

A Master’s-Level Case Study of Amazon Web Services
Research Publication by Joy Anoshiri
Institutional Affiliation: New York Center for Advanced Research (NYCAR)
Publication No.: NYCAR-TTR-2026-RP025
DOI: https://doi.org/10.5281/zenodo.20448831
Copyright © June 2026 New York Center for Advanced Research (NYCAR) and Joy Anoshiri. All rights reserved.
Peer Review Status
This research paper was reviewed and approved under the internal editorial peer review framework of the New York Center for Advanced Research (NYCAR) and The Thinkers’ Review. The process was handled independently by designated Editorial Board members in accordance with NYCAR’s Research Ethics Policy.
Abstract
Cloud enterprises now sit inside the operating life of banks, hospitals, universities, retailers, media companies, government agencies, and artificial intelligence services. Because these organizations increasingly rely on cloud platforms to keep core activity running, service quality in the cloud can no longer be treated as a narrow engineering concern. It is a governance issue that connects reliability, security, continuity, cost control, incident communication, customer accountability, and executive trust. This paper examines digital operations governance and service quality through the case of Amazon Web Services (AWS), using public AWS documentation, Amazon reporting, service management literature, secure software guidance, and scenario-based operations mathematics.
The study uses a mixed-methods case-study design. Qualitative analysis evaluates AWS customer-facing guidance on operational excellence, reliability, shared responsibility, service-level commitments, cost discipline, and security. Quantitative modeling applies availability calculation, queueing utilization, capacity headroom analysis, mean response time, and a cloud service-quality index. These calculations are not presented as AWS internal data. They are used to demonstrate how managers can interpret service quality without reducing the customer experience to a single uptime percentage.
The paper argues that service quality in cloud enterprises is co-produced. AWS can provide scale, service controls, regional resources, monitoring tools, security services, and formal commitments, but customers still shape the experienced quality through configuration, identity management, recovery testing, observability, spending discipline, and their own application design decisions. The findings show that mature cloud governance depends on disciplined operating routines, clear responsibility boundaries, transparent communication, and practical measurement. The study concludes that cloud quality is strongest when availability, security, performance, support responsiveness, cost visibility, and customer readiness are governed together.
Keywords: cloud operations governance, Amazon Web Services, service quality, reliability, uptime, queueing utilization, capacity planning, incident response, shared responsibility, digital operations management
Chapter 1: Introduction
1.1 Background and Context
Cloud computing has become a routine part of modern life, even when users do not recognize it as cloud computing. A card payment clears, a hospital record loads, a payroll file is processed, a logistics dashboard refreshes, a news platform streams video, and a student enters a learning portal. In each moment, the user cares less about the technical location of the system than about whether the service is available, responsive, secure, and understandable when problems occur. The cloud works best when it fades into the background. That quiet role creates a management problem: when a platform is invisible during normal operation, its value may be appreciated only when it fails.
1.2 Governance Problem
The managerial importance of cloud service quality has intensified because cloud platforms now support activities that cannot easily pause. A short disruption may delay clinical workflows, interrupt retail sales, affect financial transactions, or block public services. Even when formal downtime is brief, the practical consequences can be wider than the measured incident. Customers may spend hours checking dependent systems, communicating with their own users, investigating data integrity, or reassuring executives. The technical event becomes an organizational event. Cloud operations governance therefore has to be judged by whether an incident ends and by how effectively risk was anticipated, communicated, contained, and learned from.
1.3 Case Rationale
Amazon Web Services is a useful case for master’s-level operations analysis because it is both large and unusually visible in public documentation. AWS publishes customer guidance on operational excellence, reliability, security, cost optimization, and service-level commitments, while Amazon’s public reporting presents AWS as a major business segment rather than a supporting technology function inside a retail company (Amazon Web Services, 2024a, 2024b, 2025; Amazon.com, Inc., 2026). The case is not used here as a promotional profile or as a claim that AWS is free from operational weakness. It is used because AWS provides enough public material to examine how a major cloud enterprise frames service quality for customers and for the market.
1.4 Conceptual Definition
Digital operations governance, as used in this study, refers to the management system that organizes decision rights, accountability, risk controls, measurement, incident response, communication, cost discipline, customer education, and post-incident learning. In cloud enterprises, this governance cannot be contained within one technical team. It crosses engineering, security, finance, customer success, legal, communications, product management, and executive leadership. It also crosses the boundary between provider and customer. A cloud provider may operate infrastructure and managed services, yet the customer’s identity controls, backup practices, network choices, workload configuration, and application behavior influence the quality the end user experiences.
1.5 Service Quality Beyond Availability
Service quality in the cloud is often summarized by availability, but availability is only one dimension of quality. A platform may meet a formal monthly uptime commitment while customers still experience poor communication, slow support, confusing cost signals, weak recovery preparation, or inadequate guidance around risk. A narrow availability view can make cloud management look more mature than it is. A stronger view asks whether the service is reliable under stress, whether performance is consistent enough for the workload, whether security responsibilities are clear, whether recovery expectations are realistic, whether customers can understand their costs, and whether communication is credible during pressure.
1.6 Purpose, Objectives, and Research Questions
The purpose of this paper is to examine how digital operations governance supports service quality in cloud enterprises, using AWS as the principal case. The study asks how public AWS guidance expresses operational discipline, how shared responsibility affects the quality boundary, how service-level agreements should be interpreted, and how practical mathematics can help leaders manage service risk. The analysis also recognizes the limits of public evidence. No claim is made that this paper has access to AWS internal incident logs, proprietary capacity plans, confidential customer support tickets, or private performance data. Scenario modeling is used to explain management logic, not to report internal company performance.
The research objectives are to analyze AWS as a cloud operations governance case, evaluate the relationship between governance and service quality, apply operations mathematics to reliability and support pressure, identify the limits of service-level commitments, and develop recommendations for managers who depend on cloud services. The research questions are: how does cloud operations governance shape service quality; what does AWS reveal about reliability, shared responsibility, customer guidance, and service commitments; which quantitative indicators help leaders interpret cloud service performance; how can managers avoid reducing quality to uptime; and what practices protect customer trust when platforms operate at large scale?
1.7 Significance of the Study
This study is significant because cloud dependency has become a general organizational condition rather than a specialist technology issue. Health systems, schools, banks, local governments, logistics firms, research centers, and digital media organizations now build essential work around cloud services. The resilience of those services affects continuity, reputation, compliance, user safety, and public confidence. For Joy Anoshiri’s master’s-level research, the topic connects digital operations with service management, risk governance, and executive responsibility. The central claim is direct: cloud enterprises cannot sustain trust through scale alone. They need governance practices that turn scale into reliable, secure, explainable, and recoverable service.
Chapter 2: Literature Review and Case Context
2.1 Operations Quality in Digital Services
Operations management literature has long treated quality as a system property rather than a single inspection result. In manufacturing, quality may be visible in defect rates, process variation, rework, and customer returns. In digital services, the signs are more fluid. Quality appears through availability, latency, error rates, support responsiveness, security posture, change failure, cost predictability, and customer confidence. Cloud computing raises the difficulty because services are distributed, continuously consumed, software-driven, and highly interdependent. A customer may experience failure even when the cloud provider’s underlying system is functioning, because the customer’s configuration, code, data path, or external dependency has broken.
2.2 Service Quality Theory
Service quality theory helps widen the analysis beyond internal technical performance. Parasuraman, Zeithaml, and Berry’s SERVQUAL work is not a cloud computing study, but its emphasis on perceived quality remains relevant because customers judge services through reliability, responsiveness, assurance, empathy, and tangible cues (Parasuraman et al., 1988). In cloud operations, the tangible cue may be a status page, a console, a support response, a usage alert, or the clarity of documentation. A technically strong platform can still disappoint customers when support feels slow, explanations are opaque, or billing lacks transparency. Perceived quality therefore belongs in the cloud governance discussion rather than being dismissed as subjective noise.
2.3 Software Quality and Cloud Platforms
Software quality models also support a multidimensional view. ISO/IEC 25010:2023 defines quality characteristics for software and information technology products, including functional suitability, performance efficiency, compatibility, usability, reliability, security, maintainability, flexibility, and safety (International Organization for Standardization, 2023). Although a cloud platform is more complex than a single software product, the model helps managers resist the habit of treating uptime as the whole picture. A service can be available but difficult to configure safely, compatible only with costly workarounds, or hard to recover after a customer error. Quality characteristics interact. Reliability without usability may still produce operational risk because customers make mistakes when controls are hard to understand.
2.4 Site Reliability Engineering
The site reliability engineering literature adds a further practical discipline. SRE stresses error budgets, service-level objectives, toil reduction, monitoring, incident response, and learning from failure (Beyer et al., 2016). Its relevance for cloud enterprises lies in the recognition that reliability is not a vague aspiration. It has to be negotiated, measured, and operated. The SRE tradition is also useful because it does not imagine that failure can be eliminated. Instead, it asks what level of unreliability is tolerable, how fast teams can detect and respond to problems, how changes are controlled, and how the organization learns before repeated incidents become accepted background noise.
2.5 DevOps and Delivery Discipline
DevOps research complements SRE by connecting software delivery practices with organizational performance. The DORA research program has made deployment frequency, lead time for changes, change failure rate, and time to restore service common measures in software organizations (Forsgren et al., 2018; Google Cloud DORA, 2024). These measures matter in a cloud enterprise because customer-facing quality is affected by how frequently systems change, how safely changes are released, and how quickly service is restored after disruption. Fast delivery by itself is not quality. Speed becomes valuable when it is paired with stability, observability, and a disciplined learning culture.
2.6 AWS Operational Guidance
AWS public guidance reflects many of these ideas in customer-facing form. The AWS Well-Architected operational excellence pillar describes practices for organizing teams, operating workloads at scale, learning from operational events, and improving over time. The reliability pillar stresses the ability of workloads to perform correctly and consistently through their life cycle, including recovery from failure (Amazon Web Services, 2024a, 2024b). These materials matter for governance because they make service quality a shared managerial responsibility. They tell customers that buying cloud resources is not the same as operating a reliable cloud service. Cloud value depends on how the resources are designed, monitored, secured, tested, and improved.
2.7 Shared Responsibility
Shared responsibility is one of the most important concepts in cloud operations governance. AWS operates the cloud, while customers are responsible for what they run in the cloud, with the exact boundary depending on the service model. This distinction is more than legal language. It determines who must configure access permissions, encrypt data, design backup routines, monitor workload health, patch systems, manage credentials, and test recovery. Customers can create serious risk even on a strong platform if they misunderstand their responsibilities. In this sense, the provider’s service quality and the customer’s operating maturity are linked in the end user’s experience.
2.8 Service-Level Agreements
Service-level agreements give a formal contractual frame to availability, but they are limited tools for quality management. AWS publishes service-level agreements for generally available paid services, and the Amazon Compute SLA states commercially reasonable efforts to make Amazon EC2 available in each AWS region with a monthly uptime percentage of at least 99.99 percent (Amazon Web Services, 2022, 2025). That commitment is significant, but a service credit is not the same as full restoration of business value. A customer may face lost sales, staff overtime, compliance exposure, reputational damage, or downstream support pressure that exceeds the credit. Managers should treat SLAs as minimum commitments, not as a sufficient definition of quality.
2.9 Security as Service Quality
Security literature also belongs in a paper on service quality because confidentiality, integrity, and availability are intertwined. NIST’s Secure Software Development Framework encourages practices that reduce vulnerabilities across the software development life cycle (National Institute of Standards and Technology, 2022). In cloud enterprises, weak security can become a service-quality failure even when no traditional outage occurs. A compromised credential, overly permissive storage setting, insecure deployment pipeline, or exposed administrative interface can reduce customer trust and disrupt service. Customers do not experience security and service quality as separate domains. They experience both as the ability of the service to protect their work.
2.10 AWS Case Context
AWS’s case context includes both capability and concentration risk. Amazon’s public reporting shows AWS as a large and profitable segment, and its market role means that many organizations build important workloads on AWS services (Amazon.com, Inc., 2026). Scale brings advantages: large engineering teams, global infrastructure, specialized services, extensive monitoring, and broad customer guidance. Scale also means that operational events can have visible consequences across many dependent organizations. The case therefore supports a balanced analysis. It shows how mature cloud governance can be documented and taught, while also reminding managers that complexity never disappears.
2.11 Operations Learning
The literature on operations learning reinforces this balanced view. Mature operations teams do not simply restore service and move on. They examine precursor signals, decision paths, escalation delays, test gaps, communication weaknesses, and repeatable prevention opportunities. Post-incident review becomes a governance mechanism rather than an exercise in blame. For cloud enterprises, the learning loop must include both internal teams and customers. Customer misunderstandings, weak implementation patterns, and recurring configuration mistakes can reveal gaps in documentation, onboarding, product defaults, or warning systems. A provider that learns only from internal telemetry but ignores customer confusion will miss part of service quality.
2.12 Cost Governance
Cost management is sometimes placed outside service quality, but in cloud operations it belongs within the customer experience. Pay-as-you-go services can create agility, yet unpredictable bills can undermine trust. A customer who cannot explain a sudden cost increase to executives may view the platform as risky, even if the service remains technically available. AWS guidance on cost optimization, tagging, budgets, and usage visibility reflects this point. Cost clarity allows customers to operate with control. Without it, operational quality is experienced as uncertainty.
2.13 Literature Synthesis
Read together, the literature and AWS case context show that cloud service quality is a cross-functional discipline. Reliability, performance, security, usability, responsiveness, communication, recoverability, and cost transparency are linked. Weakness in one domain can reduce confidence in the rest. A highly available service that is poorly explained during incidents may still lose trust. A secure service that is too difficult for customers to configure correctly may produce preventable exposure. A low-cost workload that lacks recovery testing may become expensive during failure. Cloud quality therefore has to be governed as a living operating system of management choices.
Read also: Digital Pathology, Diagnostic Safety, and Workforce Sustainability
Chapter 3: Methodology
3.1 Research Design
This paper uses a mixed-methods case-study design. AWS provides the organizational case, and cloud service quality provides the management phenomenon under examination. The qualitative component analyzes public AWS materials, Amazon reporting, service-level statements, operations management literature, secure software guidance, and service quality scholarship. The quantitative component develops scenario-based indicators that show how managers can reason about availability, support pressure, capacity use, response time, and multi-dimensional quality. The combination is appropriate because cloud governance is both interpretive and numerical. Leaders need to understand the language of responsibility and the behavior of measurable systems.
3.2 Case Selection
Case selection is purposeful rather than random. AWS is selected because it is a major cloud provider with extensive public documentation on operational guidance, reliability, security, shared responsibility, service-level commitments, and customer support. The case is also useful because AWS is large enough to raise questions about scale, dependency, and concentration risk. A smaller provider might offer an interesting operational story, but the AWS case gives a richer base for examining how cloud service quality is communicated to customers and how managers can interpret cloud operations at enterprise scale.
3.3 Evidence Base
The study relies only on publicly available information. Sources include Amazon’s annual reporting, AWS service-level materials, AWS guidance on operational excellence and reliability, NIST secure software guidance, ISO/IEC software quality guidance, SRE and DevOps literature, and service quality theory. The paper does not use confidential AWS records, private customer contracts, internal incident reports, unpublished capacity data, or proprietary ticketing information. This boundary protects validity by preventing the analysis from implying access it does not have. Public evidence supports the case interpretation; scenario mathematics supports management reasoning.
3.4 Qualitative Procedure
The qualitative method is document and case analysis. Public materials are read for the way they define responsibility, guide customers, frame reliability, describe service commitments, and position operational improvement. The analysis is not limited to whether AWS has a policy or a document. It asks what managerial logic the documents express. For example, shared responsibility is examined as a formal model and as a practical governance challenge. A customer must know which risks remain with the customer, which controls the provider supplies, and how responsibility changes across infrastructure, platform, and managed services.
3.5 Scenario-Based Operations Modeling
The quantitative method uses five practical measures. Uptime percentage estimates availability. Queueing utilization estimates support or incident response pressure when demand approaches service capacity. Capacity use measures the relationship between used capacity and available capacity. Mean response time evaluates the speed of the first operational response. A cloud service-quality index combines reliability, performance, security posture, customer communication, and cost transparency. These measures are simple enough for managers to understand, but strong enough to show why a single metric cannot capture cloud service quality.
3.6 Availability Logic
Uptime percentage is expressed as U = ((Total Time – Downtime) / Total Time) × 100. This calculation is widely recognized and useful because availability is a central customer expectation. Its weakness is that it can hide context. Twelve minutes of downtime at a quiet hour may differ from twelve minutes during peak transaction demand. It also may not capture degraded service, regional dependency, data inconsistency, or the customer’s own recovery burden. For that reason, uptime is treated here as necessary but insufficient.
3.7 Queueing Utilization
Queueing utilization is expressed as ρ = λ / μ, where λ is the arrival rate and μ is the service rate. The value of this measure lies in its warning behavior. As utilization approaches one, waiting time can rise sharply. A support organization that looks efficient at 80 percent utilization can become strained when demand spikes without a matching increase in response capacity. In cloud operations, queueing logic applies to customer support, incident triage, security reviews, deployment approvals, and operational escalation. It shows why using every available unit of capacity may produce fragility rather than excellence.
3.8 Capacity Headroom
Capacity use is expressed as CU = Used Capacity / Available Capacity × 100. In cloud management, capacity has several forms: compute, storage, network throughput, database connections, specialized processing resources, support staffing, and regional failover ability. High capacity use may appear financially disciplined, but if headroom is too narrow, the service may struggle during demand surges or recovery events. Low capacity use may indicate waste. The governance problem is not to maximize or minimize utilization. It is to align headroom with workload volatility, customer impact, and risk appetite.
3.9 Response-Time Logic
Mean response time is expressed as MRT = Total First-Response Time / Number of Incidents. This measure is not the same as resolution time, but it strongly influences customer confidence. During an incident, customers often need acknowledgement, status, scope, and practical next steps. A fast but vague response is not enough; however, a slow response can make a technically competent recovery feel disorganized. Measuring first response helps leaders see whether incident communication is keeping pace with operational impact.
3.10 Cloud Service-Quality Index
The cloud service-quality index is expressed as CSQI = 0.30R + 0.20P + 0.20S + 0.15C + 0.15T. R represents reliability, P performance, S security posture, C customer communication, and T cost transparency. Each component is normalized on a 0–100 scale. The weights are scenario weights chosen for management illustration, not universal law. A healthcare workload may assign more weight to availability and safety; an analytics workload may give more weight to performance and cost transparency. The index is valuable because it forces leaders to discuss quality as a portfolio of outcomes.
3.11 Validity and Evidence Boundaries
Validity is strengthened by separating evidence types. Public documents support statements about AWS guidance and formal commitments. Peer-reviewed and professional sources support the theoretical framing. Scenario calculations support managerial interpretation. The paper avoids treating scenario values as actual AWS results. This distinction matters because a case study can lose credibility when it overstates what public data can prove. The analysis therefore remains transparent about what is known, what is modeled, and what is inferred.
3.12 Limitations
Limitations remain. Public documentation cannot reveal full internal decision-making, staffing levels, vendor dependencies, real-time incident coordination, or the complete experience of every AWS customer. Scenario models simplify reality, and weights in an index involve judgment. Still, the method is useful for master’s-level research because it converts a broad topic into an accountable management analysis. It allows cloud service quality to be discussed with both evidence and operational mathematics.
Chapter 4: Case Analysis: AWS and Digital Operations Governance
4.1 AWS Governance Guidance
AWS demonstrates cloud governance through a large body of customer-facing guidance. The importance of this guidance is not limited to instruction. It signals that the provider understands service quality as a shared operating practice. AWS does not simply sell compute, storage, database, analytics, security, and artificial intelligence services. It also teaches customers how to think about operational excellence, reliability, security, performance efficiency, cost discipline, and sustainability. That teaching role is part of the service relationship because many failures in cloud environments arise from weak implementation rather than from a complete provider outage.
4.2 Operational Excellence
Operational excellence is visible in the way AWS guidance stresses preparation, observability, routine operations, event response, and continuous improvement. In practical management terms, this means quality is not produced only during incidents. It is produced by the daily routines that precede them: change review, deployment testing, monitoring thresholds, access management, runbooks, capacity forecasts, backup verification, and clear escalation paths. A cloud customer that has not practiced recovery should not assume that recovery will be smooth when the service is under stress. The provider can supply tools, but the customer must turn tools into disciplined work.
4.3 Reliability Governance
Reliability guidance in the AWS case rests on a mature assumption: failure is possible, so workloads should be able to continue, degrade safely, or recover. This is an important departure from a purely preventive view of quality. Prevention matters, but cloud services operate in environments where software changes, usage patterns, dependency chains, and security threats are constantly moving. A strong reliability posture asks whether the workload can withstand component failure, whether monitoring will detect trouble early, whether data recovery has been tested, whether regional dependencies are understood, and whether customers have chosen suitable service configurations for their risk profile.
4.4 Shared Responsibility Boundary
The shared responsibility model is the clearest governance boundary in the case. AWS is responsible for the security and operation of the cloud infrastructure and managed service components under its control. Customers remain responsible for their own data, identity settings, application choices, network controls, endpoint protection, and service-specific configurations. The boundary changes by service model. A customer running virtual machines has more operating responsibility than a customer using a more managed service, but no model removes customer accountability altogether. This creates a central service-quality lesson: cloud adoption transfers some responsibilities, but it does not eliminate management.
4.5 Interpreting Service-Level Commitments
Service-level agreements add formal clarity, yet their role should be interpreted carefully. A published SLA gives customers a defined availability commitment and a remedy, often in the form of service credits. The value is contractual and symbolic: it shows that availability is a formal promise. The limitation is equally important. A credit cannot fully compensate for a failed product launch, a delayed clinical process, a damaged customer relationship, or a regulatory explanation after a disruption. Enterprise customers therefore need internal service targets that are stricter and more contextual than the provider’s minimum commitments.
4.6 Incident Communication
Incident communication is another governance test. Customers judge cloud providers by the eventual restoration of service and by the quality of information available while the event is unfolding. Useful incident communication is timely, plain, scoped, and practical. It acknowledges uncertainty without hiding behind vague language. It helps customers decide whether to fail over, wait, communicate to their users, pause deployments, or activate continuity plans. AWS’s public status tools and support channels are part of this experience, but customers still need their own communication routines because their end users often do not consume provider status information directly.
4.7 Security Governance
Security governance in the AWS case is inseparable from service quality. AWS offers identity, encryption, logging, key management, monitoring, network, and threat detection services, yet customer choices remain decisive. A misconfigured identity policy, exposed access key, public storage setting, unpatched workload, or weak segmentation decision can create the appearance of cloud failure when the deeper issue is customer governance. For managers, this means quality dashboards should include security posture indicators. A service that is available but unsafe has not delivered high quality.
4.8 Cost Governance
Cost governance is also part of the AWS service-quality picture. Cloud pricing gives flexibility, but flexibility without visibility can produce executive anxiety. Customers need tags, budgets, alerts, forecasting, chargeback methods, and accountability for resource consumption. A customer who learns about waste through a surprising invoice may lose trust in the platform and in the internal team managing it. Cost clarity is therefore not a finance afterthought. It is part of the experience of control. Good cloud operations makes spending explainable before it becomes a crisis.
4.9 Capacity Planning
Capacity planning in the AWS case operates at two levels. AWS must plan provider-side capacity across regions, availability zones, power, cooling, networking, storage, computing, specialized chips, and service teams. Customers must plan workload-side capacity through autoscaling, quotas, database sizing, caching, failover, and demand forecasting. Artificial intelligence and data-intensive workloads make this more demanding because compute requirements can grow quickly. The governance lesson is that cloud capacity may be elastic, but it is not magical. Elasticity still needs limits, forecasts, tests, and financial rules.
4.10 Customer Maturity
Customer maturity varies widely, and that variation affects service quality. Some customers have experienced cloud teams, mature security operations, tested recovery processes, and strong cost management. Others move workloads quickly without adequate operating discipline. AWS guidance reduces risk by making best practices visible, but guidance cannot force maturity. This is why cloud enterprises increasingly provide assessment tools, best-practice programs, training, and partner ecosystems. Provider governance includes helping customers govern themselves.
4.11 Scale and Dependency Risk
The AWS case also shows the danger of equating scale with invulnerability. Large platforms can provide redundancy, automation, and specialized expertise that smaller organizations could not build alone. Yet large platforms are also complex systems with many dependencies. Complexity creates hidden coupling, ambiguous signals, and occasional surprises. Mature cloud governance does not deny this. It builds systems that detect, isolate, communicate, and learn. The managerial question is not whether a cloud enterprise can promise that nothing will go wrong. It is whether the organization is prepared to protect customers when something does.
4.12 Transparency and Incident Disclosure
A final case pattern concerns transparency. Customers need enough information to make risk decisions, but cloud providers must also protect security-sensitive details and avoid speculation during fast-moving events. This tension requires judgment. Too little information damages trust; too much premature information may mislead customers or expose sensitive operational details. Mature incident communication balances speed, accuracy, and usefulness. It tells customers what is known, what is being investigated, what actions are recommended, and when the next update will come.
4.13 Case Synthesis
Figure 1. Cloud operations governance and service-quality chain.
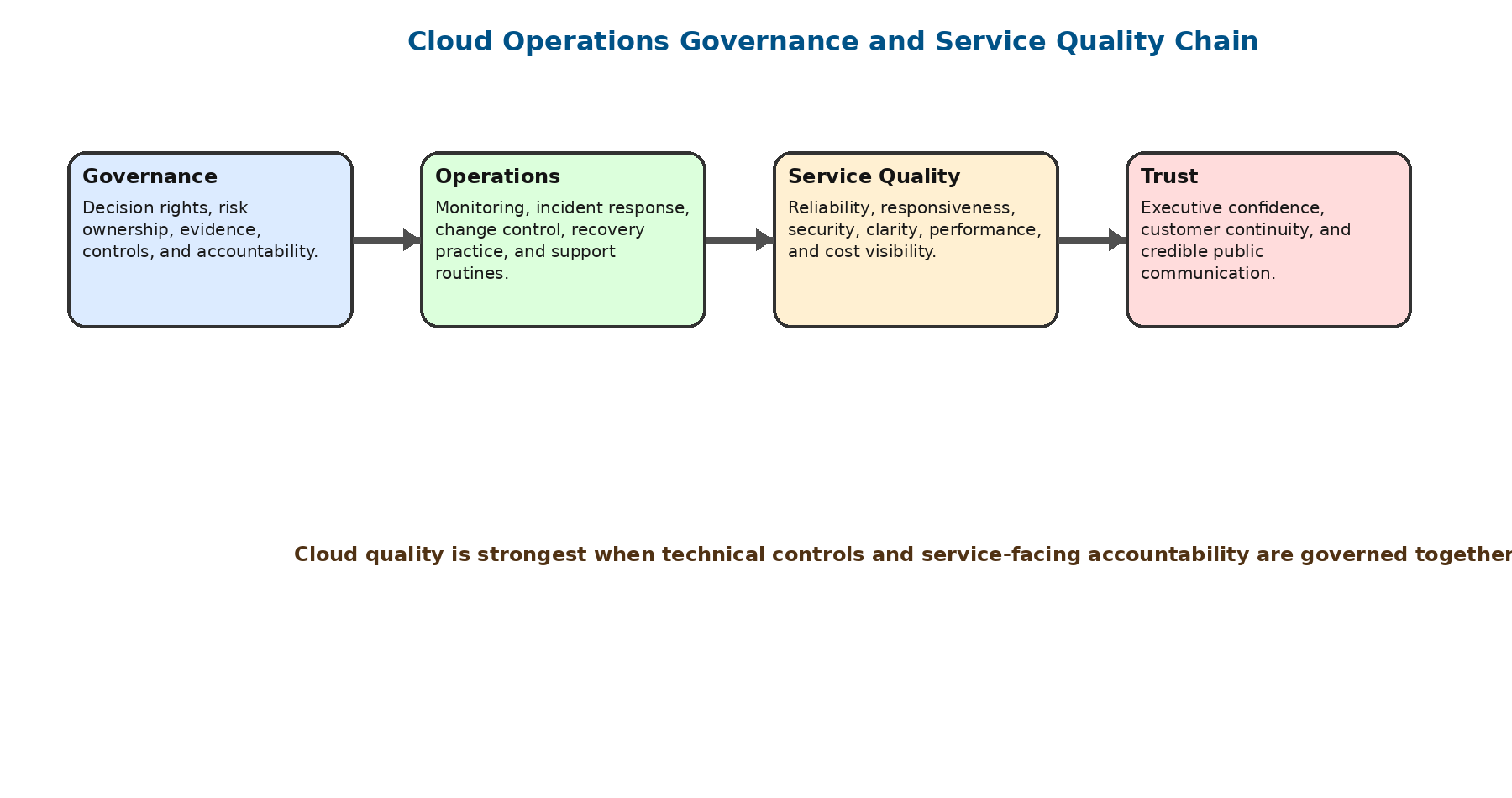
The case evidence supports a central finding: AWS frames service quality as a combined responsibility involving provider capability, customer practice, operational measurement, security controls, formal commitments, and continuous improvement. This framing is stronger than a narrow uptime promise. It also places a burden on customers. Cloud quality is not something purchased once. It is something governed across the life of the workload.
Chapter 5: Operations Mathematics and Service-Quality Modeling
5.1 Purpose of Operations Modeling
Operations mathematics gives cloud managers a way to discuss quality without relying only on impressions. The purpose is not to reduce customer experience to formulas. The purpose is to make invisible pressure visible before it becomes a public failure. Availability, utilization, capacity headroom, response time, and composite quality scores each reveal a different part of the service-quality problem. Used together, they help executives ask better questions about reliability and readiness.
5.2 Availability Scenario
Consider a monthly availability example. A service operates for 43,200 minutes in a 30-day month and experiences 12 minutes of qualifying downtime. The availability calculation is U = ((43,200 – 12) / 43,200) × 100 = 99.972 percent. The number appears strong, but a manager still needs context. Did the downtime occur during peak business hours? Did it affect all customers or a specific region? Did customers experience degraded performance before or after the measured downtime? Were data checks required? Was communication clear? Availability is a starting point, not the end of the analysis.
5.3 Queueing Utilization Scenario
Queueing utilization exposes a different risk. Suppose a priority support team receives 48 incidents per hour and can respond to 60 per hour. Utilization is ρ = 48 / 60 = 0.80. The team has pressure but still has room to absorb variation. If demand rises to 57 incidents per hour while capacity remains 60, utilization becomes 0.95. That five-point movement can change the customer experience sharply because waiting time accelerates near saturation. An executive who sees only staffing cost may call 95 percent utilization efficient. A service manager should recognize it as a warning.
5.4 Capacity Headroom Scenario
Capacity use raises a related trade-off. Suppose a regional workload uses 72 units out of 100 available units. CU = 72 percent. This level may be financially reasonable while preserving headroom. If demand rises to 94 units, the service may still be technically within capacity, but operational resilience is weaker. A failover event, traffic spike, security investigation, or batch processing surge could push the system into strain. The cost of unused headroom must be compared with the business cost of fragility.
5.5 Mean Response Time
Mean response time is important because customers need acknowledgement before full resolution is possible. If ten priority incidents produce 220 total minutes before first response, MRT = 22 minutes. If process changes reduce the total to 120 minutes, MRT = 12 minutes. This improvement does not prove faster technical resolution, but it changes the customer’s experience of being supported. Clear response can reduce rumor, duplicated tickets, internal escalation, and executive frustration. Response time should therefore be paired with quality of response, not interpreted as a pure speed metric.
5.6 Composite Service-Quality Index
A cloud service-quality index allows managers to bring several dimensions into one conversation. In the example used here, reliability receives a 0.30 weight, performance 0.20, security posture 0.20, customer communication 0.15, and cost transparency 0.15. A service with reliability 94, performance 88, security 90, communication 80, and cost clarity 76 receives CSQI = 0.30(94) + 0.20(88) + 0.20(90) + 0.15(80) + 0.15(76) = 87.2. The score is useful because it prevents one strong metric from hiding weaker dimensions.
5.7 Limits of the Index
The index should not become a new form of false precision. A high score may conceal serious risk if one dimension is high-impactly low. A service with excellent performance but weak security should not be accepted simply because the total score is respectable. Likewise, a service with strong reliability but poor cost transparency may generate executive dissatisfaction. The index is a governance tool. It supports discussion, trade-off analysis, and prioritization. It does not replace judgment.
5.8 Managerial Use of Scenarios
Scenario modeling is particularly useful because public case studies rarely provide the private data managers would prefer. A company may not know a provider’s internal capacity, but it can still model its own exposure. It can calculate the business impact of downtime, the cost of overutilized support, the benefit of faster first response, and the value of better cost alerts. Cloud governance improves when executives can see risk in numbers they understand.
Table 1. AWS Cloud Operations Governance Case Profile
| Governance domain | AWS case evidence | Service-quality meaning |
| Operational excellence | AWS operational excellence guidance | Quality depends on prepared routines, observation, review, and improvement. |
| Reliability | AWS reliability guidance and regional service model | Workloads should recover from failure and meet expected demand. |
| Service-level commitments | AWS published SLAs for paid generally available services | Availability commitments define minimum expectations, not total business protection. |
| Shared responsibility | Provider and customer duties vary by service model | Provider controls and customer configuration jointly shape experienced quality. |
| Security governance | AWS security services, identity controls, logging, and customer guidance | Security is part of customer trust and therefore part of service quality. |
| Cost governance | Budgeting, tagging, cost monitoring, and cost guidance | Financial clarity affects the customer’s sense of control. |
Table 2. Operations Mathematics for Cloud Service Quality
| Measure | Formula | Management use |
| Uptime percentage | U = ((Total Time – Downtime) / Total Time) × 100 | Measures service availability while requiring business context. |
| Queueing utilization | ρ = λ / μ | Shows pressure as incident or support demand approaches response capacity. |
| Capacity use | CU = Used Capacity / Available Capacity × 100 | Balances efficiency with operational headroom. |
| Mean response time | MRT = Total First-Response Time / Incidents | Evaluates speed of acknowledgement during incidents. |
| Cloud service-quality index | CSQI = 0.30R + 0.20P + 0.20S + 0.15C + 0.15T | Combines reliability, performance, security, communication, and cost clarity. |
Table 3. Scenario-Based Cloud Service-Quality Index
| Scenario | Reliability | Performance | Security | Comm. | Cost clarity | CSQI |
| Stable operations | 94 | 88 | 90 | 80 | 76 | 87.2 |
| Strong communication | 92 | 87 | 88 | 92 | 80 | 88.4 |
| High performance, weak cost clarity | 95 | 94 | 90 | 78 | 60 | 86.0 |
| Improved recovery | 90 | 84 | 88 | 88 | 78 | 86.3 |
Chapter 6: Findings
6.1 Co-Produced Quality
The central finding is that cloud service quality is co-produced by provider capability and customer operating maturity. AWS can supply a highly capable platform, documented service commitments, security controls, monitoring tools, and best-practice guidance. The customer still decides how workloads are configured, how identities are controlled, how recovery is tested, how costs are monitored, and how internal users are supported. The customer’s end user does not separate these responsibilities when something fails. The experience is judged as one service.
6.2 Availability Is Necessary but Incomplete
A second finding is that uptime is necessary but incomplete. Availability commitments matter, and managers should read them carefully. Yet uptime alone cannot explain degraded performance, unclear incident communication, weak customer recovery planning, security exposure, or unpredictable cost. A cloud service can meet a formal availability measure while still creating customer frustration. Leaders need dashboards that include performance, incident response, security posture, recoverability, and cost transparency.
6.3 Operationalizing Shared Responsibility
The case also shows that shared responsibility must be operationalized rather than left as a slogan. Many cloud failures arise not from ignorance of the model but from weak translation into daily practice. Organizations may understand that they are responsible for identity controls, yet still fail to review permissions. They may know they need backup, yet fail to test restore procedures. They may recognize cost risk, yet lack tagging and budget alerts. Governance succeeds when responsibility becomes routine.
6.4 Communication Under Pressure
Another finding concerns communication under pressure. Cloud customers need more than technical recovery. They need to know what is happening, whether their workloads are affected, what actions are recommended, and when another update will arrive. Communication does not remove the pain of disruption, but it can preserve confidence. Poor communication can make a manageable incident feel uncontrolled.
6.5 Early Warning Through Capacity Signals
Capacity and support pressure require early warning. Queueing logic shows why delay can accelerate quickly when arrival rates approach service capacity. Cloud enterprises and cloud customers should watch utilization before saturation becomes visible. This principle applies to technical resources and to human response teams. Operating every system near maximum use may look efficient until demand changes.
6.6 Security as a Quality Dimension
Security must be treated as a service-quality dimension. Customers experience trust as a whole. A service that runs but exposes data, credentials, or administrative paths has failed quality in a practical sense. Secure development, identity governance, logging, access review, and configuration control should be integrated into quality review.
6.7 Cost Transparency
Cost transparency is a final finding because cloud usage converts technical decisions into financial consequences. When spending becomes difficult to explain, trust weakens. Cost governance should be part of operational review, not a late finance correction. Customers need the ability to see, forecast, allocate, and challenge cloud spending in language executives can understand.
Chapter 7: Discussion, Recommendations and Conclusion
7.1 Technical and Service Literacies
The AWS case makes clear that cloud operations leaders need both technical literacy and service literacy. Technical literacy helps them understand availability zones, failover, capacity, latency, identity, observability, and recovery. Service literacy helps them understand customer anxiety, communication needs, billing pressure, and the reputational meaning of incidents. A manager who has only one of these literacies will miss part of the problem. Cloud quality is a technical service delivered through organizational trust.
7.2 Governance Before Business impact
The discussion also shows why cloud governance should be embedded before workloads become high-impact. Many organizations strengthen governance only after an incident, a security scare, or a billing surprise. That reactive pattern is costly. A cloud workload should have clear ownership, risk classification, recovery objectives, cost alerts, access review, monitoring, and support paths before it becomes essential. The more high-impact the workload, the less acceptable it is to discover governance gaps during a disruption.
7.3 False Confidence in Shared Responsibility
Shared responsibility deserves special attention because it can create false confidence. Customers may assume that a cloud provider’s reputation protects them from operational discipline. That assumption is dangerous. Cloud providers can remove many infrastructure burdens, but customers still make decisions that affect end-user quality. A poorly governed customer can turn a strong platform into an unreliable service. This is why executive leaders must treat cloud adoption as a management change rather than a technology procurement.
7.4 SLAs and Business Impact
Service-level agreements should be read through the lens of business impact. A contractual credit may be useful, but the customer’s real loss may involve delayed work, lost sales, emergency staffing, compliance reviews, and reputational repair. Business-essential workloads need internal service-level objectives that reflect the organization’s own risk. A public-sector portal, a hospital workflow, and an experimental analytics sandbox do not require identical reliability targets. Governance has to classify workloads and allocate controls accordingly.
7.5 Learning Culture
There is also a cultural dimension. Mature cloud operations cultures do not treat incidents as embarrassing exceptions to hide. They treat them as evidence. An incident reveals where monitoring was thin, where escalation was slow, where documentation was unclear, where dependencies were misunderstood, or where customers lacked guidance. Blame-focused cultures may close tickets quickly but fail to learn. Learning-focused cultures convert incidents into safer practice.
7.6 Using the Index as Conversation Instrument
The cloud service-quality index proposed in this paper is best understood as a conversation instrument. Its value lies less in the exact number than in the argument it forces. Why does reliability receive more weight than communication? Is cost transparency too low? Should security posture have a threshold below which the total score cannot be considered acceptable? These questions are managerial. They encourage leaders to express priorities rather than hiding them behind technical dashboards.
7.7 Customer Governance Questions
For AWS customers, the practical lesson is that provider selection is only one part of risk management. Customers should evaluate how their own organization will operate in the chosen cloud environment. Do teams understand the shared responsibility boundary? Are recovery procedures tested? Are workloads tagged? Are privileged identities reviewed? Are incident roles clear? Are business units prepared for degraded service? These questions determine whether cloud adoption becomes dependable service or unmanaged dependency.
7.8 Public Consequence of Cloud Dependency
The wider social implication is that cloud quality now affects public life. When cloud services support hospitals, schools, benefit systems, public communication, or emergency information, a technical incident may become a public confidence issue. Cloud governance therefore belongs in board-level risk discussion. Executives do not need to become engineers, but they do need to understand the service consequences of cloud dependency.
7.9 Multi-Dimensional Dashboards
Cloud enterprises and cloud-dependent organizations should manage service quality through multi-dimensional dashboards. Availability should remain visible, but it should sit alongside latency, error rates, recovery test results, support response, security posture, cost variance, customer communication, and post-incident actions. A dashboard that reports uptime alone is too narrow for enterprise decision-making.
7.10 Responsibility Maps
Figure 2. Shared-responsibility map for cloud service quality.
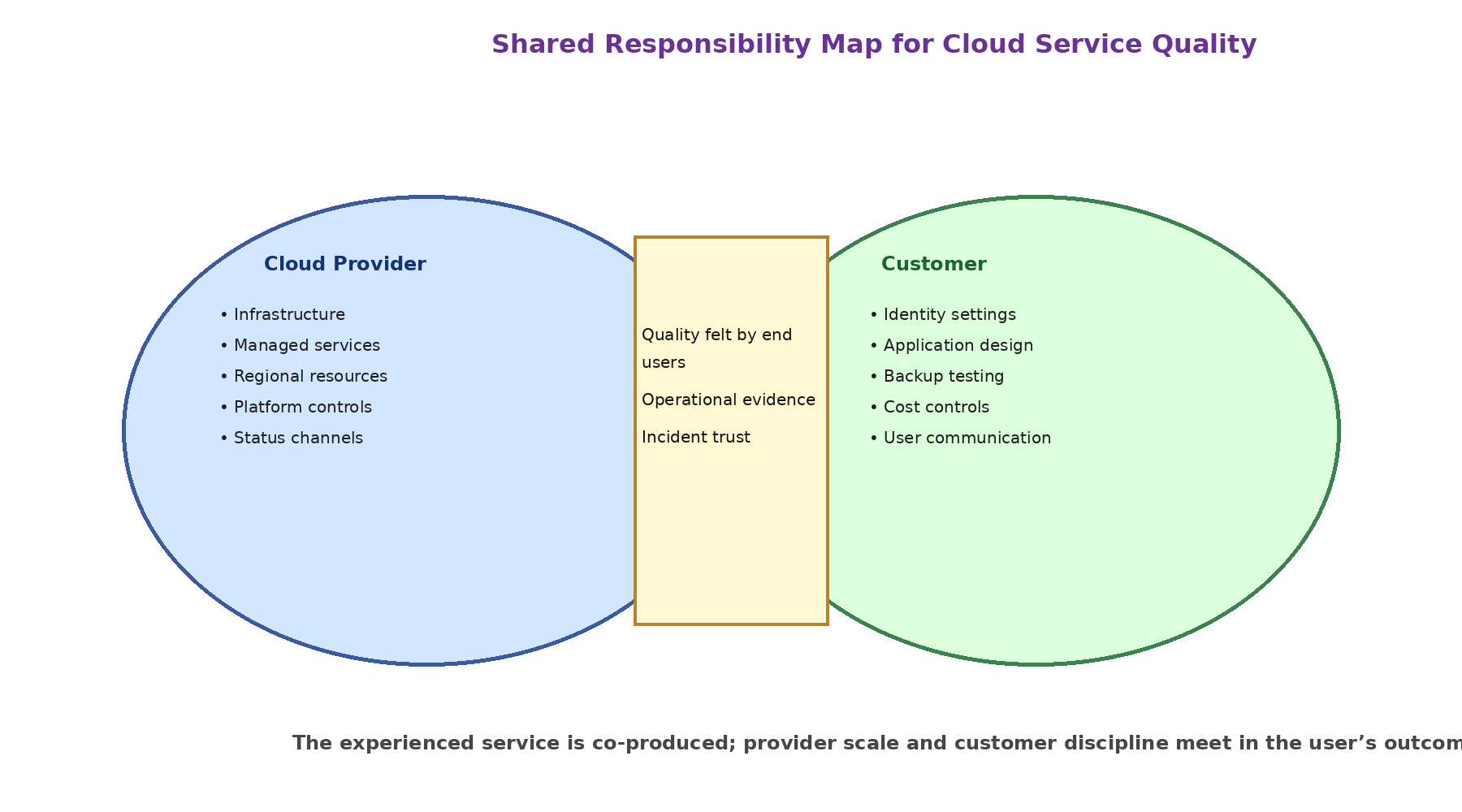
Organizations should treat shared responsibility as a training and audit requirement. Every business-essential workload should have a documented responsibility map showing which controls belong to the provider, which belong to the customer, and which require joint coordination. The map should be reviewed when the service model changes. Without this routine, shared responsibility remains a slogan rather than a governance practice.
7.11 Internal Service Targets
Internal service targets should exceed provider SLAs for business-essential services. Workloads with high financial, safety, regulatory, or public consequences need recovery objectives, failover plans, backup validation, and communication playbooks that reflect actual business impact. The SLA may define a provider remedy, but it should not define the customer’s whole continuity strategy.
7.12 Communication Preparedness
Incident communication should be rehearsed. Customers need plain-language updates, internal escalation paths, executive briefings, and user-facing messages before a disruption occurs. Communication templates should allow honest uncertainty while still providing useful guidance. During pressure, the worst moment to invent a communication routine is the moment when customers are already waiting.
7.13 Capacity and Saturation Review
Queueing and capacity measures should be reviewed before saturation. Support teams, incident responders, and technical resources need thresholds that trigger additional capacity, automation, or demand control. Leaders should avoid celebrating utilization so high that small demand changes produce delay. Efficiency without resilience is fragile quality.
7.14 Security in Quality Review
Security controls should be included in service-quality reviews. Access review, key management, logging coverage, vulnerability remediation, secure development practices, and configuration checks should be discussed with the same seriousness as uptime. Customers do not experience a breach as separate from service quality; they experience it as loss of trust.
7.15 Cost Transparency
Cost transparency should be treated as a customer confidence issue. Tagging, budgets, anomaly alerts, showback, forecasting, and business-unit accountability should be established early. Cloud teams should be able to explain spend in operational language as well as accounting language. When financial signals are clear, cloud flexibility feels controlled rather than risky.
7.16 Post-Incident Learning
Post-incident review should focus on learning and recurrence prevention. The review should identify what happened, what signals appeared, who needed to know, what customer actions were required, and what practice will change. The review should produce accountable actions rather than narrative closure. A restored service is not the same as an improved service.
7.17 Workload Classification
Workload classification deserves more emphasis than it often receives. A cloud-dependent organization may have experimental dashboards, internal collaboration tools, regulated data workflows, customer-facing transaction systems, and emergency response services in the same cloud estate. These workloads should not share one governance standard. Business impact, data sensitivity, recovery tolerance, user impact, and regulatory exposure should determine the level of control. A low-risk prototype may tolerate brief interruption and simple backup. A public-facing payment service may require stronger failover, more frequent restore testing, stricter identity review, and executive incident notification. Classification prevents both under-control and over-control.
7.18 Portfolio Governance
Governance maturity should also be assessed at the portfolio level. Many organizations can point to one well-managed workload while leaving the wider environment inconsistent. Some teams may tag resources properly while others do not. Some applications may have tested recovery procedures while others rely on assumptions. Some business units may understand cloud cost drivers while others treat spending as a surprise. A cloud service-quality review should therefore look across accounts, teams, applications, and regions. The question is not whether excellence exists somewhere, but whether dependable practice exists where the organization’s most important work depends on it.
7.19 Documentation as Usable Knowledge
The AWS case also reminds managers that documentation must become usable knowledge. Long technical guidance has limited value if busy teams cannot translate it into decisions. Organizations should turn provider guidance into local standards, checklists, training, design reviews, and operational routines. This translation work is where many cloud programs become stronger. It converts a general best practice into an internal expectation with named owners, review dates, and evidence of completion. Without that step, guidance can be admired but not practiced.
7.20 Integrated Management Responsibility
Cloud service quality is now a management responsibility with technical, financial, security, and public dimensions. The AWS case shows that mature cloud enterprises can provide strong service commitments, global resources, security controls, guidance, and operational tools. It also shows that dependable quality requires more than provider scale. Customers must govern their own use of cloud services through configuration discipline, recovery testing, access control, observability, cost management, and clear internal ownership.
7.21 Study Contribution
The study’s main contribution is a multi-dimensional view of cloud quality. Uptime matters, but it cannot carry the whole meaning of service. Queueing pressure, capacity headroom, first response, security posture, customer communication, and cost transparency reveal quality risks that uptime can hide. The proposed cloud service-quality index is not a universal formula, but it gives leaders a practical way to discuss trade-offs and priorities.
7.22 Case Conclusion
AWS remains an important case because its public materials make visible the operating language of a major cloud provider. The strongest lesson is not that one platform can remove risk. The lesson is that service quality has to be governed continuously across provider and customer boundaries. Cloud enterprises earn trust when they make systems reliable, secure, explainable, recoverable, and financially understandable. Customers protect trust when they turn cloud guidance into disciplined operating practice.
Chapter 8: Applied Cloud Governance Standard
8.1 Why Cloud Quality Needs Executive Ownership
Cloud quality cannot be left only to engineers once a workload becomes essential to the organization. Engineers understand latency, failover, deployment risk, access controls, observability, and logs, but executive leaders decide how much risk the organization is prepared to tolerate. They decide which services are high-impact, which recovery objectives are acceptable, which data are sensitive, and which customer promises must be protected during disruption. Those decisions need technical advice, but they are governance decisions before they are engineering decisions.
A useful governance standard begins with workload classification. A test dashboard, an internal analytics sandbox, a payroll system, a patient portal, a payment workflow, and a public emergency platform do not carry the same consequence if they fail. The problem in many organizations is that cloud use grows faster than classification. Teams build quickly, spending begins as a project cost, and only later does the workload become important enough to require board attention. By then, ownership, cost accountability, recovery expectations, and security responsibilities may already be unclear.
AWS guidance on operational excellence and reliability is valuable because it pushes customers to treat preparation as part of quality rather than an administrative afterthought (Amazon Web Services, 2024a, 2024b). The same logic belongs at executive level. Leaders should know which workloads are most exposed, which services have been tested for recovery, which data stores lack backup validation, which teams depend on a single person, and which business units would be unable to operate if a cloud service became degraded for several hours. This is not micromanagement. It is risk ownership.
Cloud adoption often begins with a promise of agility. That promise is real, but agility without governance becomes another source of disorder. A team can launch resources quickly and still fail to tag them, monitor them, secure them, or retire them. A service can scale automatically and still produce a bill no one can explain. A region can provide resilience options that customers do not configure. Executive ownership therefore has to ask a plain question: have cloud services been turned into managed organizational commitments, or are they still treated as technical assets owned by whichever team first built them?
8.2 Shared Responsibility as a Working Control
Shared responsibility is often quoted more easily than it is practiced. The phrase can sound settled, as if naming the boundary solves the risk. It does not. A shared responsibility model has to be translated into a control register, a training routine, and an audit practice. Otherwise, customers may assume that the cloud provider has taken over more responsibility than it has, while internal teams assume that another department is handling the remaining work.
The working question is specific: who owns identity review, privileged access, encryption choices, network exposure, backup testing, patching, logging, incident notification, cost alerts, and recovery drills? The answer changes by service model. A customer using virtual machines carries a different operating burden from a customer using a managed database or serverless service. Even in highly managed services, the customer still makes choices about access, data, configuration, monitoring, and business continuity. Those choices influence the quality the end user experiences.
The AWS case is useful because it makes this boundary visible. AWS can provide infrastructure, service controls, documentation, monitoring services, security tools, and formal commitments. The customer still has to configure, test, review, and govern. A misconfigured storage setting, exposed access key, weak identity policy, untested backup, or abandoned development environment can create a service-quality failure without requiring a provider outage. The customer may still describe the event as a cloud problem because the work was hosted in the cloud. The deeper cause may be unmanaged responsibility.
A publication-ready cloud governance standard should therefore require a responsibility map for every business-essential workload. The map should show which controls belong to the provider, which belong to the customer, which are shared, and which require evidence of testing. It should be reviewed whenever a service model changes, when a workload becomes business high-impact, when sensitive data are introduced, or when a major incident exposes confusion. The map should be useful enough for a manager to ask, during an incident, who must act next and what evidence shows that the required control exists.
8.3 Incident Communication and the Preservation of Trust
Incident communication is one of the fastest ways to strengthen or damage trust. Technical teams may focus on restoration, which is understandable. Customers and executives also need orientation. They need to know what is affected, what is still unknown, what actions are recommended, when the next update will arrive, and whether they should activate continuity plans. Silence during uncertainty rarely feels neutral. It feels like loss of control.
A strong incident message does not need false certainty. It needs useful honesty. Early communication can acknowledge that investigation is still underway while giving customers enough information to make decisions. Later communication can narrow the scope, identify known impact, describe workarounds, and name the next update time. After restoration, communication should explain what changed, what risk remains, and what will be reviewed. This sequence matters because customers often have to communicate to their own users before the provider has completed technical recovery.
SRE literature is helpful because it treats incidents as part of operating life rather than as shameful surprises (Beyer et al., 2016). The lesson for governance is that communication should be rehearsed before the incident. Teams need templates, escalation paths, executive briefings, customer-facing language, and internal roles. The person who can fix the system is not always the person who should brief the executive group. The engineer who understands the fault may not have the authority to approve a customer message. These role decisions should not be invented under pressure.
Communication also has to account for degraded service, not just total outage. A service may be technically available while performance is poor, error rates are high, support queues are overloaded, or data reconciliation is required. Customers experience degraded service as disruption. A narrow status message that says the service is available may feel evasive when the practical experience is failure. Cloud governance should therefore include language for partial impairment, regional impact, customer-specific risk, and recovery uncertainty.
8.4 Quality Evidence Beyond Uptime
Availability remains important, but it cannot carry the whole meaning of cloud quality. A service can meet an uptime percentage and still leave customers dissatisfied because support was slow, costs were unclear, recovery was untested, security controls were weak, or communication was too vague. Quality has to be read through several forms of evidence at the same time.
ISO/IEC 25010 is useful because it gives managers a broader vocabulary for software and systems quality, including performance efficiency, reliability, security, usability, compatibility, maintainability, flexibility, and safety (International Organization for Standardization, 2023). A cloud workload may be reliable in a narrow availability sense but difficult for customers to configure safely. It may perform well under normal demand but become expensive under automated scaling. It may be secure in design but hard for non-specialist teams to operate without mistakes. Each weakness changes the service experience.
Cost evidence deserves a stronger place in quality review. Cloud spending is more than a finance concern. It is a signal of control. A service team that cannot explain a sudden bill may have weak tagging, poor forecasting, no anomaly alerting, or unclear ownership of resources. The customer may still value the cloud platform, but the sense of control has been damaged. A mature governance review asks whether cost is visible early enough for teams to act, whether invoices are eventually paid.
Security evidence belongs in the same review. A service that is available but poorly governed from a security perspective is not high quality. NIST’s Secure Software Development Framework stresses disciplined practices to reduce vulnerabilities across development and deployment work (National Institute of Standards and Technology, 2022). For cloud customers, this means access review, key management, logging, secure configuration, deployment controls, and vulnerability response should be discussed with the same seriousness as uptime. A security failure can become a service failure even without a conventional outage.
Observability is the connective evidence. Without logs, metrics, traces, alerts, and useful dashboards, teams may discover problems from customers rather than from their own systems. That weakens confidence. Observability should show whether the service is healthy, whether performance is degrading, whether errors are rising, whether cost is drifting, and whether recovery controls are working. A dashboard that reports uptime alone is too narrow. It may make the organization feel safe while important signals remain outside view.
8.5 AI and Data-Intensive Workloads
Artificial intelligence and data-intensive workloads sharpen the governance problem because they increase demand for specialized compute, storage, data movement, monitoring, and cost control (Kleppmann, 2017). They also raise questions about data stewardship, model behavior, security, and explainability. A cloud customer running ordinary web applications may already need disciplined governance. A customer running AI pipelines, large analytics workloads, or high-volume data processing needs that discipline even more.
Capacity planning becomes more difficult because demand may arrive unevenly. Training jobs, batch analytics, inference workloads, and experimental projects can consume resources quickly. Elasticity helps, but it does not remove limits. Quotas, regional capacity, specialized chips, network throughput, storage performance, and budget ceilings still matter. A team that treats elasticity as unlimited may discover the constraint at the worst point: during a product launch, a research deadline, a customer commitment, or a security investigation.
Cost visibility also becomes more urgent. AI and analytics workloads can generate spending that is difficult for executives to understand because usage is tied to experiments, model runs, data movement, and scaling patterns rather than a simple user count. Governance should require tagging, budget alerts, workload owners, experiment controls, and review of idle resources. Cloud flexibility is valuable only when leaders can explain the cost of that flexibility.
Data stewardship sits at the center of this issue. Sensitive data used in analytics or AI workflows must be governed through access control, retention rules, encryption, lineage, and auditability. If teams move data into cloud environments faster than governance can follow, the organization may create risks that are invisible until a breach, compliance review, or customer challenge occurs. The cloud provider may offer many controls, but the customer’s data decisions remain decisive.
DORA and DevOps research also matter for AI and data-intensive work because speed alone does not prove maturity (Forsgren et al., 2018; Google Cloud DORA, 2024). Teams may deploy quickly and experiment aggressively while still lacking change discipline, monitoring, rollback plans, or security review. The management question is not whether teams are moving fast. It is whether they can move fast without creating ungoverned dependency.
8.6 Minimum Governance Controls for Cloud-Dependent Organizations
A practical cloud governance standard should be small enough to use and strong enough to matter. The minimum control set begins with ownership. Every business-essential workload should have a named business owner, a technical owner, a security owner, and a cost owner. These roles may overlap in smaller organizations, but the responsibilities should not be vague. A system without ownership becomes invisible until it fails.
The second control is classification. Workloads should be classified by business impact, data sensitivity, user dependence, compliance relevance, and recovery need. Classification prevents two errors. It prevents business-essential workloads from being under-governed, and it prevents low-risk experiments from being burdened with controls that make ordinary work impossible. Governance should fit risk.
The third control is recovery evidence. Backup schedules, replication choices, restore tests, failover drills, and recovery objectives should be documented. A backup that has never been restored is an assumption, not a control. A failover plan that no one has practiced is a hope, not a capability. Recovery evidence should be reviewed more often for workloads with high public, financial, safety, or regulatory impact.
The fourth control is identity discipline. Privileged access should be limited, reviewed, logged, and revoked when roles change. Service accounts and machine credentials should be managed with the same seriousness as human access. Many cloud failures begin with identity weakness rather than provider outage. Identity is therefore a service-quality control.
The fifth control is cost accountability. Budgets, alerts, tagging, resource ownership, anomaly detection, and chargeback or showback methods should exist before spending becomes difficult to explain. Cloud teams should be able to tell executives which workloads are driving cost and whether that cost is expected, wasteful, or strategically justified.
The sixth control is incident readiness. Teams need severity definitions, escalation routes, customer communication templates, provider support paths, and post-incident review practices. Incident readiness should include degraded service as well as total outage. It should also include executive notification when customer, regulatory, financial, or reputational consequences are likely.
Table 4. Minimum Cloud Governance Controls
| Control area | Required evidence | Management test |
| Ownership | Named business, technical, security, and cost owners | Can leaders identify who decides, who acts, and who communicates during pressure? |
| Classification | Workload impact, data sensitivity, and recovery tier | Does the control level match the real consequence of failure? |
| Recovery | Backup validation, restore test, failover plan, and recovery objective | Has the service proved that it can recover, or is recovery assumed? |
| Identity | Privileged-access review, logging, and credential lifecycle control | Can the organization show who has access and why? |
| Cost | Tags, budgets, alerts, anomaly review, and owner accountability | Can spending be explained before it becomes a crisis? |
| Incident readiness | Severity levels, escalation paths, communication templates, and review routine | Can the organization communicate and learn while service pressure is active? |
8.7 Customer Education and Onboarding
Customer education is part of cloud service quality because many service failures begin with misunderstanding rather than platform weakness. A customer may know that a cloud provider offers encryption, backup, logging, identity controls, and monitoring, but still misunderstand which choices must be made locally. The difference between available controls and adopted controls is where governance risk often sits. A service provider can publish strong guidance. The customer still needs to turn that guidance into decisions, training, and routine review.
Onboarding should therefore be treated as a control point. When a new team enters a cloud environment, it should learn more than how to deploy resources. It should understand account structure, identity boundaries, tagging rules, data classification, budget alerts, support escalation, incident communication, and recovery expectations. These matters may sound administrative, but they decide whether the team can operate safely after deployment. A workload that goes live before the team understands its operating duties has already created risk.
Documentation matters, but documentation alone is not enough. Customers often need examples, defaults, guardrails, and practical review. If a team can choose a risky configuration without warning, or can run high-cost resources without budget alerts, the environment is too dependent on memory and goodwill. Good cloud governance makes safer choices easier to make and harder to miss. This may include account templates, baseline policies, mandatory tagging, preapproved network patterns, identity guardrails, and automated checks before production release.
Training should also be role-specific. Executives need to understand risk, cost, continuity, and public accountability. Engineers need to understand design patterns, monitoring, change control, and security configuration. Finance teams need usage visibility and forecasting language. Security teams need evidence of access review, vulnerability management, and incident response. Business units need to know what the cloud service can and cannot guarantee. A single generic training session cannot carry all of that.
The strongest customer education is linked to actual workload review. Teams learn best when guidance is attached to their own systems: the database they depend on, the identity policy they inherited, the recovery plan they have not tested, or the monthly cost line they cannot explain. This makes cloud governance less abstract. It also helps the organization see whether learning has changed practice.
8.8 Evidence Limits and Publication Discipline
A public case study of AWS has to be careful about what it can and cannot prove. Public documentation can show how AWS explains operational excellence, reliability, shared responsibility, service commitments, security guidance, cost optimization, and customer support. Amazon reporting can show the scale and business significance of AWS. Professional literature can help interpret reliability, DevOps, service quality, and software quality. These sources support a disciplined management analysis. They do not reveal AWS internal incident rooms, proprietary telemetry, private customer contracts, engineering staffing levels, real-time escalation decisions, or confidential capacity forecasts.
This limit is not a weakness if the paper states it plainly. It would be weaker to imply access the study does not have. The value of the case lies in using public evidence to examine how a major cloud enterprise frames service quality and how managers can reason about cloud dependency. Scenario mathematics also has to remain transparent. The calculations in this paper are not AWS performance claims. They are management illustrations. They show how a leader can think about availability, utilization, response time, headroom, and composite quality when direct internal data are unavailable.
The same caution applies to the cloud service-quality index. The index is useful because it forces a discussion across reliability, performance, security, communication, and cost transparency. It becomes dangerous if leaders treat the score as a complete truth. A strong total can hide a weak dimension. A service with high reliability and poor security should not be accepted because the weighted number remains respectable. A service with good performance and poor cost transparency may still damage executive trust. The score should support review, not replace it.
Publication discipline also requires careful treatment of AWS. The case should not read as promotion or attack. AWS is a major cloud enterprise with extensive public materials, formal commitments, and a substantial market role. It also operates inside the ordinary limits of complex systems. A serious paper can recognize capability without turning it into praise, and can discuss risk without implying private knowledge of failure. That balance is important for NYCAR publication quality.
The paper’s conclusions are therefore framed as management findings. They concern cloud governance, shared responsibility, service quality, measurement, communication, and customer readiness. They do not claim to audit AWS internally. They do not rank cloud providers. They do not present scenario values as company data. This restraint gives the paper credibility.
8.9 Additional Publication Readiness Controls
A publication-ready cloud operations paper should also show how its own claims are controlled. The strongest claims in this study are tied to public AWS documentation, Amazon reporting, service-quality theory, secure software guidance, ISO quality language, SRE, DevOps research, and transparent scenario mathematics. The weaker claims are not hidden; they are marked as interpretation. This distinction matters because cloud papers can easily drift into ungrounded commentary. A mature study keeps a visible boundary between documented evidence, professional reasoning, and illustrative modeling.
The same standard applies to the case selection. AWS is not examined because it is the only cloud provider worth studying. It is examined because the public record is large enough to support a serious management analysis. The case is visible, well documented, and operationally important. These qualities make it suitable for a master’s-level case study, but they do not make it universal. Findings from AWS can guide cloud governance thinking, yet they should be adapted when applied to smaller providers, private cloud environments, hybrid systems, or organizations with limited cloud maturity.
The study also needs to avoid a common weakness in technology research: admiration for capability without attention to use. A cloud platform can offer hundreds of services, but the management question is whether customers can operate the services safely. A platform can provide strong tools, but a team can still misconfigure them. A provider can offer global infrastructure, but a customer can still build a workload with a single point of failure. Technology creates possibility. Governance decides whether possibility becomes dependable service.
The quantitative section is strongest when read in that spirit. The availability calculation, queueing example, capacity-use calculation, mean response time, and service-quality index are not ornaments. They teach managers how to read service pressure before customers experience it as failure. The corrected index values also matter. If the mathematics are loose, the governance argument weakens. A paper that argues for measurement has to respect its own calculations.
Finally, publication readiness requires the language of service quality to remain plain. Cloud governance is often buried under technical vocabulary. This paper keeps returning to the customer experience: whether the service is available, whether support responds, whether costs are explainable, whether security is credible, whether recovery is tested, and whether leaders understand the risks they have accepted. That focus is what makes the case a management study rather than a technology description.
8.10 Implementation Sequence for Cloud Customers
Cloud customers often struggle because governance work is introduced after the workload is already live. A better sequence begins before migration or launch. The first step is to identify the business process the workload supports and the harm that would follow if the service failed, slowed, exposed data, or became too expensive to sustain. That conversation should include the business owner, technology owner, security lead, finance partner, and service users. Without that early view, the technical team may design for availability while the business assumes a different recovery promise.
The second step is to define operating evidence. A business-essential workload should not move into production without a documented owner, recovery objective, monitoring plan, backup validation, access model, cost alert, and support route. The evidence does not need to be elaborate. It needs to be current and usable. A one-page workload control record can be more valuable than a long policy that no one reads during pressure. The question is whether a responsible manager can find the answer quickly when something goes wrong.
The third step is to test before trust is claimed. Backup restoration, failover, privileged-access review, support escalation, and incident communication should be practiced before a serious event. Many organizations discover during incidents that a backup exists but cannot be restored quickly, that a dashboard shows technical health but not business impact, or that no one knows who should authorize a customer update. Testing exposes these gaps while there is still time to correct them.
The fourth step is to review cost and security together. A cloud service that is cheap because it lacks resilience may become expensive during failure. A workload that is secure but overbuilt may become financially unsustainable. Governance should not force a false choice between discipline and agility. It should make trade-offs visible. If leaders choose lower cost and slower recovery for a low-risk workload, that may be reasonable. If the same choice is made silently for a public-facing business-essential service, the organization has accepted risk without owning it.
The fifth step is to return to the workload after launch. Cloud environments change. Teams add services, permissions drift, data volumes grow, new dependencies appear, and usage patterns shift. A workload that was low risk during development may become high-impact once customers depend on it. Periodic review is therefore part of service quality. It protects the organization from assuming that yesterday’s design still matches today’s risk.
The sixth step is to make exceptions visible. Cloud teams sometimes accept temporary weaknesses because delivery pressure is real. A recovery test is deferred. A cost tag is missing. A privileged role is left open because a project deadline is close. These exceptions may be defensible for a short period, but they should not disappear into routine work. An exception register allows leaders to see which risks are temporary, who accepted them, and when they must be closed. Without that discipline, temporary choices become permanent exposure.
The final step is to connect workload review to board-level assurance. Executives do not need every technical detail, but they do need to know whether business-essential services have owners, tested recovery, cost visibility, security evidence, and incident communication plans. A board report that states cloud services are operating normally is too weak if it does not show the condition of the controls. Assurance should tell leaders where the organization is ready, where risk has been accepted, and where action is overdue.
8.11 Final Governance Position
The AWS case supports a sober professional standard. Cloud quality is not purchased once from a provider. It is produced repeatedly through decisions made by the provider and by the customer. AWS may supply infrastructure, managed services, documentation, service commitments, security tools, and operational guidance. The customer still decides how workloads are built, secured, monitored, funded, recovered, and explained.
This standard is not hostile to cloud adoption. It is the condition that makes cloud adoption responsible. Organizations gain speed and scale from cloud services, but speed and scale need operating discipline. Without that discipline, cloud dependency becomes quiet exposure. Systems work until they do not. Costs look manageable until they spike. Recovery plans appear adequate until someone has to use them. Shared responsibility seems clear until an incident proves that no one translated it into work.
A publication-ready view of cloud service quality must therefore hold two ideas together. The provider’s capability matters, and the customer’s governance matters. A strong platform can be weakened by poor configuration. A careful customer can still be affected by provider-side disruption. Service quality is created in the relationship between the two.
The final professional position is straightforward. Cloud enterprises sustain trust when availability, security, performance, communication, cost visibility, recovery, and customer readiness are governed together. A narrow uptime promise is not enough. A dashboard without interpretation is not enough. A shared responsibility model without evidence is not enough. Cloud service quality becomes credible when leaders can show who owns the workload, what risks have been tested, which controls are working, and how the organization will protect customers when normal operation is interrupted. The standard is practical: quality has to be demonstrable before customers are asked to depend on it.
References
Amazon.com, Inc. (2026). 2025 annual report. Amazon.com, Inc.
Amazon Web Services. (2022). Amazon Compute Service Level Agreement. Amazon Web Services.
Amazon Web Services. (2024a). AWS Well-Architected Framework: Operational Excellence Pillar. Amazon Web Services.
Amazon Web Services. (2024b). AWS Well-Architected Framework: Reliability Pillar. Amazon Web Services.
Amazon Web Services. (2025). AWS Service Level Agreements. Amazon Web Services.
Beyer, B., Jones, C., Petoff, J., & Murphy, N. R. (Eds.). (2016). Site reliability engineering: How Google runs production systems. O’Reilly Media.
Forsgren, N., Humble, J., & Kim, G. (2018). Accelerate: The science of lean software and DevOps. IT Revolution.
Google Cloud DORA. (2024). Accelerate state of DevOps report 2024. Google Cloud.
International Organization for Standardization. (2023). ISO/IEC 25010:2023 systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — Product quality model. ISO.
Kleppmann, M. (2017). Designing data-intensive applications: The big ideas behind reliable, scalable, and maintainable systems. O’Reilly Media.
National Institute of Standards and Technology. (2022). Secure Software Development Framework (SSDF) version 1.1: Recommendations for mitigating the risk of software vulnerabilities (NIST SP 800-218). U.S. Department of Commerce. https://doi.org/10.6028/NIST.SP.800-218
Parasuraman, A., Zeithaml, V. A., & Berry, L. L. (1988). SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality. Journal of Retailing, 64(1), 12–40.