Staffing, Clinical Governance, and Patient Protection
Research Publication by Martha N. Amadi
Institutional Affiliation: New York Center for Advanced Research (NYCAR)
Master’s-Level Publication Paper
Publication Number: NYCAR-TTR-2026-RP066
DOI: https://doi.org/10.5281/zenodo.20744307
Date: June 2026
Copyright © Martha N. Amadi, New York Center for Advanced Research (NYCAR), June 2026. All rights reserved.
Peer Review Status
Reviewed under the internal editorial framework of the New York Center for Advanced Research (NYCAR) and The Thinkers’ Review. The review covered master’s-level coherence, nursing-management relevance, evidence restraint, APA 7th citation practice, table accuracy, model boundaries, and publication readiness.
Contents
Abstract
Unsafe nursing work rarely collapses in one dramatic moment. More often, it thins out during an ordinary shift. A call bell waits too long. A new nurse decides alone because the senior nurse has been pulled into task work. A medication round is interrupted twice, then three times. A resident is not turned early enough because every aide is already occupied somewhere else. By the time a fall, pressure injury, drug error, complaint, or resignation is recorded, the service may have been giving warnings for weeks.
The study places nursing organizational management inside the patient-safety argument. Staffing is not treated as a staffing-office problem, nor is acuity left as a number at the edge of the roster. The paper reads nursing time, skill mix, handover, supervision, missed care, retention, and staff strain as connected parts of the same clinical condition. Bedside nurses do not experience these pressures separately. They arrive together, often within the same hour, around the same patient or resident.
The Nursing Care Reliability Score introduced here is intentionally limited. It is not offered as a validated national tool, a prediction engine, or a substitute for the judgment of experienced nurses. Its purpose is narrower and more useful: to help local leaders place weak signals beside one another before harm becomes the only evidence anybody is willing to accept. A low score cannot shame a unit. It makes senior review harder to avoid.
The argument is blunt because the work deserves bluntness. Nurses cannot be thanked into safe practice. They need enough prepared staff, charge nurses who can lead, protected handover, honest acuity review, support for new colleagues, and governance that treats missed care as a warning rather than an embarrassment. A service that survives by using up its experienced nurses cannot call itself resilient. It is borrowing safety from people who are already overdrawn.
Keywords: nursing organizational management, staffing adequacy, acuity, skill mix, patient safety, clinical governance, missed care, burnout, retention, TeamSTEPPS, long-term care
Chapter 1: Introduction
1.1 Background to the Study
Good nursing often disappears into the fact that nothing went wrong. The confused patient does not fall. The insulin dose is checked before the wrong assumption hardens into an error. The wound edge is noticed while it is still only beginning to change. A frightened daughter leaves with enough understanding to call early if breathing worsens at home. These are not small acts. They are the daily products of attention, judgment, and organization.
Nursing care cannot be made safe by personal kindness alone. Compassion matters, but compassion is not staffing. A nurse can be careful, experienced, and morally serious, yet still be placed in unsafe work when patient need outruns available time. New staff do not become competent because a rota says they are counted. They become safer when someone with clinical maturity has time to watch, correct, encourage, and intervene.
Current workforce evidence makes the issue larger than a local complaint. WHO frames nursing supply through education, employment, leadership, regulation, and service delivery, while United States workforce survey evidence and the NHS long-term workforce plan both point toward the same managerial fact: recruitment, retention, training, and working conditions cannot be pulled apart without weakening care (NHS England, 2023; Smiley et al., 2025; World Health Organization, 2025).
Those national and global pressures reach managers in humble, irritating forms. A post stays open after three rounds of recruitment. The best preceptor asks for a transfer. An agency nurse arrives who is capable but does not know the unit, the stock room, the escalation habits, or the resident who refuses help until a familiar voice asks twice. The spreadsheet may still show coverage. The ward knows what has been lost.
Nursing organizational management belongs in patient-safety scholarship because patients meet managerial choices through care. They meet them in response time, observation, dignity, discharge teaching, infection control, continence support, and the availability of a nurse who can stay long enough to see what is changing. Administration is not sitting politely outside the clinical encounter. In nursing, it is one of the conditions that shapes the encounter.
1.2 Problem Statement
Nurse leaders are often held responsible for failures they lack the full authority to prevent. A ward manager may answer for falls, pressure injuries, medication delays, infection breaches, complaints, turnover, sickness, overtime, and staff morale while bed flow, budget control, establishment review, and recruitment pace sit at another table. That split is not a harmless administrative inconvenience. It trains people to soften the truth.
Soft wording can become a safety risk. Chronic short staffing is called temporary pressure. Missed breaks are praised as commitment. Late documentation becomes a personal weakness even when the work could not physically fit into the shift. Staying after duty is described as dedication, although it may be the clearest evidence that the staffing plan is false.
Fragmentation hides the pattern. Staffing appears in one meeting, burnout in another, quality in another, and turnover in a human-resources report that arrives after the ward has already changed. Nursing work is not organized that way. A weak roster damages handover. Poor handover weakens surveillance. Weak surveillance raises risk. Incidents increase strain. Strain pushes staff out. The next rota then begins weaker than the last.
This paper addresses that practical problem. It does not ask whether nurses care enough. Most nurses care well beyond what the system has any right to expect. The question is whether organizations arrange nursing work so that care can remain safe without unpaid rescue, private sacrifice, silence about omitted care, or the quiet burning up of experienced staff.
1.3 Aim and Objectives
The aim is to explain how nursing organizational management protects patient safety through staffing adequacy, acuity-sensitive assignment, skill-mix judgment, reliable handover, clinical governance, and retention discipline. The concern is not abstract leadership. It is the next unsafe shift: the delayed observation, the unsupported new nurse, the interrupted medicine round, the exhausted charge nurse, the family who did not really understand discharge instructions.
The objectives are to define nursing management as safety work; review current evidence on workforce pressure, staffing, burnout, teamwork, and long-term care; develop a limited local reliability score for managerial review; and connect the evidence to decisions that nurse managers, directors, executives, and boards can examine without pretending that a score replaces judgment.
Management vocabulary earns its place only when it touches the work. Words such as governance, improvement, and excellence mean little if the senior nurse cannot leave task work long enough to lead. A nursing-management paper has to survive the ward manager’s question: what changes on the next dangerous shift?
1.4 Research Questions
The guiding questions stay close to practice. Where does nursing management meet patient safety? How does a roster become unsafe before an incident proves it? Which signals show that care is being rationed? How do skill mix, supervision, handover, retention, and staff strain interact during real shifts? What can a local reliability review reveal without pretending to predict every harm event?
None of these questions assumes an easy cure. Workforce supply is slow, political, expensive, and uneven. Some services recruit in markets where the candidates are not there. Still, honesty is possible before rescue is possible. Leaders can stop calling unsafe staffing difficult but acceptable. They can record missed care as evidence. They can give nurses words that do not leave bedside staff carrying institutional failure alone.
1.5 Scope and Boundaries
The scope is nursing organizational management. The paper does not replace clinical guidelines, employment law, professional regulation, or human-resources policy. It examines the point where those systems meet the shift: patient dependency, admissions, discharges, staff experience, fatigue, equipment, handover, escalation, and the authority to act when the work is no longer safe.
Boundaries matter because blame is sometimes the cheapest form of governance. Nurse managers cannot be blamed for every condition produced by labor markets, funding decisions, training capacity, immigration rules, housing cost, reimbursement, or hospital demand. Accountability remains necessary. Blame without system review is not accountability; it is avoidance. A fall, pressure injury, infection breach, or medication error may be recorded against a unit, while the conditions behind it may have been authorized above the unit for months.
1.6 Working Definitions
Staffing adequacy means more than names placed in boxes on a roster. It means the available nursing time, knowledge, familiarity, and authority are sufficient for the patients or residents actually present. Acuity refers to the level of attention, dependency support, observation, coordination, teaching, and judgment a person requires. Skill mix refers to the fit between patient need and the capabilities, registration status, local familiarity, and supervision requirements of the team.
Clinical governance refers to the way a service knows, controls, and learns from risk. In nursing, it includes escalation, incident review, professional standards, staffing review, and the willingness to treat staff warnings as safety evidence. Missed care means necessary care that is delayed, shortened, or omitted because capacity and need no longer match.
1.7 Reading Position
Readers need to approach the work as managerial judgment grounded in evidence. Staffing, burnout, communication, retention, and patient safety can be separated for study, but nurses meet them together at the bedside. Practice scenes appear throughout the paper because ordinary scenes often carry the risk more honestly than formal phrases do.
Strong nursing scholarship has to avoid theatrical certainty. No framework can rescue a service that lacks staff, senior judgment, or the courage to say that the shift is unsafe. A framework can still help leaders notice deterioration earlier, argue more clearly, and protect patients with better discipline. That is a modest claim, but it is not a weak one.
1.8 Publication Need
The publication need comes from the gap between the way systems praise nurses and the way nursing work is often arranged. Health services celebrate nurses in public language while failing to examine the staffing, supervision, and authority that make safe care possible. That contradiction is not a public-relations problem. It is a patient-safety problem.
Graduate-level nursing management needs language strong enough for practice. It cannot hide behind generic leadership phrasing. The discipline has to describe the nurse who misses lunch again, the resident whose continence care is delayed, the new staff member learning too fast under pressure, and the manager who knows the shift is unsafe but cannot get an answer from above.
Chapter 2: Current Nursing-Management Evidence
2.1 Management Begins Before the Incident
A nurse manager begins safety work before the dashboard, before the monthly report, and well before the incident form. Assignment decisions, equipment readiness, shift balance, senior cover, handover protection, and the handling of staff warnings all shape the patient’s day. Harm may be documented at the end of a chain. The managerial conditions often sit near the beginning.
Patient-safety thinking has long warned against blaming the visible clinician while ignoring the work system. Nursing makes that warning concrete. Nurses are close enough to see confusion, pain, breathlessness, fear, family uncertainty, and quiet deterioration as they unfold. When there are too few nurses, or too little experienced judgment, the service loses part of its ability to see.
Burnout research adds weight to the point. Dall’Ora and colleagues link burnout with demands, control, recognition, fairness, and support, not with personal weakness alone (Dall’Ora et al., 2020). For managers, the implication is practical. Exhausted nurses have less recovery, less tolerance for interruption, less patience for avoidable confusion, and fewer reserves when a patient suddenly worsens.
Nursing management is not a decorative service around the clinical work. It protects the conditions under which clinical work is possible. A ward can have a fine policy file and still fail patients if the roster is fiction, handover is rushed, supervision is symbolic, and concerns raised by staff are treated as attitude.
2.2 Staffing Adequacy and the Lie of the Simple Number
Staffing adequacy is often reduced to headcount because headcount is easy to display. Serious nurse leaders know that the number is only the first question. Six nurses may be safe on one ward and unsafe on another. A roster may look full while two nurses are newly qualified, one is unfamiliar with the unit, and the charge nurse is carrying a heavy patient assignment.
Acuity brings the patient back into the staffing conversation. It asks what the work requires: close observation, turning, medicines, continence support, safeguarding, dementia care, isolation precautions, discharge teaching, nutrition, mobility, wound care, and family communication. Bed count hides much of that. A quiet bed is not always a low-workload bed.
Skill mix complicates the matter again. Registered nurses, licensed practical or vocational nurses, nursing assistants, healthcare assistants, and temporary staff all contribute, but they are not interchangeable pieces. Substitution may look efficient from a distance while moving risk into delegation, supervision, recognition of deterioration, and escalation. Longitudinal evidence continues to associate nurse staffing levels with patient outcomes, though settings and measures differ (Dall’Ora et al., 2022).
A reliable manager uses ratios as floors, not as proof. A ratio cannot say whether three admissions arrived late, whether half the team is unfamiliar with the unit, whether a dying patient’s family needs time, or whether the senior nurse can actually lead. Numbers can start the conversation. They cannot end it.
Table 1. Nursing Staffing Risk Controls
| Risk control | Managerial question | Patient-safety meaning |
| Staffing adequacy | Does available nursing time match the actual work on this shift? | Weak staffing reduces surveillance, timeliness, teaching, documentation, infection control, and dignity. |
| Acuity fit | Does the roster reflect dependency, instability, admissions, discharges, isolation, and observation need? | Bed count alone can hide workload and create false assurance. |
| Skill mix | Does the team have enough registered judgment, support staff, and locally familiar temporary staff? | Unsafe substitution weakens delegation, supervision, and escalation. |
| Supervisory cover | Is a senior nurse free enough to lead rather than simply fill a gap? | New staff, unstable patients, and complex decisions need visible leadership. |
| Missed-care control | What care has been delayed, shortened, or omitted, and why? | Repeated omission warns that capacity and need have separated. |
2.3 Missed Care as Early Warning
Missed care is sometimes pushed to the soft edge of nursing: delayed mouth care, late observations, shortened discharge teaching, a postponed walk, a resident turned later than planned. That view is careless. Missed care is the service rationing attention while hoping the result stays hidden.
Patients and residents may not speak the language of staffing adequacy, but they know its effects. They wait longer. They receive less explanation. They are moved before their fear is settled. A family leaves with paperwork but not understanding. In long-term care, one missed turn or delayed toileting episode may become skin breakdown, infection risk, distress, or humiliation.
Managers need to record missed care without turning the record into a trap. If nurses believe every omission will be used against them, silence becomes self-protection. A safer service asks what was left undone, why it was left, how often the pattern returns, and what decision would prevent the same failure next week.
2.4 Handover, Teamwork, and the Conditions for Communication
Handover is often described as a communication process. At ward level it is a safety exchange under strain. The outgoing team is tired. The incoming team needs the truth quickly. Relatives interrupt, phones ring, admissions arrive, and the ward does not stop because a form says handover time is protected.
TeamSTEPPS 3.0 provides useful language for communication, team leadership, situation monitoring, and mutual support (Agency for Healthcare Research and Quality, n.d.). Tools help. They do not work by magic. A check-back cannot rescue a team when the charge nurse is too overloaded to notice drift, or when staff who raise risk are quietly marked as difficult.
Reliable communication needs setting and authority. Nurses must know who is unstable, which families need attention, what medicines are risky, what has changed since the last review, and which staffing gaps require adaptation. Handover fails when leaders treat it as a courtesy. It is a safety control.
2.5 Retention, Experience, and Local Memory
Retention deserves a stronger place in safety debate. Losing a nurse removes more than one body from the rota. It removes local memory: which patient underreports pain, which corridor is unsafe at night, which junior doctor needs a firmer escalation, which family remains anxious because the last discharge was handled badly.
Workforce survey evidence points to continuing strain in the profession and the need to read age profile, employment movement, and intent-to-leave data carefully (Smiley et al., 2025). A manager who treats turnover as recruitment paperwork misses the clinical loss. A service can replace hours and still lose judgment.
Experienced nurses also carry culture. They teach what must be escalated, what cannot be ignored, and what staff are allowed to say aloud. When those nurses leave, new staff may inherit policies without the informal wisdom that kept patients safe. Retention is not sentiment. It is part of the safety system.
2.6 Evidence Read with Caution
Staffing research is strong enough to matter and complex enough to require restraint. Hospitals, long-term care homes, community services, mental health units, and specialist wards are not identical. Measurement varies. Patient need changes. Some outcomes are easier to count than dignity, teaching, trust, fear, or professional judgment.
Caution cannot become paralysis. Evidence does not need to answer every local question before leaders act on obvious risk. A unit with repeated missed care, thin supervision, heavy overtime, missed breaks, and rising exits already has enough information to begin. The question is whether leadership is willing to hear what the evidence and the nurses are saying.
2.7 What Experienced Nurses Notice
Experienced nurses notice small disorder before it becomes official risk. They see the patient who is too quiet, the aide rushing because continence care has fallen behind, the temporary nurse unable to find equipment, the new graduate smiling while drowning, and the relative who nods but has not understood the discharge plan. These observations are not gossip. They are part of the safety system.
Organizations often lose this intelligence because it arrives in the wrong form. A senior nurse may say the ward feels unsafe before a metric confirms it. Dismissing that warning because it sounds subjective is poor management. Skilled nursing judgment is often pattern recognition built from years of patient contact.
Leaders need to create regular spaces for that knowledge to be spoken without drama. A short end-of-shift review, a weekly staffing-risk conversation, or a protected meeting with charge nurses can reveal details no dashboard holds. The point is not to replace data with feeling. It is to stop pretending that numerical data is the only witness.
2.8 The Danger of Polished Assurance
Polished assurance can be dangerous in nursing services. Reports may say staffing was challenging but managed, communication remained effective, and teams continued to deliver safe care. The sentences sound calm. They may also erase the truth that nurses stayed late, skipped breaks, delayed care, and used private judgment to prevent a worse outcome.
Nursing evidence has to make assurance more honest, not more attractive. A leader can say no major incident occurred and also say the shift was not safely staffed. Both can be true. Absence of harm is not proof of safety. It may mean staff rescued the system one more time.
Chapter 3: Methodology and Analytical Framework
3.1 Design
Amadi uses an applied evidence-review design with management interpretation. The method reads public workforce reports, peer-reviewed nursing research, patient-safety material, policy documents, and practice-based management questions through a simple problem: how does the organization of nursing work affect the safety of care?
The design stays close to practice because a ward cannot be understood by theory alone. Theory helps name patterns. It does not hear the phone ringing during handover, see the agency nurse searching for equipment, or notice the new nurse who has stopped asking questions because everyone looks busy. The paper keeps returning to the shift because the shift is where management becomes visible.
No invented interviews, private patient records, or artificial datasets are introduced. Practice scenes are used as interpretive examples, not as claimed empirical findings. That boundary matters. Nursing scholarship weakens itself when it pretends to hold data it does not possess.
3.2 Evidence Sources
Core sources include WHO’s 2025 nursing report, the 2024 National Nursing Workforce Survey, AHRQ TeamSTEPPS 3.0 materials, staffing-outcome research, burnout research, NHS England workforce planning, Magnet-related nursing excellence material, and United States long-term care staffing policy documents (Agency for Healthcare Research and Quality, n.d.; NHS England, 2023; Smiley et al., 2025; World Health Organization, 2025).
Each source is used within its proper limits. WHO frames global workforce, leadership, education, regulation, employment, and service-delivery pressures. The workforce survey supports interpretation of United States employment and retention signals. TeamSTEPPS provides tested communication language, while the staffing and burnout literature helps connect nursing conditions with safety and organizational strain.
No source is asked to do more than it can do. A global report does not describe a single ward. A staffing study does not settle every local ratio. Teamwork training does not fix a false roster. Evidence gives direction; it does not relieve leaders of judgment.
Table 2. Evidence Sources and Management Use
| Evidence source | What it contributes | Management use |
| WHO State of the World’s Nursing 2025 | Global workforce, education, leadership, regulation, employment, and service-delivery picture. | Places local staffing pressure within wider workforce and policy conditions. |
| 2024 National Nursing Workforce Survey | United States nursing workforce demographics, employment patterns, and retention evidence. | Supports age-profile review, vacancy-risk interpretation, and retention planning. |
| AHRQ TeamSTEPPS 3.0 | Communication, team leadership, situation monitoring, mutual support, and implementation tools. | Strengthens handover and escalation when local conditions support the behavior. |
| CMS and Federal Register staffing material | Policy movement around long-term care staffing minimums and later repeal action. | Shows why resident need, labor supply, regulation, and provider capacity must be read together. |
3.3 Analytical Logic
The analysis begins with the shift. Staffing plans, patient need, temporary cover, senior availability, handover quality, missed care, retention, and emotional strain are examined together because nurses experience them together. A clean organizational chart may separate these matters. Care does not.
A local reliability score is used to organize review. The Nursing Care Reliability Score is not a predictive model and not a validated national measure. It gives leaders a disciplined way to ask whether conditions for safe nursing are improving or fraying. Any formal use would require local validation, governance approval, adaptation, and periodic review.
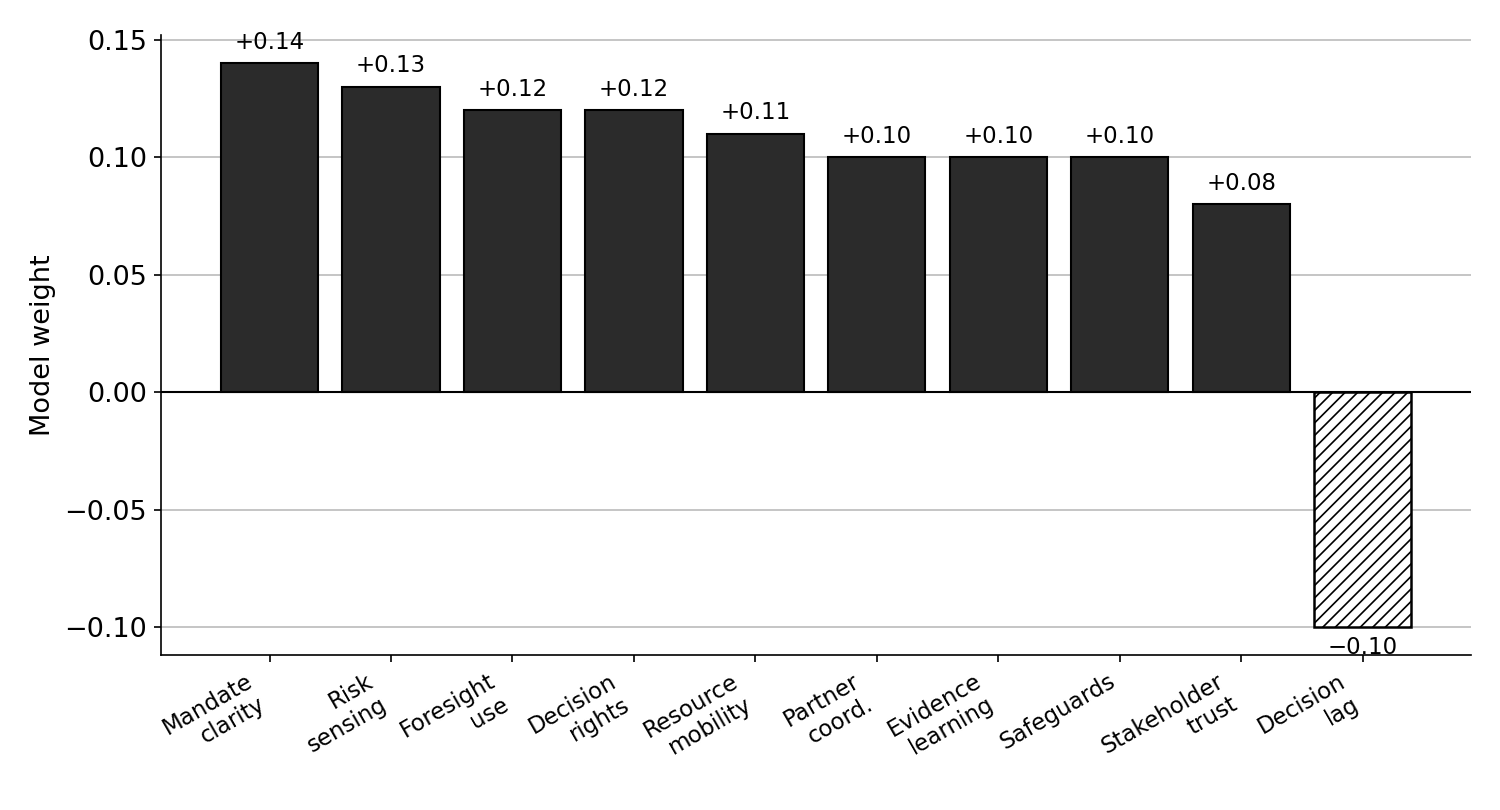
Variables are scored from 0 to 5. A score of 0 indicates severe risk. A score of 3 indicates workable but unstable conditions. A score of 5 indicates strong reliability. The calculation is: NCRS = 0.16SA + 0.14AF + 0.13SM + 0.12HR + 0.12SC + 0.12MC + 0.11RR + 0.10SS. The weights add to 1.00. They reflect the evidence review and are made visible so leaders can challenge the assumptions rather than accept a hidden formula.
Table 3. Nursing Care Reliability Score Variables
| Variable | Meaning | Evidence used in review |
| SA | Staffing adequacy | Planned versus filled roster, vacancies, agency use, overtime, missed breaks, and escalation records. |
| AF | Acuity fit | Dependency, complexity, admissions, discharges, observation level, isolation, deterioration risk, and family need. |
| SM | Skill mix | Registered nurse cover, assistant roles, agency familiarity, new staff, and preceptor availability. |
| HR | Handover reliability | Shift overlap, interruptions, attendance, transfer completeness, and recurring information gaps. |
| SC | Supervisory cover | Charge nurse availability, senior response, leadership workload, and coaching capacity. |
| MC | Missed care control | Reported omissions, delayed care, patient or family concern, and staff accounts of rationed work. |
| RR | Retention resilience | Turnover, internal transfer, sickness, exit themes, age profile, and loss of local experience. |
| SS | Staff strain control | Burnout indicators, moral strain, conflict, overtime, sickness, and recovery between shifts. |
3.4 Interpreting the Score
A score near 5 suggests strong local reliability. It does not promise that no harm will occur. A score around 3 suggests a service that may function through effort but lacks margin. A score below 2.5 needs to trigger senior review because several safeguards are likely failing at once.
The score belongs beside narrative evidence. A unit may report acceptable numbers while staff describe unprotected handover, regular missed care, or a charge nurse unable to lead. Narrative does not contaminate the score. It protects the score from false precision.
Weighting carries an ethical message. If staffing adequacy and acuity fit carry significant influence, leaders cannot hide behind morale work while the roster remains unsafe. If missed care and staff strain are included, the score refuses to treat exhausted silence as success.
3.5 Quality Controls
Quality control begins with source discipline. Claims are tied to published research, official reports, or clearly marked management interpretation. Current policy is checked because staffing regulation changes. The paper avoids unsupported figures, invented interviews, and private claims.
A second control is voice. Nursing-management writing can slip into comfortable phrases that tell nobody how the work is actually done. The prose returns to assignments, handovers, missed care, supervision, and escalation because those details keep the paper honest.
A final control is restraint. The framework cannot repair a poor labor market, fund posts, or guarantee retention. It can make risk harder to deny. In nursing management, that is already a useful contribution.
3.6 Ethical Position
Ethics in this paper is not limited to confidentiality, although no private patient records are used. The deeper ethical issue is fairness in assigning responsibility. Bedside nurses cannot carry blame for organizational conditions they warned about but could not change. Managers cannot be given authority in title only. Patients cannot learn that arrangements were unsafe only after harm occurs.
Clear evidence, honest language, and visible escalation are ethical practices. They prevent a service from turning structural risk into personal failure. A nursing paper that ignores that conversion may sound orderly, but it will not be truthful.
3.7 Handling Local Evidence
Local evidence belongs close to the work. Roster data, overtime records, incident reports, staff sickness, agency use, missed-care notes, patient complaints, discharge delays, and staff accounts all matter. None is complete alone. A clean dashboard can hide exhausted practice. A strong complaint file can hide quiet families who no longer expect attention.
Useful review asks nurses to explain the numbers. If overtime rose, what drove it? If missed care fell, did care improve or did reporting become unsafe? If agency use remained stable, were the same agency nurses returning, or was the team receiving different people every week? Local interpretation keeps data from becoming decorative.
Documentation has to be plain enough for senior leaders to understand and specific enough for action. “High pressure” is not enough. Better evidence says the ward carried three high-observation patients, two late admissions, one unfamiliar agency nurse, no protected charge nurse, and delayed turns. Specific detail creates accountability.
3.8 Why the Model Stays Modest
The model stays modest because nursing work resists neat packaging. A score cannot feel the atmosphere on a ward after two resignations. It cannot know that a family has lost trust or that a new nurse is hiding fear. It can only organize selected signals and help leaders ask better questions.
That limitation is acceptable if it is named. Modest tools can still be useful. They prevent drift, support comparison over time, and force discussion of issues that might otherwise remain informal. Trouble begins when a tool is treated as proof instead of prompt.
3.9 Safeguards Against Cosmetic Compliance
Cosmetic compliance is a known danger in nursing management. A form may be completed, a huddle recorded, and a staffing review filed while the actual shift remains unsafe. The method therefore treats documentation as evidence only when it matches staff experience and visible operating conditions.
Reviewers need to ask whether a control changed the work or simply described it. Protected handover has to mean fewer interruptions, not a new heading in meeting notes. Preceptorship has to mean time to supervise, not a name beside a new nurse. Escalation has to mean a decision, not a forwarded email. These checks keep the framework close to practice.
Chapter 4: Case Evidence and Applied Institutional Analysis
4.1 Workforce Pressure Reaches the Bedside
Global nursing pressure is not abstract once it reaches a ward. It appears as slow recruitment, thin experience, heavier overtime, weaker continuity, and less time for education. WHO’s 2025 report places education, jobs, leadership, remuneration, regulation, and service delivery in one policy conversation (World Health Organization, 2025). Counting nurses alone will not solve nursing safety.
For a local manager, the global picture matters because it limits easy answers. A vacancy may not be a local failure. A facility may advertise for months in a labor market where qualified nurses have safer options, better pay, stronger support, or shorter travel elsewhere. Blame is easy. Workforce planning is harder.
Local leaders still make decisions. They decide whether risk is named accurately, whether temporary staff are oriented, whether new nurses receive protection, whether experienced staff are retained, and whether unsafe conditions reach senior governance in language strong enough to require an answer.
4.2 United States Workforce Signals
The 2024 National Nursing Workforce Survey offers signals that managers cannot treat as background. Age profile, employment movement, intent to leave, and work-environment concerns tell leaders how stable the supply of judgment may be over the next few years (Smiley et al., 2025). A manager looking only at today’s filled shifts may miss tomorrow’s loss.
Retention risk becomes more serious when experienced nurses leave the most pressured areas. Replacing them with new graduates or temporary staff may keep the schedule open, but the ward’s safety system changes. Less experience creates more supervision need. More supervision need means the charge nurse must have time to lead. Without that time, replacement creates a new risk.
Workforce data belong at service level, not at organization level alone. A hospital may report acceptable vacancy rates while one ward becomes unsafe. Aggregates smooth the picture. Patients receive care in the uneven parts.
4.3 Staffing Research and the Local Ward
Staffing-outcome research does not need exaggeration to be important. Aiken and colleagues, Lasater and colleagues, and Dall’Ora and colleagues contribute to a body of evidence linking nursing conditions with patient outcomes, burnout, and organizational strain (Aiken et al., 2023; Dall’Ora et al., 2022; Lasater et al., 2021). The lesson is not that one ratio explains every outcome. The lesson is that nursing time and skill are clinical resources.
A local ward turns that evidence into practical questions. How many patients require close observation? Which admissions arrive late? Which nurses know the specialty? Who can manage deterioration without waiting for permission? Which staff need supervision? Who is carrying discharge teaching? Which nurse is leading the shift rather than surviving it?
Managers who do not ask these questions may still meet a staffing template. Templates have value. They are not conscience. They cannot see the resident who needs two people to turn safely, the patient whose daughter needs time before discharge, or the new nurse too embarrassed to say she has never managed that infusion.
4.4 Long-Term Care and the Staffing Debate
Long-term care makes staffing arguments morally sharp. Residents often need help with the most intimate parts of living: toileting, eating, bathing, turning, walking, remembering, and feeling safe. When staffing is thin, harm can look slow and ordinary. A resident waits. A meal is rushed. Confusion is met with impatience because everyone is already behind.
CMS’s 2024 long-term care staffing rule set minimum staffing standards, including 3.48 total nurse staffing hours per resident day, with specified registered nurse and nurse aide components. The rule emphasized resident safety and quality concerns for Medicare and Medicaid certified facilities (Centers for Medicare & Medicaid Services, 2024). Later repeal action showed the conflict among resident protection, labor supply, regulation, and provider capacity (Department of Health and Human Services & Centers for Medicare & Medicaid Services, 2025).
That debate cannot be flattened into slogans. Minimum standards can protect residents from the lowest floor of neglect. A number still cannot replace acuity judgment, workforce development, financing, or rural reality. Serious nursing management holds both truths: residents need safe staffing, and providers need realistic conditions to supply it.
4.5 Teamwork Tools in Real Conditions
TeamSTEPPS 3.0 gives services a practical vocabulary for communication, leadership, situation monitoring, and mutual support (Agency for Healthcare Research and Quality, n.d.). In a well-led unit, that vocabulary can strengthen handover, escalation, and shared awareness. In a poorly supported unit, it can become another certificate pinned over unsafe conditions.
Communication tools work when leaders defend the space for communication. A call-out matters only if someone can answer. A huddle matters only if the team can step back long enough to think. A check-back matters only if staff are not punished for slowing down a dangerous instruction.
Applied analysis therefore treats teamwork training as dependent on staffing, senior cover, and culture. Nurses cannot communicate themselves out of impossible workload. They can use a common language more effectively when the organization respects the warning carried in that language.
4.6 Magnet and Professional Practice Environments
Magnet-related nursing excellence material draws attention to professional practice, leadership, empirical outcomes, and structural empowerment (American Nurses Credentialing Center, n.d.). These themes matter even outside formal designation. Strong nursing environments give nurses voice, development, governance, and credible access to leadership.
Excellence language must be handled carefully. A service can borrow the language of empowerment while leaving the ward manager without authority to change staffing or protect handover. Nurses know the difference between a culture that listens and a culture that has learned the phrases.
Professional practice environments are tested during pressure. Can a nurse challenge unsafe discharge pressure? Can a charge nurse close or slow activity when staffing is unsafe? Can missed care be reported without humiliation? Can a director take ward evidence to executives without softening it into polite concern? Those tests reveal the institution.
4.7 Applied Institutional Reading
Reading the evidence together gives a practical institutional picture. Workforce supply shapes what can be staffed. Local leadership shapes how scarcity is handled. Staffing research shows why nursing time matters. Teamwork tools show how communication may be strengthened. Long-term care policy shows why minimums, acuity, and capacity cannot be separated.
No single source supplies the full answer. The nurse manager has to read them together and then look at the ward. How many risks are being normalized? Which staff are quietly carrying the service? What work is always delayed? Which patients are becoming unsafe before anybody uses that word?
Institutional maturity appears when these questions are allowed to reach power. Immature organizations force nurses to absorb risk privately. Mature organizations convert warnings into staffing review, governance action, and honest communication with senior leadership.
4.8 The Board-Ward Gap
Applied institutional analysis must confront the distance between board assurance and ward reality. Senior reports compress risk into categories that look manageable. The ward experiences the same risk as a series of small decisions under pressure: who answers the bell, who watches the confused patient, who teaches the family, who helps the new nurse, who stays late to complete documentation.
The gap is not always bad faith. Executives may receive information already softened at several levels. Managers may fear sounding negative. Staff may stop reporting because nothing changed the last time. By the time risk reaches the board, it may have lost the details that made it urgent.
Nursing leadership has to protect those details. Board papers needs to include enough ward-level evidence to show what the numbers mean. A safe report does not need drama. It needs accuracy. If care is being maintained through unpaid time, repeated missed breaks, and hidden omission, the board need to know.
4.9 Reading Policy Without Losing the Patient
Policy debates about staffing become abstract quickly. Providers speak about cost and supply. Regulators speak about minimums and enforcement. Advocates speak about protection. Each position carries part of the truth. Nursing management has to bring the patient or resident back into the center of the argument.
For the resident waiting for continence care, the policy question is not ideological. It is whether someone comes in time. For the patient whose breathing changes after midnight, the issue is whether enough registered judgment is present to notice and act. Policy becomes real in those moments. Analysis that forgets them may be clever, but it is not nursing analysis.
Chapter 5: Discussion
5.1 Authority, Responsibility, and the Uneasy Middle
Fair discussion begins with limits. Nurse leaders do not control every force that shapes care. National labor supply, funding, reimbursement, training capacity, immigration rules, housing cost, and hospital demand can sit outside their authority. A manager may inherit vacancies created by decisions made years before she arrived.
Limits do not remove responsibility. Leaders still control how risk is named, how assignments are made, how handover is protected, how new staff are supervised, how missed care is recorded, and how staff concerns reach governance. A manager who cannot hire ten nurses today may still refuse to describe a dangerous shift as busy but safe.
The hard place for nurse leaders is the middle. They are close enough to see danger and sometimes too far from power to remove it. Good governance cannot leave them trapped there. Escalation needs a route, an answer, and a record.
5.2 The Moral Cost of Normalized Shortage
Shortage becomes most dangerous when it becomes normal. Staff stop reporting missed breaks because nobody answers. Delayed care becomes the rhythm of the unit. Families are managed rather than supported. New nurses learn that asking for help marks them as weak. Experienced nurses become quiet because speaking has not changed anything.
Moral strain grows from the gap between professional duty and organizational reality. Nurses know what good care requires. They also know when the service has not given them the time, staffing, or senior support to deliver it. Burnout literature gives language to part of that experience. Ward staff often say it more plainly: they are tired of failing patients in small ways.
Leadership cannot repair moral strain with gratitude alone. Thank-you messages have a place. They become insulting when used to cover unsafe conditions. Staff need rest, authority, staffing review, supervision, and evidence that senior leaders can hear difficult truth.
5.3 Why Missed Care Must Be Taken Seriously
Missed care is one of the most useful early warnings available to nurse leaders. It shows where the service is already rationing attention. The problem may not yet appear as a fall, infection, pressure injury, medication error, or complaint, but the system is giving notice.
Different omissions carry different meanings. Delayed hygiene may reflect aide shortage. Late observations may signal registered nurse overload. Short discharge teaching may point toward flow pressure. Missed supervision may show that a preceptorship arrangement exists on paper only. Each omission contains management information.
Punitive treatment destroys that information. Nurses will protect themselves by silence if honesty becomes a disciplinary risk. A safer service asks why care was missed and what must change so nurses are not placed in the same position again.
5.4 Staffing as Clinical Governance
Staffing belongs in clinical governance because it shapes surveillance, response, teaching, infection control, medication safety, and dignity. A board that reviews falls and pressure injuries without reviewing staffing conditions is reading only the last page of the story.
Governance also requires detail. Organization-wide averages may comfort executives while one unit is unsafe every weekend. Staffing evidence needs to include filled versus planned roster, temporary staff use, overtime, missed breaks, acuity pressure, escalation records, and turnover by service. Patient safety lives in the detail.
Data alone will not lead. Someone has to interpret it, challenge soft language, and bring staff experience into the room. Nursing directors and senior nurses have a duty to keep that interpretation from being diluted into generic operational pressure.
5.5 The Limits of Training
Training is often offered when a service is uneasy about structural problems. Communication training after a handover failure may be useful. It may also avoid the harder fact that handover was interrupted, rushed, and carried by people who did not know the patients.
TeamSTEPPS 3.0 and similar approaches work best when paired with local action. Huddles, call-outs, check-backs, and mutual support need time, authority, and psychological safety (Agency for Healthcare Research and Quality, n.d.). Without those conditions, staff attend training and return to the same broken system.
Before commissioning training, nurse leaders need to ask one direct question: what condition will change so the trained behavior can survive? Without a concrete answer, the training risks becoming evidence of activity rather than improvement.
5.6 Retention as a Safety Strategy
Retention is too often treated as a workforce cost. Nursing management need to treat it as a safety strategy. Experienced nurses hold local knowledge, informal coaching, pattern recognition, and practical authority. They know when a patient is not right before the numbers look dramatic. They know which process fails after 5 p.m.
A service that loses these nurses loses more than hours. It loses people who steady new staff, challenge unsafe shortcuts, and carry memory from one incident review to the next. Replacement may restore the staffing number while leaving the ward clinically thinner.
Retention review belongs beside quality review. Exit themes, sickness patterns, internal transfers, age profile, overtime, and staff narratives belong in the safety record. A unit that cannot keep experienced nurses is sending a warning.
5.7 What the Reliability Score Adds
The Nursing Care Reliability Score adds structure without replacing professional judgment. Its main value is forcing leaders to examine weak signals together. Staffing adequacy, acuity, skill mix, handover, supervision, missed care, retention, and strain are often reviewed separately. The score places them in one conversation.
False precision remains a risk. A score may appear more objective than it is. Local leaders must keep numbers open to challenge, attach narrative evidence, and avoid using the score to rank units without context. A ward caring for unstable patients cannot be shamed by crude comparison with a steadier service.
Used honestly, the tool can move leaders from vague concern to specific action. It can show whether a unit is surviving through goodwill, whether senior cover is being consumed by task work, or whether missed care has become ordinary. That is enough reason to use it carefully.
5.8 Discussion Summary
The discussion returns to a firm point. Nursing safety is not produced by goodwill after the roster has already failed. It is produced by arrangements that give nurses enough time, skill, authority, and support to notice and respond. Where those arrangements are weak, safety is already compromised before an incident proves it.
Nurse leaders need courage, but courage cannot be romanticized. It must be supported by governance, evidence, and authority. Without that support, the profession asks individual nurses to absorb system failure and calls the exhaustion dedication.
5.9 Accountability Without Scapegoating
Accountability is necessary. Nursing services sometimes confuse it with blame. A nurse who ignores a clear duty needs to be answerable. A nurse placed in an impossible assignment after repeated warnings is in a different position. Mature governance can tell the difference.
Scapegoating feels efficient because it supplies a named cause. The medication was late because a nurse was disorganized. The fall happened because observation was missed. The complaint arose because communication was poor. Sometimes those statements are partly true. They are incomplete if staffing, interruptions, skill mix, handover, and supervision are kept outside the frame.
A better accountability model asks what the individual did, what the team knew, what managers had been told, what senior leaders had authorized, and which conditions were tolerated before the event. That wider view does not excuse poor practice. It prevents organizations from pretending that poor practice appears from nowhere.
5.10 Language as a Safety Tool
Language matters because it shapes what leaders are willing to see. “Pressure” sounds temporary. “Unsafe staffing” requires a decision. “Resilience” flatters the workforce. “Exhaustion” asks why recovery is missing. “Opportunities for improvement” may suit an audit, but it can sound evasive after repeated missed care.
Nurse leaders need to choose words that match reality. Honest wording may create discomfort. Sometimes discomfort is the point. A service cannot correct risks it insists on describing gently. Professional language has to be calm, but calm does not mean diluted.
Chapter 6: Implementation Framework for Nursing Leaders
6.1 Begin with the Shift, Not the Slogan
Implementation has to begin with the shift. Many improvement projects fail because they open with language staff have heard too often: safer care, better teamwork, workforce resilience, excellence culture. Nurses judge those phrases by what happens on the next rota.
A manager can begin with the last four weeks. Which periods carried the highest acuity? Where did admissions cluster? Which shifts lost senior cover? Which care was missed? Which handovers were interrupted? Which staff stayed late? Which risks were escalated, and what answer came back? These questions reveal the operating truth faster than a campaign poster.
The review includes registered nurses, aides, charge nurses, educators, quality staff, and operational leaders. Each group sees a different part of the system. Bedside staff know which work is hidden. Quality teams know which harms are rising. Operational leaders know where demand pressure enters. Implementation fails when one group writes the plan for everyone else.
Table 4. Four-Week Nursing Reliability Review Cycle
| Period | Management action | Expected output |
| Week 1 | Collect baseline evidence on staffing, acuity, skill mix, missed care, turnover, and handover. | A clear local risk picture without blaming individual staff. |
| Week 2 | Hold a unit conversation with nurses, charge nurses, aides, and operational leaders. | Shared interpretation of weak signals and immediate safety pressures. |
| Week 3 | Agree practical controls on assignment, handover, escalation, preceptorship, and senior cover. | Visible changes staff can recognize on the next rota cycle. |
| Week 4 | Escalate unresolved risk to senior nursing and board governance with named follow-up. | Documented accountability rather than informal acceptance of unsafe conditions. |
| Monthly | Repeat the reliability review and compare new evidence with previous weak points. | Pattern recognition rather than one-off reaction after harm. |
6.2 Build a Local Staffing Review
A local staffing review compares planned roster, filled roster, patient acuity, skill mix, temporary staff use, missed breaks, overtime, and missed care. The purpose is not to embarrass a unit. The purpose is to stop treating repeated shortage as surprise.
Managers need a workable rhythm. Weekly review can catch immediate danger. Monthly review shows patterns. Quarterly review can support establishment arguments and retention planning. Annual review is too slow for a unit that is already fraying.
Evidence has to be shown plainly. A ward running below planned staffing every weekend cannot be described as facing intermittent pressure. A service that regularly loses senior cover because charge nurses take assignments need to say so. Language is part of implementation.
6.3 Protect the Charge Nurse Role
Charge nurses often carry the contradiction of modern nursing management. They are expected to coordinate the shift, support new staff, notice deterioration, manage relatives, escalate delays, solve equipment problems, and maintain morale. Then, when staffing is short, they are given a full assignment and expected to lead anyway.
Protecting the charge nurse role is not a luxury. It is a safety control. Someone must be free enough to see the whole ward, rebalance work, respond to uncertainty, and defend handover. A charge nurse buried in task work may be heroic, but the shift has lost its lookout.
Implementation defines when charge nurses can carry patients, when they cannot, and who authorizes exceptions. Repeated exceptions needs to reach senior review. A protected role suspended every week is not protected.
6.4 Make Acuity Visible
Acuity has to be discussed in ordinary language as well as formal tools. Numbers may help, but nurses also need permission to say that a patient requires constant reassurance, that a family needs time, that two confused patients near the nurses’ station are changing the whole shift, or that one discharge will absorb an experienced nurse.
Visible acuity prevents false equivalence. Ten beds do not equal ten beds when one group includes unstable oxygen requirements, isolation precautions, delirium, complex wounds, new insulin teaching, and discharge conflict. A staffing plan that ignores that difference is not neutral. It is unsafe.
Ward-level huddles can bring acuity into the open. The huddle cannot become performance. It needs to identify who is unstable, which tasks must not be missed, where supervision is needed, and what risk requires escalation beyond the ward.
6.5 Use the Reliability Score Carefully
The Nursing Care Reliability Score can support implementation when leaders treat it as a prompt. Each variable is scored with evidence: rosters, acuity notes, agency use, handover interruptions, missed care reports, turnover, sickness, overtime, and staff accounts.
Scores are reviewed with the team. Staff can challenge them. If managers score handover as reliable while nurses describe constant interruption, the disagreement is useful. It shows where the official view and working reality have separated.
Low scores require action, not anxiety. Some fixes may be immediate: protect handover, change assignment, add senior review, stop nonessential transfers during high-risk periods. Other fixes require executive escalation: recruitment, establishment review, retention incentives, or bed-capacity decisions. The score can help distinguish those levels.
6.6 Escalation That Receives an Answer
Escalation is not complete because a manager sent an email. Risk has not been handled until someone with authority responds. Too many nursing concerns disappear into polite acknowledgement. Staff then learn that escalation is ritual, not protection.
A reliable escalation route includes the risk, evidence, immediate control, decision required, person responsible, and review date. Senior leaders may not be able to supply staff instantly, but they can make decisions about admissions, redeployment, temporary cover, supervision, or documented acceptance of risk.
Silence after escalation is governance failure. If the ward has named an unsafe condition and no one answers, responsibility does not remain only with the ward. It travels upward with the ignored warning.
6.7 Support New Staff Without Sacrificing Patients
New nurses need work that teaches without overwhelming them. Services often say they value preceptorship while assigning preceptors full loads and placing new staff into unstable teams. That arrangement is unfair to the new nurse and unsafe for patients.
Implementation protects preceptor time, match new nurses to appropriate assignments, and monitor early warning signs: repeated staying late, avoidance of questions, medication anxiety, documentation delays, conflict with families, or reluctance to escalate. These signs are not personal weakness. They are development needs and safety signals.
Experienced nurses also need support. Teaching while carrying unsafe workload breeds resentment. A service that wants a learning culture must give experienced nurses time to teach properly.
6.8 Keep Governance Close to Care
Governance meetings include evidence from actual shifts. Dashboards are useful, but they can become distant. A fall rate may be stable while nurses report more missed turning. Complaint numbers may be low because families have stopped expecting attention. Governance needs quantitative data and ward testimony together.
Senior nursing leaders need to bring uncomfortable details to the board: where staffing is repeatedly below plan, where agency dependence is high, where missed care is rising, where charge nurses cannot lead, where experienced nurses are leaving. Polished summaries that remove discomfort also remove usefulness.
Implementation succeeds when the organization can see the work honestly. Safer care begins with that sight.
6.9 Practical Audit Questions
A practical audit can begin with questions staff recognize. Which shift last week felt least safe? What made it unsafe? Which patient group required more time than the roster allowed? Where did senior support arrive too late? Which task was repeatedly delayed? Which new staff member needed more help than was available?
Managers compare the answers with formal records. If staff describe repeated missed care but the incident system is quiet, reporting may be weak. If overtime is high but staffing reports look adequate, the roster may be hiding work. If charge nurses repeatedly carry assignments, leadership cover is being consumed.
Audit findings lead to named actions. A vague plan to monitor staffing is not enough. Better actions include protecting one charge nurse per shift, changing admission timing where possible, adding senior review to high-acuity periods, strengthening preceptor allocation, or escalating establishment review with evidence.
6.10 Sustaining the Work
Sustaining improvement is harder than launching it. Early attention can fade once the first report is written. Staff then learn another lesson in disappointment. Nursing reliability work needs a rhythm: review, action, feedback, adjustment, and renewed review.
Feedback to staff is crucial. Nurses who report missed care or staffing risk need to hear what happened next. Even when the answer is limited, visible response matters. Silence teaches cynicism. Response teaches that professional voice still has value.
6.11 Making Improvement Visible
Visible improvement does not require a ceremony. Staff notice when handover is actually protected, when a senior nurse arrives before the shift collapses, when agency nurses receive useful orientation, and when a difficult escalation receives a clear answer. Small corrections rebuild trust faster than broad promises.
Measurement needs to follow those corrections. Leaders can track whether interruptions fell, whether charge nurses remained available, whether missed care reduced, and whether staff felt safer naming risk. Improvement becomes credible when nurses can point to changes in the work, rather than only to changes in the report.
Chapter 7: Sector-Specific Application
7.1 Acute Care
Acute care tests nursing management through speed and complexity. Admissions arrive, discharges stall, patients deteriorate, scans interrupt routines, and families need answers. A safe roster in acute care is not built by headcount alone. It needs enough registered judgment, senior cover, and flexibility to absorb sudden change.
Medication safety shows the point. A medicine round may fail through poor knowledge, but also through interruption, overload, unfamiliar staff, unclear orders, or competing demands. Good management reduces those conditions. It protects the round, supports new staff, controls avoidable interruption, and ensures that a nurse who is unsure can stop and ask.
Acute units also need disciplined escalation. Bed pressure can push unsafe transfers, rushed discharge teaching, and thin observation. Nurse leaders need to document when flow pressure creates clinical risk. The record cannot be hostile. It has to be accurate enough to protect patients and staff.
7.2 Emergency and Urgent Care
Emergency nursing carries a different rhythm. Demand is unpredictable, acuity changes quickly, and patients may arrive without history, diagnosis, or trust. Triage, waiting-room surveillance, escalation, and rapid reassessment become central management concerns.
Staffing in urgent care settings must account for visible and hidden work. A patient sitting quietly may be deteriorating. A relative may be the only reliable historian. Mental-health distress, intoxication, safeguarding concerns, and violence risk all change the staffing requirement. A roster built only around average attendance misses the danger.
Team communication matters sharply here. Brief huddles, clear role allocation, and senior clinical presence can prevent drift. Still, communication tools cannot compensate for a waiting room that has outgrown the team’s capacity to observe it safely.
7.3 Long-Term Care
Long-term care tests whether a system respects dependency that is not dramatic. Residents need continence support, food, hydration, turning, conversation, memory care, mobility help, and protection from loneliness and neglect. Thin staffing turns these needs into a queue.
The federal staffing debate shows how hard the issue is. Minimum hours may create a needed floor, but resident acuity, workforce supply, rural access, and financing cannot be wished into place. Policy need to protect residents without pretending that providers can hire nurses who do not exist locally.
Facility assessment is crucial. Leaders show how resident need shapes staffing, not simply whether a rule was technically met. Dementia care, bariatric care, wound burden, end-of-life support, behavioral risk, and family involvement all affect the work. A resident does not become easier to care for because a spreadsheet lacks a column.
7.4 Community and Home-Based Nursing
Community nursing spreads risk across distance. A nurse may move from house to house carrying clinical judgment, safeguarding awareness, teaching responsibility, and documentation demands without immediate ward-team support. Management has to account for travel, lone-working risk, equipment, digital access, and the emotional weight of entering private homes.
Missed care looks different outside institutions. A visit is shortened. Teaching is deferred. A wound review is pushed to tomorrow. A caregiver’s exhaustion is noticed but not addressed because the schedule is already late. These omissions may not appear in the same metrics as hospital incidents, yet they shape safety.
Community leaders need strong escalation routes. Nurses working alone cannot be left to carry complex risk privately. Safeguarding, deterioration, medication uncertainty, family conflict, and environmental danger require fast access to senior advice.
7.5 Mental Health and Learning Disability Services
Mental health and learning disability nursing require enough time for observation, relationship, de-escalation, and communication that may not follow standard routines. Staffing adequacy must reflect emotional labor, behavioral risk, legal duties, family work, and skilled presence.
A ward may look calm while risk is rising. Withdrawal, agitation, self-neglect, medication refusal, family conflict, or a small change in routine can carry meaning. Nurses need time to notice and interpret those signals. Surveillance in this setting is often relational as well as physical.
Management protects reflective discussion and senior support. Staff working with distress, trauma, aggression, or complex communication need space to think. Treating reflection as a luxury misunderstands the work.
7.6 Maternal, Child, and Family Services
Maternal and child health services depend on trust, teaching, early recognition, and safeguarding. A rushed interaction can miss domestic violence, feeding difficulty, postnatal depression, medication uncertainty, or a parent who nods politely without understanding the plan.
Staffing has to allow nurses and midwives to speak with families properly. Education is not a leaflet handed over at the door. It requires checking understanding, reading fear, and adapting language. Families remember whether they felt seen when they were most vulnerable.
Managers need to watch for missed relational care in these services. It may not look like a medication error, but it can shape outcomes. A parent who leaves confused may return later with a preventable crisis.
7.7 Education, Preceptorship, and Academic Settings
Nursing education cannot be separated from service conditions. Learners may be taught best practice in the classroom and then meet a placement where staff are too rushed to demonstrate it. That gap damages confidence and can normalize unsafe shortcuts early in a career.
Preceptorship belongs as workforce protection. New nurses who are supported well become safer and are more likely to stay. Poor transition support wastes education investment and places pressure on already strained teams.
Academic and service leaders need to work together on realistic preparation: prioritization, escalation, documentation, delegation, family communication, and managing uncertainty. Clinical knowledge matters, but the early nurse also needs help surviving the organized reality of care.
7.8 Rural and Under-Resourced Settings
Rural and under-resourced settings expose the limits of generic staffing advice. Recruitment may be slow, agency cover scarce, travel long, and specialist support distant. A policy written for a large urban system may not fit without adaptation.
Adaptation cannot mean lower expectations for dignity or safety. It means honest workforce planning, regional cooperation, telehealth support where appropriate, retention incentives, stronger generalist preparation, and escalation routes that acknowledge distance.
Leaders in these settings often know risk well because they live close to it. Their evidence deserves attention. Rural difficulty must not become a polite excuse for invisible harm.
7.9 Application Across Settings
Every sector changes the form of nursing risk, but the management question remains recognizable. Does available skill match actual need? Is supervision real? Is handover protected? Are omissions named? Are staff leaving? Does escalation receive an answer?
Sector-specific application therefore strengthens the central argument. Nursing management is patient-safety work wherever nursing time, judgment, and voice determine whether people receive care in time and with dignity.
7.10 Transitions of Care
Transitions of care deserve separate attention because risk often crosses boundaries. Hospital to home, emergency department to ward, ward to rehabilitation, long-term care to hospital, and community service to specialist clinic all depend on nursing communication that is usually compressed by time.
Unsafe transition rarely looks dramatic at the point of handoff. A medication change is not understood. A wound plan is incomplete. A family is unsure who to call. A resident returns from hospital with new instructions that do not fit the staffing pattern of the home. Harm may appear days later, far from the moment when the weakness entered the system.
Managers need to treat transitions as shared nursing work. Receiving teams need enough information, sending teams need time to teach, and both sides need escalation routes when the plan is unclear. A discharge target met by sacrificing understanding is not a safety success.
7.11 Technology and Digital Documentation
Digital systems can support nursing management, but they can also hide workload. Electronic records, acuity tools, rostering platforms, and dashboards may make information easier to collect. They do not automatically make care safer.
Nurses often spend time feeding systems that senior leaders then use to judge performance. That exchange is fair only when the system returns value to the ward. If documentation expands but staffing does not, digital improvement may become another claim on nursing time.
Technology has to be judged by whether it helps nurses notice risk earlier, communicate more clearly, reduce duplication, and escalate danger. A beautiful dashboard that leaves the bedside thinner has failed the practical test.
Chapter 8: Closing Position and Recommendations
8.1 Closing Position
Nursing safety is built in ordinary decisions that rarely attract ceremony. The roster is checked. The experienced nurse is kept free to lead. A new nurse is supervised. Handover is not sacrificed to hurry. Missed care is named. A family receives explanation before discharge. A resident is turned before skin breaks. A concern reaches someone with authority and receives an answer.
Amadi’s central position is that nursing organizational management belongs at the center of patient safety. It is not administration around the clinical service. It is part of the clinical service. Patients receive the consequences of staffing, supervision, retention, communication, and leadership whether or not they ever see those words.
No serious health service can praise nurses for resilience while building work that depends on exhaustion. Resilience may help a professional endure a difficult season. It cannot become the operating model.
8.2 Recommendations for Nurse Managers
Nurse managers review staffing adequacy by shift and acuity, not by establishment alone. Every review need to ask whether the team had enough registered judgment, enough support staff, enough familiarity, and enough senior cover for the patients present.
Missed care belongs in the record as safety intelligence. A delayed bath may not appear urgent, yet repeated omissions reveal the service’s true capacity. Managers need a non-punitive way to hear what was left undone and why.
Handover and charge nurse availability deserve protected status. If an organization claims to value escalation while giving the charge nurse no time to lead, the claim is false. Leadership must exist in the shift, not just in the job description.
8.3 Recommendations for Senior Executives and Boards
Boards treat nursing staffing as clinical risk rather than labor cost alone. Reports needs to include staffing adequacy, acuity pressure, temporary staff use, missed care, turnover, preceptorship strain, sickness, overtime, and unresolved escalations.
Executives need to answer escalations visibly. A manager who reports unsafe conditions needs to receive a decision, not sympathy alone. When resources cannot be supplied immediately, temporary controls need to be agreed and documented. Governance fails when risk is passed downward until bedside staff carry it alone.
Retention belongs as a safety metric. Losing experienced nurses weakens judgment, memory, supervision, and culture. Exit data, sickness trends, internal transfers, age profile, and staff narratives need to be read together.
8.4 Recommendations for Education and Professional Development
Nursing education providers and service leaders align more closely around transition to practice. New nurses require strong clinical placement, realistic preparation for workload, protected preceptorship, and early support in escalation, prioritization, communication, and documentation.
Continuing development for nurse leaders includes staffing analysis, acuity interpretation, conflict management, quality governance, data use, workforce planning, and board-level communication. A nurse manager promoted for clinical excellence may still need support in organizational authority.
Team training has to be tied to local operating conditions. TeamSTEPPS 3.0 and similar programs are useful when leaders protect the behaviors they teach. Training without protected handover, usable escalation, and senior support produces attendance records rather than safer teams.
8.5 Recommendations for Policy and Regulation
Policy makers avoid two easy mistakes. One is writing staffing rules as if labor supply and provider capacity do not matter. The other is abandoning patient and resident protection because implementation is hard. Serious policy holds both truths.
Minimum standards can create a floor, but they cannot replace local acuity judgment. Regulation requires providers to show how staffing decisions reflect actual need. Documentation of staffing adequacy, missed care, turnover, and escalation can make risk harder to hide.
Rural and under-resourced providers need specific support: training pipelines, retention incentives, regional staffing cooperation, loan repayment, technology support, and targeted funding. Equity means patients outside major centers are not treated as acceptable casualties of scarcity.
8.6 Publication Standard for Practice Use
A publication on nursing management has little value if it cannot survive contact with practice. The argument offered here is meant for nurse managers, senior nurses, directors, educators, quality leads, and graduate learners who need language strong enough to defend care but practical enough to use.
Every recommendation returns to a professional demand: name the work honestly. Name the acuity. Name the missed care. Name the lack of senior cover. Name the retention loss. Name the handover risk. Name the difference between a difficult shift and an unsafe arrangement. Naming does not solve the problem by itself, but silence keeps the problem comfortable for people who are not carrying it.
NYCAR publication readiness requires more than clean formatting. It requires structure, evidence, restraint, and a voice that understands the work. A paper on safety cannot be disordered. A paper on nursing cannot sound detached from nurses. A paper using a model must not overclaim what the model can do.
8.7 Final Quality Position
The Nursing Care Reliability Score remains limited by design. It helps leaders organize review. It does not predict harm, replace local judgment, or certify a service as safe. That restraint strengthens the work. Overclaiming would weaken it.
Final judgment is difficult to avoid. Do not call nursing care safe until the conditions of nursing work have been examined honestly. Patients do not receive strategy documents. They receive the consequences of staffing, supervision, communication, and leadership.
Nothing in that demand is fashionable. It is ordinary, stubborn, and difficult to fake. A service either protects nurses’ capacity to care or consumes that capacity while praising their commitment. Patients deserve the first option. Nurses do as well.
8.8 What Must Not Be Lost
Several points cannot be lost in the final reading. Staffing is not just a finance matter. Acuity is not a technical detail. Skill mix is not a substitution game. Handover is not a courtesy. Missed care is not a private embarrassment. Retention is not simply human-resources work. Each belongs to patient safety.
Nursing leaders also need institutional protection. Asking managers to speak honestly while punishing discomfort is a recipe for silence. A director who wants safer care must make room for difficult evidence. A board that wants assurance must be willing to hear why assurance is not yet justified.
The profession resists management language that praises nurses while consuming them. Care cannot be built on permanent rescue. If nurses have to keep saving the system from its own arrangements, the arrangements are the problem.
8.9 Closing Reflection
Martha N. Amadi’s contribution rests in making a familiar truth difficult to avoid: nursing care depends on how nursing work is organized. The statement sounds simple. Many services still behave as though compassion can compensate for poor staffing, communication training can compensate for unprotected handover, or recruitment can compensate for a culture that drives experienced nurses away.
Better nursing management does not require theatrical leadership. It requires accurate rosters, honest acuity review, protected senior cover, supported new staff, reliable handover, open reporting of missed care, and executives who answer risk rather than admire endurance. These are ordinary disciplines. Their ordinariness is exactly why they matter.
Patient safety begins before the alarm sounds. It begins when leaders decide whether the conditions of nursing work are safe enough for the care they expect nurses to deliver. That decision is made every day, whether it is named or not.
Serious nursing management does not need decoration. It needs enough honesty to protect the next patient before the next incident writes the lesson more painfully. The test is not whether the report sounds confident; it is whether the next shift has enough time, skill, and authority to care safely.
References
Agency for Healthcare Research and Quality. (n.d.). TeamSTEPPS 3.0 curriculum materials. https://www.ahrq.gov/teamstepps-program/curriculum/index.html
Aiken, L. H., Sloane, D. M., McHugh, M. D., Pogue, C. A., & Lasater, K. B. (2023). A repeated cross-sectional study of nurses immediately before and during the COVID-19 pandemic: Implications for action. Nursing Outlook, 71(1), 101903. https://doi.org/10.1016/j.outlook.2022.11.007
American Nurses Credentialing Center. (n.d.). ANCC Magnet Model. American Nurses Association. https://www.nursingworld.org/organizational-programs/magnet/magnet-model/
Centers for Medicare & Medicaid Services. (2024). Medicare and Medicaid programs: Minimum staffing standards for long-term care facilities and Medicaid institutional payment transparency reporting. https://www.cms.gov/newsroom/fact-sheets/medicare-and-medicaid-programs-minimum-staffing-standards-long-term-care-facilities-and-medicaid-0
Dall’Ora, C., Ball, J., Reinius, M., & Griffiths, P. (2020). Burnout in nursing: A theoretical review. Human Resources for Health, 18, 41. https://doi.org/10.1186/s12960-020-00469-9
Dall’Ora, C., Saville, C., Rubbo, B., Turner, L., Jones, J., & Griffiths, P. (2022). Nurse staffing levels and patient outcomes: A systematic review of longitudinal studies. International Journal of Nursing Studies, 134, 104311. https://doi.org/10.1016/j.ijnurstu.2022.104311
Department of Health and Human Services & Centers for Medicare & Medicaid Services. (2025). Medicare and Medicaid programs: Repeal of minimum staffing standards for long-term care facilities. Federal Register, 90(230), 55687–55700. https://www.federalregister.gov/documents/2025/12/03/2025-21792/medicare-and-medicaid-programs-repeal-of-minimum-staffing-standards-for-long-term-care-facilities
Lasater, K. B., Aiken, L. H., Sloane, D. M., French, R., Anusiewicz, C. V., Martin, B., Alexander, M., & McHugh, M. D. (2021). Chronic hospital nurse understaffing meets COVID-19: An observational study. BMJ Quality & Safety, 30(8), 639–647. https://doi.org/10.1136/bmjqs-2020-011512
NHS England. (2023). NHS long term workforce plan. https://www.england.nhs.uk/publication/nhs-long-term-workforce-plan/
Smiley, R. A., Kaminski-Ozturk, N., Reid, M., Burwell, P. M., Oliveira, C. M., Shobo, Y., Allgeyer, R. L., Zhong, E., O’Hara, C., Volk, A., & Martin, B. (2025). The 2024 National Nursing Workforce Survey. Journal of Nursing Regulation, 16(1), S1–S88. https://doi.org/10.1016/S2155-8256(25)00047-X
World Health Organization. (2025). State of the world’s nursing 2025: Investing in education, jobs, leadership and service delivery. World Health Organization. https://www.who.int/publications/i/item/9789240110236