement. It can ensure that every science topic with a practical component has a demonstration or experiment. It can use local materials responsibly. It can create mathematics clinics for weak learners. It can connect geography to the local environment, civic education to community service, and entrepreneurship to carefully supervised school projects. The issue is not glamour. The issue is whether students touch reality through learning.
The NERDC curriculum materials place trade, entrepreneurship, science, and general courses within the Nigerian secondary school expectation (NERDC, n.d.). Catholic schools should implement those areas with moral seriousness. Students should learn not only to make money but to work honestly, solve problems, and serve communities.
10.5 Discipline, Character Formation, and Restorative Correction
Discipline in a Catholic school should form conscience, not only produce silence. Order matters. Students need punctuality, neatness, respect, study habits, truthfulness, and responsibility. But discipline that relies on shame, fear, arbitrary punishment, or public humiliation damages formation. A student who obeys only because he is afraid has not necessarily become virtuous.
Restorative correction can help, but it must be disciplined. Students who harm others should face consequences and repair. A student who bullies should be required to stop, apologize where appropriate, accept sanctions, receive mentoring, and be monitored. A student who cheats should learn why dishonesty harms community, not only receive a beating or suspension. Mercy without accountability becomes weakness; punishment without formation becomes cruelty.
Staff must be consistent. If one teacher enforces rules fairly and another ridicules students, the school’s moral message becomes unstable. Discipline policy should be written, taught, practiced, and reviewed. Chaplaincy, counseling, and classroom management should work together rather than operate in separate worlds.
10.6 Digital Minimums Before Digital Ambition
Many schools want digital prestige before digital reliability. A Catholic secondary school should establish digital minimums first: accurate student records, secure fee records, teacher attendance records, term results, parent contact database, safeguarding logs, library records, and basic communication channels. These are not glamorous, but they are useful.
Digital ambition should follow school need. If students lack reading skill, digital tools should support reading. If parents miss information, communication tools should be improved. If teachers waste time compiling results manually, a simple system can help. If safeguarding reports are lost, secure documentation is needed. Digital tools should be judged by whether they reduce confusion, protect students, improve learning, or strengthen communication.
Artificial intelligence should be approached with caution. The Catholic Secretariat of Nigeria’s 2024 Education Summit included education justice and artificial intelligence in a digitally divided world among its discussion topics (Nigeria Catholic Network, 2024). That is the right framing. AI can support learning and administration, but unequal access, plagiarism, privacy, and teacher readiness must be addressed before schools rush into adoption.
10.7 Examination Integrity and Academic Honesty
Examination integrity is a moral issue. A Catholic school that tolerates cheating in order to protect results has contradicted its mission. Examination malpractice is not only a regulatory problem; it forms students into the belief that results matter more than truth. That belief later enters public service, business, medicine, law, politics, and family life.
Academic honesty should be taught from junior secondary level. Students should learn how to study, cite sources, complete assignments, work in groups, and prepare for tests. Teachers should design assessments that reduce copying and reveal understanding. School leaders should monitor exam conditions, result patterns, and teacher pressure. Parents should be told that the school will not buy success through dishonesty.
When students fail, the school should examine why. Was the teaching weak? Was the student unsupported? Was the assessment misaligned? Was there poor attendance? Were parents informed early? Integrity requires truth on both sides: students must work honestly, and schools must support honestly.
10.8 Counseling, Mental Health, and Spiritual Care
Adolescents in Nigerian secondary schools face pressure that adults sometimes minimize. They are expected to succeed academically, obey authority, manage family expectations, cope with social media, resist harmful peer influence, and make decisions about faith, sexuality, friendship, and future careers. Some carry grief, poverty, family conflict, trauma, or anxiety. Catholic schools should not assume that prayer alone replaces counseling, or that counseling replaces prayer.
A school counseling service should be confidential within safeguarding limits, accessible, and respected. Students should know where to go when they are distressed. Teachers should know how to refer. Chaplains should work with counselors without turning every psychological issue into a moral failure. Serious Catholic care understands the whole person.
Mental health support does not need to begin with expensive programs. It can begin with trained staff, safe reporting, mentoring, parent communication, study stress management, anti-bullying practice, and careful response to self-harm warning signs. A student who feels safe enough to speak may be protected from deeper harm.
10.9 Staff Appraisal and Professional Accountability
Staff appraisal should be fair, documented, and tied to improvement. Many schools either avoid appraisal because it creates conflict or use appraisal only when they want to remove a teacher. Both approaches are weak. A teacher should know what the school expects, how performance is reviewed, what support is available, and what consequences follow persistent neglect.
Appraisal should examine lesson quality, punctuality, assessment, student feedback, classroom management, Catholic identity, teamwork, safeguarding compliance, and professional conduct. It should include conversation, not only forms. Strong teachers should be recognized and given leadership opportunities. Weak teachers should receive support before sanctions, unless the issue involves serious misconduct.
Catholic schools should protect teachers from parent bullying as well as protect students from teacher misconduct. Professional accountability must be balanced. If parents can pressure management into unfair action against staff, teacher morale will weaken. If staff can mistreat students without consequence, family trust will collapse.
10.10 Facilities, Maintenance, and Environmental Responsibility
Facilities shape learning and safety. A classroom that is hot, overcrowded, dark, noisy, or poorly furnished affects concentration. A laboratory without supplies weakens science. A dormitory without adequate supervision and sanitation threatens welfare. A sports field that is unsafe discourages healthy recreation. Maintenance is not vanity. It is part of education.
School leaders should maintain a facilities risk register. It should include roofs, electrical systems, water, toilets, kitchens, dormitories, laboratories, perimeter security, fire safety, transport, and drainage. Each risk should have an owner and timeline. Small neglected repairs often become expensive crises. A Catholic school that preaches stewardship should care for property responsibly.
Environmental responsibility should be taught through practice. Waste management, school gardens, water conservation, energy discipline, and clean surroundings can become part of formation. Students learn respect for creation not only from textbooks but from how the school treats its own environment.
10.11 Alumni, Scholarship Funds, and Career Mentoring
Alumni are often an underused strength of Catholic schools. They carry memory, gratitude, professional networks, and financial capacity. Schools should organize alumni support beyond social events. Alumni can fund scholarships, mentor students, support career days, provide internships, donate books and equipment, and help schools manage professional opportunities.
Scholarship funds should be governed carefully. Criteria should be written. Selection should protect dignity. Donors should receive appropriate reports without exposing student privacy. A student benefiting from aid should not be publicly marked as poor. Catholic generosity should not become humiliation.
Career mentoring is especially important in senior secondary school. Students need to meet doctors, engineers, teachers, entrepreneurs, priests, religious sisters, lawyers, artisans, scientists, public servants, and social workers who can speak honestly about work. Such exposure helps students connect education with vocation and service.
10.12 Annual School Review
Every Catholic secondary school should conduct an annual school review before the next session begins. The review should include academic results, learning support, teacher retention, staff formation, safeguarding, finance, boarding welfare, parent communication, facility risks, student voice, and mission life. The output should be short enough to act on. A long report that nobody uses is another form of waste.
The annual review should identify three strengths, three risks, and three priorities. Each priority should have an owner, timeline, and evidence measure. If the school selects ten priorities, it may complete none. Discipline in improvement means choosing what matters most now.
The proprietor or board should receive the review and respond. Support may be needed: funds, training, policy clarity, staff approval, or external advice. Review without response breeds cynicism. Response without evidence breeds impulsive leadership. The two must remain together.
Chapter 11: Moral Risk Scenarios and Institutional Response
Catholic schools should rehearse serious scenarios before they happen. Many crises feel overwhelming because leaders are forced to invent processes under stress. Scenario thinking helps a school prepare without becoming fearful. It also exposes weaknesses that ordinary meetings may miss.
The following scenarios are not speculative drama. They are realistic conditions Nigerian Catholic secondary schools may face. Each scenario requires pastoral judgment and management discipline. The aim is to protect students, staff, families, and mission credibility.
11.1 Fee Arrears and Salary Pressure
A school enters second term with rising fee arrears. Food suppliers are demanding payment. Teachers are asking when salaries will be paid. Parents complain about fees but also demand high quality. The principal is tempted to threaten mass exclusion of students with arrears. This response may produce short-term cash, but it may also damage the school’s Catholic witness and relationship with families.
The proper response begins with data. How many families are in arrears? Which arrears are chronic? Which are temporary? Which students are on scholarship? Which expenses can be delayed without harm? Which cannot? The school should communicate respectfully, offer structured payment plans where appropriate, protect teachers’ salaries as a priority, and activate scholarship or emergency funds. Fee discipline and compassion should be managed together.
The long-term response is budget reform. The school should not run permanently on emergency appeals. It needs cost review, reserve planning, transparent fees, alumni support, and a bursary policy. Financial pressure should become a lesson in stewardship, not a season of panic.
11.2 Security Warning Before a School Event
A school receives a credible warning before an inter-house sports event or visiting day. Parents are expected. Vendors have been contracted. Students are excited. Cancelling will create anger and cost. Continuing without review may expose children and families to danger. The principal must act quickly, but not theatrically.
The response should follow a written safety protocol. The school should consult relevant authorities, proprietor, board chair, and security adviser where available. It should assess threat credibility, entry points, crowd control, transport, emergency communication, medical support, and cancellation options. Parents should receive timely communication that is honest without spreading panic.
After the event or cancellation, the school should review the process. What worked? What failed? Were phone numbers current? Did staff understand roles? Did rumors spread because communication was slow? A safety incident should leave the school better prepared than before.
11.3 Examination Decline in a Core Subject
The school’s mathematics results decline sharply over two years. Parents blame students. Teachers blame poor foundations. Management blames laziness. None of these reactions is enough. A Catholic school serious about learning should investigate the teaching and learning chain.
The review should examine teacher continuity, curriculum coverage, student baseline, homework completion, lesson observation, internal assessments, textbook use, remedial support, class size, and student attitudes. The school may discover that weak numeracy from primary school is part of the problem, but that does not absolve the school. It should create a mathematics recovery plan with diagnostics, small groups, teacher coaching, and parent guidance.
The school should report honestly to its board. Hiding poor performance until external results collapse is irresponsible. A decline in one subject can reveal deeper weaknesses in teacher support, departmental leadership, and assessment integrity.
11.4 Safeguarding Allegation Against a Staff Member
A student reports inappropriate behavior by a staff member. The case is unclear. The staff member is popular. Parents may hear rumors. The school fears reputational damage. This is the moment when Catholic identity is tested. The first duty is protection and truth, not institutional image.
The school should follow safeguarding protocol immediately: ensure the student’s safety, record the allegation, notify designated authorities according to policy and law, protect confidentiality, remove the accused from unsupervised contact where appropriate, and avoid informal settlement. No principal should improvise a private solution in a safeguarding matter.
Communication must be careful. The school should not reveal private details, but it should not lie or minimize. After the matter is handled through proper channels, the school should review whether reporting pathways, supervision, staff training, and student awareness were adequate. A safeguarding allegation is never only an incident. It is a test of the school’s protection culture.
11.5 Teacher Exodus Mid-Year
A school loses four teachers within one term. Management feels betrayed. Parents become worried. Students lose continuity. The easy explanation is that teachers are disloyal. The more serious response is to examine the conditions under which teachers left.
The teacher stability risk equation can guide review. Were salaries delayed? Was workload too high? Did teachers receive support? Were conflicts handled fairly? Was transport difficult? Did leaders listen to professional concerns? Did better opportunities appear elsewhere? The answer may include personal reasons, but a pattern of departures usually reveals school weakness.
Recovery requires more than replacement. The school should stabilize classes, communicate with parents, support students, interview remaining staff, and correct avoidable causes. If teachers leave because the school’s mission is preached but not practiced toward staff, leadership has a credibility problem.
11.6 Public Complaint on Social Media
A parent posts an angry complaint online about fees, bullying, food, or discipline. Other parents join. Alumni begin commenting. The school is tempted to issue a defensive statement. A poor response can turn a manageable complaint into public damage.
The school should first verify facts. Is the complaint valid, partially valid, exaggerated, or false? Has the parent used internal channels? Is a student’s privacy involved? Does the issue involve safeguarding? The response should be measured, truthful, and respectful. Public argument with parents rarely helps a Catholic school. Silence can also harm if it suggests indifference.
The deeper lesson is that social media often exposes weak communication earlier. If parents feel unheard, they may go public. A strong school provides clear complaint channels, response timelines, and respectful escalation. Public trust is preserved by habits formed before crisis.
11.7 Sudden Death or Serious Illness of a Student
A student dies or becomes seriously ill during the school year. The school community is shaken. Rumors spread. Parents fear negligence. Students are traumatized. Staff feel exposed. Such a moment requires pastoral care, medical clarity, communication discipline, and documentary care.
The school should activate emergency and bereavement protocols. It should support the family, notify relevant authorities, preserve records, communicate with parents appropriately, offer counseling and prayer, and review medical and supervision procedures. Compassion and accountability must remain together. The school should neither hide behind emotion nor speak like a legal department only.
After the immediate grief, leaders must ask hard questions. Were medical records current? Did staff respond quickly? Were warning signs missed? Was communication delayed? A Catholic school honors the student not by avoiding review, but by learning truthfully.
11.8 New Principal After a Troubled Period
A new principal arrives after conflict, financial strain, discipline problems, or poor results. The temptation is to announce a bold new era. That may satisfy some people briefly, but the better approach is disciplined listening and early stabilization.
The new principal should review documents, meet staff, inspect facilities, listen to students, meet parent representatives, examine finance, and review safeguarding before making major promises. Within the first term, the principal should identify the few issues that can most restore trust. Quick wins matter, but shallow theatrics should be avoided.
Leadership transition is a chance to renew culture. It is also a risk. If the new principal rejects everything before understanding the school, staff may withdraw. If the principal avoids needed change, weakness continues. The best transition combines humility, evidence, and courage.
Chapter 12: Institutional Checklists and Professional Standards
A Catholic secondary school improves when leaders convert conviction into repeatable review. Checklists are sometimes mocked as mechanical, but in complex schools they protect memory. They prevent leaders from relying on enthusiasm, charisma, or crisis-driven action. A checklist cannot love a student, but it can remind adults to do the work that love requires.
The following standards should be adapted locally. They are written for Nigerian Catholic secondary schools facing ordinary constraints: limited funds, uneven staffing, parent pressure, security concerns, examination demands, and the moral obligation to remain Catholic in practice as well as name.
12.1 Mission and Catholic Identity Checklist
The first annual review should ask whether Catholic identity has been planned, taught, and lived. Is there a clear graduate profile? Does the school have regular liturgy, prayer, service, and religious instruction? Are teachers able to explain the school’s Catholic purpose? Are students helped to connect faith with honesty, sexuality, justice, digital life, respect, and service? Are non-Catholic students treated with dignity while the Catholic identity of the school remains clear?
The review should also examine whether mission affects decisions. Does fee policy include scholarship concern? Does discipline protect dignity? Does the school serve the poor through concrete programs? Are students involved in community service that forms conscience rather than only filling a calendar? Does leadership speak truthfully when results decline or mistakes occur? Catholic identity should be tested where the school has something to lose.
A school that performs identity only during Mass will not form students deeply. A school that turns every policy decision into a mission question slowly becomes more Catholic in practice. The purpose is not to make school life pious in a narrow sense. It is to ensure that faith informs the way adults lead, teach, correct, spend, protect, and communicate.
12.2 Academic Quality Checklist
Academic quality review should begin with evidence from classrooms, not with reputation. The school should collect termly data on core subject performance, reading levels, mathematics competence, homework completion, attendance, internal assessment reliability, laboratory use, library use, and examination class readiness. Department heads should be able to identify weak topics and explain what support is being given.
Teacher lesson notes should be inspected intelligently. The point is not to collect books for administrative display. The point is to know whether teachers are planning instruction that students can follow. Principals should observe lessons and hold professional conversations. Strong teachers should share practice. Weak teaching should be corrected early, respectfully, and firmly.
Academic quality also includes students who struggle. A school that celebrates only top performers may miss its own mission. Remediation, study skills, mentoring, and parent engagement should be built into the academic year. The true test is whether more students become capable, not whether the school can advertise the few who already were.
12.3 Safeguarding and Welfare Checklist
Safeguarding review should cover policies, designated officers, staff training, visitor management, student reporting channels, dormitory supervision, transport safety, medical records, incident logs, bullying response, and communication with parents. The school should ask whether every adult on campus knows what to do when a concern arises. If the answer is no, the system is too weak.
Student welfare should include ordinary dignity. Are toilets clean? Are students eating well? Are sick students attended to? Are boarding students supervised without intrusion? Are weaker students mocked? Are punishments recorded? Are girls protected from harassment? Are boys formed away from violence and contempt? Catholic safeguarding includes the daily culture that makes harm less likely.
The school should review welfare data termly. Complaints, clinic visits, dormitory incidents, bullying reports, absences, and disciplinary sanctions can reveal patterns. Leaders should not wait for scandal before they study the ordinary signs of distress.
12.4 Finance and Affordability Checklist
Financial review should begin with the full cost of the school year. Leaders should know salary obligations, utility cost, food cost, maintenance needs, security cost, staff formation, library and laboratory costs, technology, examinations, transport, scholarship commitments, and emergency reserves. Fees should be set from evidence, not from imitation of nearby schools or last-minute panic.
Affordability review should include more than arrears. How many families request payment plans? How many students benefit from scholarship aid? How many leave because of cost? Which costs are hidden in books, uniforms, levies, trips, or boarding materials? A school may appear affordable on tuition alone while becoming difficult through accumulated charges.
Finance committees should receive clear reports. They should ask whether spending matches mission. They should also protect staff salaries and student safety as priority expenditures. A Catholic school that delays salaries while funding prestige projects sends the wrong moral signal.
12.5 Teacher Formation and Retention Checklist
Teacher review should include recruitment quality, induction, mentoring, professional learning, spiritual formation, appraisal, workload, salary timing, classroom resources, and staff morale. A school should know why teachers leave. Exit interviews should be conducted with enough trust to hear the truth. If teachers leave because leadership is harsh, salaries are delayed, or workloads are irrational, the school must correct itself.
Teacher formation should be planned across the year. Topics should include Catholic identity, adolescent development, safeguarding, assessment, classroom management, reading support, digital tools, and subject-specific instruction. Formation should not be reduced to one workshop at the beginning of the session. Teachers need sustained support.
Retention improves when teachers experience respect. Respect does not mean absence of correction. It means fairness, clarity, timely payment, listening, and professional dignity. A Catholic school cannot form students in dignity while treating teachers carelessly.
12.6 Boarding and Student Life Checklist
Boarding review should include dormitory condition, supervision rosters, lights-out procedures, study time, recreation, hygiene, sickness response, food quality, privacy, complaint channels, and access to chaplaincy or counseling. Boarding students should not feel abandoned after classes end. Some of the most important formation in a boarding school happens after evening prep, during meals, on sports fields, and in dormitory conversations.
Student life should include clubs, sports, arts, debate, service, retreat, leadership roles, and cultural activities. Examination pressure can suffocate these areas, but students need them. Whole-person education cannot exist only in speeches. It requires time and adult supervision.
The school should review whether student leadership positions form responsibility or only reward popularity. Prefects should be trained in service, boundaries, conflict management, and reporting. They should never become instruments of unchecked student power.
12.7 Data and Evidence Checklist
A school evidence dashboard can be simple. It should include enrollment, attendance, fee status, teacher turnover, core subject performance, reading support, disciplinary incidents, safeguarding reports, clinic visits, parent complaints, scholarship use, and facility risks. The data should be reviewed by leadership and board at agreed intervals.
Evidence should be interpreted carefully. A rise in incident reporting may mean conditions are worse, but it may also mean students finally trust the reporting system. A drop in parent complaints may mean improved service, or it may mean parents have given up. Data needs conversation. The principal should not treat numbers as self-explanatory.
The best evidence practice is honest, limited, and consistent. Schools do not need hundreds of indicators. They need the right few, reviewed regularly, with action attached. Data that does not lead to decision becomes another administrative burden.
12.8 Formation for Leadership Succession
Catholic schools often depend heavily on one principal, one bursar, one chaplain, or one senior teacher. That dependence is risky. Leadership succession should be planned. Deputies and middle leaders should be trained in finance basics, safeguarding, curriculum supervision, communication, and Catholic mission. A school should not become unstable because one person is transferred, retires, or falls ill.
Succession planning also protects institutional memory. Policies, records, passwords, supplier contracts, examination files, staff records, facility plans, and safeguarding reports should not live in one person’s head. Documentation is not a lack of trust. It is care for continuity.
Young teachers and staff should be invited into leadership gradually. They can lead clubs, departments, formation groups, data reviews, and service projects. The school forms future leaders by giving them responsibility with supervision. A Catholic school that does not form successors will eventually lose its own standards.
Table 5. Annual school review evidence checklist.
| Domain | Evidence to gather | Decision question |
| Mission identity | Retreat records, service projects, liturgy schedule, graduate profile | Is Catholic identity shaping school life or only appearing ceremonially? |
| Learning | Results, scripts, reading data, remediation logs, lesson observations | Which students and subjects need immediate support? |
| Safeguarding | Training records, incident logs, visitor records, supervision rosters | Are students protected by routine rather than by assumption? |
| Finance | Budget, arrears, salary record, bursary data, maintenance plan | Can the school pay its obligations and still serve its mission? |
| Teachers | Retention, appraisal notes, induction records, workload data | Are teachers being formed and retained with dignity? |
| Facilities | Risk register, repair log, water, sanitation, dormitories, labs | Which facility risks threaten learning, safety, or trust? |
12.9 Final Implementation Covenant
A Catholic secondary school should end each annual review with a covenant of action. The covenant should name what the school will protect, what it will improve, and what it will stop pretending not to see. It should be short, written, and reviewed. The word covenant is appropriate because Catholic education is not only a service contract. It is a relationship of trust involving God, students, families, teachers, Church leadership, and society.
The covenant should avoid grand language. It should state concrete actions: train all staff in safeguarding by a certain date, repair dormitory windows before resumption, establish a reading period, create a scholarship committee, review mathematics performance monthly, update emergency contacts, mentor new teachers, and publish fee policy. Such actions may look small. They are where mission becomes credible.
When a school keeps its promises, families notice. Teachers notice. Students notice. Over time, trust grows not because the school claims excellence, but because its routines make excellence believable. That is the standard this research proposes for Catholic secondary education in Nigeria.
Chapter 13: Research Extensions and Catholic Education Renewal
The paper has concentrated on how a Catholic secondary school can be run successfully, but the next stage of research should examine Catholic education as a network. Nigeria does not need isolated excellent schools surrounded by fragile ones. The Church has dioceses, religious congregations, parishes, alumni associations, professional guilds, hospitals, media platforms, universities, and charitable agencies. These relationships can strengthen secondary schools if they are organized with discipline.
Network thinking does not require every school to become identical. It requires common standards where students are vulnerable and where mission credibility is at stake. Safeguarding, teacher formation, examination integrity, financial reporting, student welfare, and Catholic identity should not depend entirely on local improvisation. A national or provincial Catholic education standard could protect weaker schools without suffocating stronger ones.
13.1 Catholic Education Data Observatory
A Catholic Education Data Observatory could collect annual information from diocesan and congregation-owned secondary schools. The data should include enrollment, gender balance, fee ranges, scholarship coverage, teacher turnover, subject staffing, boarding capacity, safeguarding training, learning outcomes, examination performance, digital readiness, and facility risks. Such a body need not be large. It must be trusted, competent, and careful with confidentiality.
The value of such an observatory would be practical. Church leaders could see which regions need teacher support, which schools are becoming unaffordable, where science staffing is weak, where girls’ enrollment is falling, where boarding risks require intervention, and which schools are strong enough to mentor others. Without shared data, Catholic education leadership risks governing by isolated reports and reputation.
The observatory should not become a punishment tool. If schools believe data will be used only to shame them, they will underreport problems. The proper culture is support with accountability. A school that reveals weakness should receive help, but it should also be expected to improve.
13.2 Shared Teacher Formation Institute
A shared Catholic teacher formation institute for Nigeria would be a major step forward. It could operate through annual residential programs, online short courses, diocesan workshops, and subject communities. Content should include Catholic educational identity, child protection, adolescent psychology, assessment, literacy across the curriculum, mathematics support, classroom management, digital pedagogy, and leadership formation.
Such an institute could partner with Catholic universities, seminaries, teacher-training colleges, professional bodies, and experienced school leaders. It should not become purely theoretical. Teachers need practical tools they can use in classrooms. Principals need case discussions drawn from actual school problems. Bursars and administrators need training in finance, records, fee policy, and procurement.
Formation should include non-teaching staff. Security guards, cooks, drivers, cleaners, nurses, and dormitory staff all affect student welfare. A school’s Catholic identity is experienced through every adult who interacts with students. Ignoring non-teaching staff is a serious mistake.
13.3 Scholarship Endowment and Mission Access
A national or diocesan Catholic education scholarship endowment could help preserve access for poorer families. The fund should be professionally governed, audited, and linked to clear criteria. It could receive support from alumni, parishes, Catholic professionals, corporate partners, philanthropists, and diaspora communities. The purpose would not be to make every school free, but to prevent Catholic education from becoming socially closed.
Scholarship should be tied to dignity. Students benefiting from aid should not be branded publicly. Their families should not be humiliated in fee offices. A Catholic scholarship system should protect privacy and communicate gratitude without turning poverty into a spectacle. Donors should receive evidence of impact, but not at the expense of student dignity.
Mission access also includes students with disabilities, students affected by conflict, girls at risk of early marriage, and students from remote communities. Catholic schools cannot serve every need, but they should know which needs they are prepared to support and which partnerships can help. A school that wants to be inclusive must plan inclusion before the student arrives. National policy now frames inclusion as a right to a safe, welcoming learning environment for learners of all abilities and backgrounds, giving Catholic schools a public reference point for their own inclusion planning (Federal Ministry of Education, 2023).
13.4 Research Agenda for the Next Five Years
Future research should test the CSSSI model with actual school data. Researchers could work with a sample of Catholic secondary schools across different regions, ownership types, fee levels, and boarding arrangements. The study could examine whether mission identity, teacher stability, safeguarding, finance, and learning support predict parent trust, teacher retention, examination performance, and student welfare.
Another research direction is student voice. Many adult discussions about Catholic schools take place without careful attention to what students experience. Do students feel safe? Do they understand Catholic identity? Do they trust teachers? Do they experience discipline as fair? Do they feel pressure to cheat? Do poorer students feel respected? Such questions would deepen school improvement.
A third research direction is affordability. Catholic education needs better evidence about fee pressure, scholarship effectiveness, alumni funding, parish support, and family sacrifice. Without this evidence, schools may either raise fees defensively or underinvest dangerously. Serious research can help Church leaders make wiser financial decisions.
A fourth direction is teacher vocation. What keeps excellent teachers in Catholic schools? What drives them away? How do salary, mission, leadership, workload, professional growth, and spiritual formation interact? If Catholic schools cannot answer that question, their future quality will remain fragile.
13.5 Closing Word on Catholic School Leadership
The best Catholic school leaders in Nigeria will not be those who speak most loudly about excellence. They will be those who can hold together prayer and payroll, doctrine and data, safeguarding and discipline, academic ambition and mercy, affordability and sustainability, tradition and new methods. That work is not glamorous. It is demanding and often lonely. Yet it is one of the most important forms of Catholic service in the country.
A successful Catholic secondary school forms students who can read the world with intelligence and conscience. It teaches them to pray, think, work, serve, question dishonesty, respect others, and carry responsibility. If such schools are run well, they become quiet engines of national renewal. If they are run poorly, they waste one of the Church’s strongest contributions to Nigeria’s future.
References
Athena Centre for Policy and Leadership. (2025). Tackling teacher shortages in Nigeria: Recruitment, training, and retention strategies. https://athenacentre.org/tackling-teacher-shortages-in-nigeria-recruitment-training-and-retention-strategies/
Congregation for Catholic Education. (2022). The identity of the Catholic school for a culture of dialogue. Vatican. https://www.vatican.va/roman_curia/congregations/ccatheduc/documents/rc_con_ccatheduc_doc_20220125_istruzione-identita-scuola-cattolica_en.html
Cristo Rey Network. (n.d.). Corporate Work Study. https://www.cristoreynetwork.org/corporate-work-study
Federal Ministry of Education. (2021). National policy on safety, security and violence-free schools in Nigeria with implementing guidelines. Federal Ministry of Education. https://education.gov.ng/wp-content/uploads/2021/12/National-Policy-on-SSVFSN.pdf
Federal Ministry of Education. (2023). National policy on inclusive education in Nigeria (Rev. ed.). Federal Ministry of Education. https://planenigeria.com/resources/national-policy-on-inclusive-education-in-nigeria-2023-executive-summary/
Federal Republic of Nigeria. (2013). National policy on education. Federal Ministry of Education. https://education.gov.ng/wp-content/uploads/2020/06/NATIONAL-POLICY-ON-EDUCATION.pdf
Francis. (2020). Global Compact on Education: Together to look beyond. Vatican. https://www.vatican.va/content/francesco/en/messages/pont-messages/2020/documents/papa-francesco_20201015_videomessaggio-global-compact.html
Global Coalition to Protect Education from Attack. (2025). Nigeria: A case study on implementing the Safe Schools Declaration. https://protectingeducation.org/publication/nigeria-a-case-study-on-implementing-the-safe-schools-declaration/
Jesuit Memorial College. (n.d.). Home. https://jesuitmemorial.org/
Jesuit Schools Network. (n.d.). Assessment resources and network surveys. https://jesuitschoolsnetwork.org/resources/resources-and-surveys/
Loyola Jesuit College. (n.d.). Loyola Jesuit College, Abuja. https://loyolajesuit.org/
National Bureau of Statistics. (2022). Nigeria multidimensional poverty index (2022). National Bureau of Statistics. https://nigerianstat.gov.ng/news/78
Nigerian Educational Research and Development Council. (n.d.). New revised senior secondary education curriculum. https://www.nerdc.gov.ng/content_manager/new_senior_curriculum_home.html
Nigeria Catholic Network. (2024). CSN set to host 2024 Education Summit. https://www.nigeriacatholicnetwork.com/csn-set-to-host-2024-education-summit/
Safe Schools Declaration. (2015). Safe Schools Declaration. https://ssd.protectingeducation.org/
UNICEF Nigeria. (2024). Immediate action needed to protect Nigeria’s children and schools. https://www.unicef.org/nigeria/press-releases/immediate-action-needed-protect-nigerias-children-and-schools
World Bank. (2022). The state of global learning poverty: 2022 update. World Bank. https://www.worldbank.org/en/news/press-release/2022/06/23/70-of-10-year-olds-now-in-learning-poverty-unable-to-read-and-understand-a-simple-text