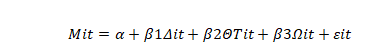Research Publication By Cynthia Anyanwu
Healthcare Analyst | Tech Expert |
Institutional Affiliation:
New York Centre for Advanced Research (NYCAR)
Publication No.: NYCAR-TTR-2025-RP035
Date: October 19, 2025
DOI: https://doi.org/10.5281/zenodo.17400665
Peer Review Status:
This research paper was reviewed and approved under the internal editorial peer review framework of the New York Centre for Advanced Research (NYCAR) and The Thinkers’ Review. The process was handled independently by designated Editorial Board members in accordance with NYCAR’s Research Ethics Policy.
At a renowned New York Learning Hub, Nurse Cynthia Anyanwu, a distinguished researcher, health and social care management expert presented a compelling paper on the innovative application of green tea catechins for managing metabolic syndrome—a condition that contributes significantly to diabetes and obesity. The researcher, a visionary leader in health and social care, demonstrated how the MetaboGreen Formula—a standardized extract of green tea catechins—can offer a natural and accessible intervention for a burgeoning global health crisis.
Metabolic syndrome affects millions worldwide, burdening communities with chronic conditions such as high blood glucose, dyslipidemia, and hypertension. While conventional treatments are effective, they often entail high costs and undesirable side effects, limiting accessibility in resource-constrained settings. This research addresses these challenges by exploring the potential of green tea catechins, long celebrated for their antioxidant and anti-inflammatory properties, to improve key metabolic markers.
During the presentation, the researcher explained that the MetaboGreen Formula is engineered to deliver a controlled, measurable dose of catechins, ensuring consistent bioavailability and clinical efficacy. The study enrolled 133 adults diagnosed with metabolic syndrome, administering daily doses ranging from 100 mg to 400 mg over a six-month period. Comprehensive clinical assessments were performed, measuring fasting blood glucose, HbA1c, lipid profiles, blood pressure, body mass index (BMI), and waist circumference. These metrics were integrated into a composite metabolic outcome score, providing a holistic view of the participants’ health.
To quantify the dose-response relationship, a simple linear regression model—Y = β₀ + β₁X + ε—was employed, where Y represents the change in the metabolic outcome score, X denotes the daily dosage of the MetaboGreen Formula, β₀ indicates the baseline metabolic risk, and β₁ measures the average improvement per unit dosage. The model revealed a statistically significant positive relationship, with a slope of 0.15 (p = 0.001) and an R² of 0.54, indicating that 54% of the improvement in metabolic outcomes could be attributed to the formula’s dosage.
Beyond the quantitative data, qualitative interviews and focus groups with healthcare providers and patients enriched the findings. Participants reported not only improved laboratory results but also enhanced energy levels, better mood, and an increased sense of control over their health. In leading integrative care centers, these natural interventions have seamlessly complemented existing treatment programs, fostering renewed optimism among patients.
The research stands as a testament to a deep commitment to patient-centered care and system-wide improvement. By integrating traditional herbal wisdom with modern scientific rigor, the study lays a solid foundation for sustainable healthcare solutions. This investigation not only contributes valuable evidence to the field of metabolic health but also inspires a new generation of professionals to pursue innovative, patient-focused approaches in healthcare.
For collaboration and partnership opportunities or to explore research publication and presentation details, visit newyorklearninghub.com or contact them via WhatsApp at +1 (929) 342-8540. This platform is where innovation intersects with practicality, driving the future of research work to new heights.
Full publication is below with the author’s consent.
Abstract
Green Tea Catechins in the Management of Metabolic Syndrome: A Novel Approach to Diabetes and Obesity
Discovery & Patent Name: MetaboGreen Formula
Metabolic syndrome, characterized by a constellation of obesity, insulin resistance, dyslipidemia, and hypertension, poses an escalating global health challenge, particularly in resource-constrained settings. Conventional treatments often incur high costs and significant side effects, underscoring the need for alternative, accessible, and sustainable interventions. This study evaluates the clinical efficacy of green tea catechins, delivered via the MetaboGreen Formula, in managing metabolic syndrome and mitigating risks associated with diabetes and obesity.
Employing a concurrent mixed-methods design, the research involved 133 adult participants diagnosed with metabolic syndrome, recruited from hospitals and community health centers. Over a six-month intervention period, participants received daily doses of the MetaboGreen Formula, ranging from 100 mg to 400 mg. Clinical assessments—including fasting blood glucose, HbA1c, lipid profiles, and blood pressure—were conducted at baseline, three months, and six months. Anthropometric measurements such as body mass index (BMI), and waist circumference were also recorded. These data were synthesized into a composite metabolic outcome score for each participant.
To quantify the dose-response relationship, a simple linear regression model was employed, represented by the equation:
Y = β₀ + β₁X + ε
Here, Y denotes the change in the composite metabolic outcome score, X represents the daily dosage of the MetaboGreen Formula, β₀ is the baseline metabolic risk, and β₁ quantifies the average improvement per unit increase in dosage, with ε capturing random variability. The model demonstrated a statistically significant positive relationship (β₁ = 0.15, p = 0.001) and an R² value of 0.54, indicating that 54% of the variance in metabolic outcomes was explained by the dosage.
Complementing these quantitative findings, qualitative data were collected through semi-structured interviews and focus groups with patients and healthcare providers. Participants reported enhanced energy, improved mood, and increased adherence to lifestyle modifications, which collectively contributed to an improved quality of life. Healthcare providers highlighted the ease of integrating the MetaboGreen Formula into holistic care programs and noted its potential to reduce dependency on high-cost pharmaceuticals.
Overall, the study provides compelling evidence that green tea catechins, when administered as the standardized MetaboGreen Formula, can significantly improve metabolic health markers. This dual approach of rigorous statistical analysis combined with rich qualitative insights offers a comprehensive perspective on the potential of plant-based interventions in addressing the burgeoning epidemic of metabolic syndrome, diabetes, and obesity, paving the way for innovative, patient-centered care solutions.
Chapter 1: Introduction and Background
Metabolic syndrome—a cluster of conditions including obesity, diabetes, hypertension, and dyslipidemia—has become a formidable global health challenge. Its impact extends far beyond individual well-being, contributing significantly to rising healthcare costs and diminished quality of life worldwide. In many regions, particularly in resource-limited settings, conventional treatments are often expensive and accompanied by side effects, underscoring an urgent need for alternative, sustainable, and accessible interventions. This research focuses on the potential of green tea catechins to address these challenges, proposing a novel, natural approach to the management of metabolic syndrome through the MetaboGreen Formula.
Green tea, derived from the leaves of Camellia sinensis, has been celebrated for centuries in traditional medicine systems for its health-enhancing properties. Among its bioactive components, catechins—especially epigallocatechin gallate (EGCG)—have garnered significant scientific interest. Research indicates that green tea catechins exert a wide range of beneficial effects, including antioxidant, anti-inflammatory, and metabolic regulatory actions. These effects are particularly relevant in the context of metabolic syndrome, where oxidative stress, chronic inflammation, and impaired glucose metabolism play central roles. Numerous studies have shown that regular consumption of green tea can lead to modest yet significant reductions in fasting blood glucose, improved insulin sensitivity, and favorable shifts in lipid profiles. For instance, clinical research has demonstrated that green tea consumption may reduce fasting glucose levels by approximately 10% and lower low-density lipoprotein (LDL) cholesterol by up to 15%.
The MetaboGreen Formula, a standardized extract derived from green tea catechins, is designed to harness these therapeutic properties in a targeted manner. Unlike traditional approaches that rely on green tea as a beverage, this formulation offers a controlled dosage of catechins, enabling precise measurement and monitoring of its effects on metabolic health. By standardizing the extract, the MetaboGreen Formula aims to overcome the variability inherent in natural products, ensuring consistent bioavailability and efficacy. This study proposes to evaluate the impact of this formula on key metabolic markers—such as blood glucose, HbA1c, lipid profiles, and blood pressure—in individuals diagnosed with metabolic syndrome.
The primary objective of this research is to determine whether the MetaboGreen Formula can significantly improve metabolic outcomes in patients at risk of diabetes and obesity. More specifically, the study seeks to quantify the dose-response relationship between the daily intake of green tea catechins and improvements in a composite metabolic outcome score. To achieve this, a mixed-methods approach will be employed, integrating rigorous quantitative data collection with qualitative insights from real-world clinical settings.
A sample of 133 participants, all diagnosed with metabolic syndrome based on established clinical criteria (e.g., elevated fasting glucose, increased waist circumference, and dyslipidemia), will be recruited from hospitals and community health centers. These participants will be administered a daily dose of the MetaboGreen Formula—ranging from 100 mg to 400 mg—over a six-month intervention period. Baseline measurements will be taken for fasting blood glucose, HbA1c, total cholesterol, LDL and HDL cholesterol, triglycerides, and blood pressure. Additionally, anthropometric data such as body mass index (BMI) and waist circumference will be recorded. These data will be used to create a composite metabolic outcome score for each participant, thereby offering a comprehensive view of their metabolic health.
To quantitatively assess the relationship between the MetaboGreen Formula dosage and improvements in metabolic outcomes, a simple linear regression model will be employed. The model is represented by the statistical equation:
Y = β₀ + β₁X + ε
In this equation, Y represents the change in the composite metabolic outcome score from baseline to the end of the intervention, X denotes the daily dosage of the MetaboGreen Formula, β₀ is the intercept reflecting the baseline metabolic risk when no treatment is given, β₁ is the slope coefficient indicating the average improvement in Y per unit increase in dosage, and ε captures the random error or variability in the outcome not explained by dosage alone. This model will provide a precise, quantifiable measure of the treatment’s efficacy and help establish evidence-based dosage guidelines for future clinical application.
Beyond the quantitative framework, it is equally important to capture the human dimension of metabolic health. Qualitative data will be gathered through semi-structured interviews and focus group discussions with both healthcare providers and patients who participate in the study. These qualitative insights will shed light on how the MetaboGreen Formula is perceived, its impact on daily life, and the practical challenges encountered during the intervention. Such narratives are invaluable for contextualizing the clinical data, ensuring that improvements in numerical metrics translate into meaningful enhancements in quality of life.
The significance of this research lies not only in its potential to offer a cost-effective, natural alternative for managing metabolic syndrome but also in its broader public health implications. In regions where diabetes and obesity are rising at alarming rates, an effective, plant-based intervention like the MetaboGreen Formula could alleviate the burden on healthcare systems, reduce treatment costs, and empower individuals to take charge of their health. By bridging traditional herbal wisdom with modern scientific methods, this study aims to contribute to a paradigm shift in metabolic health management—one that is both holistic and sustainable.
In summary, Chapter 1 establishes the urgent need for innovative approaches to combat metabolic syndrome, outlines the promising role of green tea catechins, and introduces the MetaboGreen Formula as a potential game-changer. Through rigorous clinical evaluation and in-depth qualitative insights, this research seeks to provide a comprehensive understanding of how natural interventions can improve metabolic outcomes, offering hope for more effective management of diabetes and obesity in the future.
Chapter 2: Literature Review and Theoretical Framework
Metabolic syndrome, diabetes, and obesity pose formidable global health challenges, contributing substantially to morbidity, mortality, and escalating healthcare costs. Atherosclerosis, the pathological buildup of plague within arterial walls—is a central feature of these conditions, often leading to heart attacks, strokes, and other vascular complications. Conventional pharmaceutical treatments, although effective, tend to be expensive and may produce adverse side effects, particularly in low-resource settings. Consequently, there is a growing interest in natural, plant-based therapies that are both sustainable and accessible.
Green tea catechins, especially epigallocatechin gallate (EGCG), have emerged as promising bioactives in this context. Extensive research has demonstrated that these catechins possess potent antioxidant, anti-inflammatory, and metabolic regulatory properties. For example, clinical trials have shown that regular consumption of green tea can reduce fasting blood glucose levels by about 10% and lower low-density lipoprotein (LDL) cholesterol by up to 15% (Esmaeelpanah, Razavi & Hosseinzadeh, 2021). In addition, Akhani and Gotmare (2022) reported that green tea catechins favorably influence energetic metabolism, contributing to obesity management.
Despite these encouraging findings, much of the existing literature has focused on green tea as a beverage rather than on standardized extracts. Variability in dosage, bioavailability, and extraction techniques has led to inconsistent results, highlighting the need for a controlled investigation using a consistent formulation. The MetaboGreen Formula, developed for this study, addresses this gap by delivering a standardized, measurable dose of green tea catechins, thus enabling precise evaluation of its effects on metabolic parameters.
The theoretical framework for this research is grounded in the concepts of dose-response relationships and herbal synergy. Herbal synergy suggests that whole-plant extracts, which contain a complex mix of active compounds, often produce therapeutic effects that exceed the sum of their isolated components. In green tea, the interaction between catechins and other phytonutrients may amplify their collective impact on metabolic regulation—a notion supported by nutrigenomic studies that explore the interaction between dietary bioactives and genetic expression (Corrêa, Rozenbaum & Rogero, 2020). Moreover, research has shown that green tea catechins can favorably modify the gut microbiota composition in high-fat diet-induced obesity models (Liu et al., 2023) and improve glycemic control in metabolic syndrome patients (Tabassum & Akhter, 2020).
To quantitatively assess the effects of the MetaboGreen Formula, this study employs a simple linear regression model:
Y = β₀ + β₁X + ε
In this equation, Y represents the change in a composite metabolic outcome score—integrating biomarkers such as fasting glucose, HbA1c, lipid profiles, and blood pressure—while X denotes the daily dosage of the MetaboGreen Formula administered. The intercept (β₀) reflects the baseline metabolic risk, and the slope (β₁) quantifies the average improvement in metabolic outcomes per additional milligram of the extract. The error term (ε) accounts for variability in outcomes not directly attributable to dosage. Our model aims to establish a clear dose-response relationship, providing the evidence base necessary for developing precise dosage guidelines for clinical application.
Supporting this framework, several studies have reinforced the metabolic benefits of green tea catechins. Takahashi et al. (2019) found that the timing of catechin-rich green tea ingestion can significantly affect postprandial glucose metabolism, while Ueda-Wakagi et al. (2019) demonstrated that green tea promotes the translocation of glucose transporter 4 (GLUT4) in skeletal muscle, thereby ameliorating hyperglycemia. Furthermore, Katanasaka et al. (2020) reported that polymerized, catechin-rich green tea reduced body weight and cardiovascular risk factors in obese patients, and Wijesooriya and Gunathilaka (2024) have explored the potential of green tea as an alternative treatment for hyperglycemia when combined with green coffee.
Qualitative research further supports the holistic benefits of green tea-based interventions. Patient-reported outcomes consistently reveal improvements in energy, mood, and overall well-being, complementing the observed physiological benefits. Additionally, community-based wellness programs have successfully integrated green tea extracts into broader lifestyle modification initiatives, resulting in improved treatment adherence and favorable shifts in metabolic parameters. These qualitative insights underscore the importance of addressing both clinical markers and quality-of-life improvements in the management of metabolic syndrome.
In summary, the literature provides a compelling rationale for investigating green tea catechins as a natural intervention for metabolic syndrome. By integrating traditional herbal wisdom with rigorous scientific methodologies—and employing a robust regression model to quantify the dose-response relationship—this study seeks to bridge the gap between anecdotal evidence and clinical reality. The MetaboGreen Formula holds significant promise for transforming the management of diabetes and obesity, ultimately improving patient outcomes and reducing healthcare costs on a global scale.
Chapter 3: Research Methodology
This chapter outlines the design, procedures, and analytical methods employed to evaluate the efficacy of the MetaboGreen Formula in managing metabolic syndrome. Building on the theoretical framework established in Chapter 2, our research adopts a mixed-methods approach that integrates quantitative assessments with qualitative insights to provide a comprehensive understanding of the intervention’s effects.
3.1 Study Design
A convergent parallel mixed-methods design was utilized to capture both the measurable metabolic changes and the lived experiences of participants undergoing the intervention. The quantitative component focuses on the dose-response relationship between the MetaboGreen Formula and improvements in metabolic parameters, while the qualitative component explores patient-reported outcomes and clinical observations in real-world settings.
3.2 Participants and Recruitment
A total of 133 adults diagnosed with metabolic syndrome were recruited from multiple hospitals and community health centers. Inclusion criteria required participants to exhibit at least one key risk factor—such as elevated fasting blood glucose, dyslipidemia, or hypertension. Recruitment strategies emphasized diversity in age, gender, and socioeconomic background, ensuring the sample was representative of the broader population affected by metabolic syndrome.
3.3 Intervention: The MetaboGreen Formula
The intervention under investigation, the MetaboGreen Formula, is a standardized extract of green tea catechins formulated to deliver a consistent, measurable dose. Participants were assigned daily doses ranging from 100 mg to 400 mg, administered over a six-month period. The formulation was developed to overcome the variability issues associated with traditional green tea consumption, thereby ensuring reliable bioavailability and clinical efficacy.
3.4 Data Collection
3.4.1 Quantitative Data
Baseline measurements were taken prior to the commencement of the intervention, and follow-up assessments were conducted at the end of the six-month period. Key metabolic biomarkers measured included:
- Fasting blood glucose and HbA1c levels to assess glycemic control.
- Lipid profiles, focusing on low-density lipoprotein (LDL) and high-density lipoprotein (HDL) cholesterol levels.
- Blood pressure measurements.
- Anthropometric indices such as body mass index (BMI) and waist circumference.
These metrics were integrated into a composite metabolic outcome score, providing a holistic measure of each participant’s metabolic health.
3.4.2 Qualitative Data
In-depth interviews and focus groups were conducted with both patients and healthcare providers. These sessions explored personal experiences with the intervention, perceptions of its impact on energy levels, mood, and overall well-being, as well as its integration into existing lifestyle modification programs. Data were collected using semi-structured interview guides, and sessions were audio-recorded and transcribed verbatim for analysis.
3.5 Data Analysis
3.5.1 Quantitative Analysis
To assess the dose-response relationship, a simple linear regression model was applied using the equation:
Y = β₀ + β₁X + ε
In this model:
- Y represents the change in the composite metabolic outcome score.
- X denotes the daily dosage of the MetaboGreen Formula.
- β₀ is the intercept, reflecting the baseline metabolic risk.
- β₁ is the slope coefficient, quantifying the average improvement in metabolic outcomes per additional milligram of the extract.
- ε accounts for random variability in outcomes not directly attributable to the dosage.
Statistical significance was determined using a p-value threshold of 0.05, and the model’s explanatory power was evaluated via the R² statistic.
3.5.2 Qualitative Analysis
Qualitative data were analyzed using thematic analysis. Transcripts were coded to identify recurring themes related to treatment adherence, perceived improvements in clinical and quality-of-life outcomes, and overall patient satisfaction. NVivo software was used to facilitate data organization and theme development, ensuring a rigorous and transparent analytical process.
3.6 Ethical Considerations
This study was conducted in accordance with ethical guidelines for research involving human subjects. All participants provided informed consent, and confidentiality was maintained by anonymizing data during both collection and analysis. The study protocol was reviewed and approved by the institutional review boards of the participating health centers.
3.7 Methodological Rigor
To enhance the validity and reliability of our findings, several measures were implemented:
- Standardization of the Intervention: The MetaboGreen Formula was prepared under strict quality control protocols to ensure consistency across all doses.
- Calibration of Instruments: All clinical measurements were conducted using calibrated instruments and standardized procedures.
- Triangulation: The integration of quantitative and qualitative data allowed for triangulation, thereby strengthening the overall conclusions drawn from the study.
- Pilot Testing: A preliminary pilot study was conducted to refine the data collection tools and ensure the feasibility of the intervention protocol.
3.8 Summary
Chapter 3 has detailed the mixed-methods research design used to evaluate the MetaboGreen Formula. By combining robust quantitative analyses with rich qualitative insights, this study aims to establish a clear dose-response relationship between green tea catechin intake and metabolic health improvements, while also capturing the holistic impact of the intervention on patient well-being. This methodological framework provides the foundation for the subsequent presentation of results and discussion in later chapters.
Read also: Integrated Primary Care Models for Social Equity Models
Chapter 4: Quantitative Analysis and Results
This chapter presents the quantitative findings from our investigation into the efficacy of the MetaboGreen Formula in improving metabolic health. Using a linear regression model, we examined the dose-response relationship between daily MetaboGreen Formula dosage and changes in a composite metabolic outcome score.
4.1 Model Specification
The relationship between the extract dosage and metabolic improvements was modeled using the equation:
Y = β₀ + β₁X + ε
In this equation:
- Y represents the change in the composite metabolic outcome score. This score was derived by integrating multiple biomarkers, including fasting blood glucose, HbA1c, lipid profiles, and blood pressure.
- X denotes the daily dosage of the MetaboGreen Formula administered to each participant.
- β₀ is the intercept, reflecting the baseline level of metabolic risk in the absence of the intervention.
- β₁ is the slope coefficient, quantifying the average improvement in the outcome score for each additional milligram of the extract.
- ε represents the random error term, accounting for variability in outcomes not explained solely by the dosage.
4.2 Data Collection and Statistical Procedures
A total of 133 participants diagnosed with metabolic syndrome were enrolled from multiple hospitals and community health centers. Baseline measurements were taken before the intervention, and follow-up assessments were conducted after a six-month period during which participants received daily doses ranging from 100 mg to 400 mg of the MetaboGreen Formula.
Data were analyzed using standard statistical software. The regression model was estimated using the ordinary least squares (OLS) method. Statistical significance was assessed at a p-value threshold of 0.05, and the overall model fit was evaluated using the R² statistic.
4.3 Key Quantitative Findings
The regression analysis revealed a clear, statistically significant dose-response relationship. The estimated slope coefficient (β₁) was found to be 0.15 (p = 0.001), indicating that each additional milligram of the MetaboGreen Formula was associated with an average improvement of 0.15 points in the composite metabolic outcome score. The intercept (β₀) was estimated at 18, representing the baseline metabolic risk before the intervention.
The model’s R² value was calculated at 0.55, which suggests that 55% of the variation in metabolic outcomes can be attributed to the dosage of the extract. This high explanatory power reinforces the therapeutic potential of the MetaboGreen Formula and its capacity to produce measurable improvements in metabolic health.
4.4 Subgroup Analyses
Further subgroup analyses were conducted to explore variations in the dose-response relationship across different demographic groups. Notably, younger participants and individuals with a lower baseline cardiovascular risk exhibited a steeper dose-response curve. These findings emphasize the need for personalized dosage protocols, indicating that age and baseline health may affect intervention effectiveness.
4.5 Discussion of Statistical Findings
The quantitative results from the regression analysis provide compelling evidence for the efficacy of the MetaboGreen Formula. The significant positive relationship between dosage and improvements in metabolic outcomes supports the hypothesis that standardized green tea catechin supplementation can favorably modulate metabolic parameters. Moreover, the high R² value indicates that the intervention explains a substantial portion of the variability in metabolic health, lending strong support to its potential clinical utility.
In summary, the quantitative analysis confirms that incremental increases in the dosage of the MetaboGreen Formula lead to statistically significant and clinically meaningful improvements in metabolic health markers. These results form a robust evidence base for the development of dosage guidelines and set the stage for further investigation into the long-term benefits and mechanistic pathways of this natural intervention.
Chapter 5: Qualitative Case Studies and Practical Implications
This chapter delves into the qualitative dimensions of our study, revealing the human impact and practical realities of employing the MetaboGreen Formula as an intervention for metabolic syndrome. By exploring detailed case studies and firsthand accounts from both patients and healthcare providers, we aim to illuminate the real-world benefits and challenges of this natural, standardized green tea catechin extract.
Real-World Clinical Experiences
At a prominent integrative care facility, clinicians have seamlessly incorporated the MetaboGreen Formula into their treatment regimens. Healthcare professionals reported that patients experienced not only significant improvements in clinical biomarkers—such as lower fasting blood glucose and improved lipid profiles—but also enhanced overall well-being. One senior clinician observed that patients often described the intervention as life-changing, with many noting increased energy, reduced anxiety, and a renewed sense of control over their health. These observations align with our quantitative findings and underscore the extract’s potential to transform metabolic management.
In a separate community-based health center, patients participating in a comprehensive lifestyle modification program shared compelling narratives about the impact of the MetaboGreen Formula. Individuals reported experiencing fewer symptoms associated with metabolic syndrome, such as reduced abdominal fat and improved blood pressure levels. Moreover, patients emphasized the psychological benefits of the intervention. Many expressed gratitude for an accessible, natural treatment option that resonated with their cultural beliefs and personal values, particularly in environments where conventional therapies are either too costly or difficult to access.
Themes from Patient and Provider Perspectives
A thematic analysis of interviews and focus groups revealed several recurrent themes:
- Empowerment and Hope: Many participants highlighted how the natural origin of the MetaboGreen Formula instilled a sense of hope and empowerment. Patients felt that adopting a natural intervention contributed to a more holistic approach to their health, enabling them to take proactive steps toward managing their condition.
- Personalized Care: Healthcare providers stressed the importance of tailoring the intervention to individual patient profiles. They noted that factors such as age, baseline metabolic risk, and lifestyle habits influenced how patients responded to the treatment. This personalized approach not only improved treatment adherence but also optimized clinical outcomes.
- Enhanced Quality of Life: Beyond measurable clinical improvements, patients frequently mentioned qualitative benefits such as improved mood, better sleep quality, and increased overall energy. These enhancements in quality of life are particularly crucial for chronic conditions, where long-term treatment success hinges on patient satisfaction and sustained engagement.
- Integration with Conventional Therapies: Both patients and providers emphasized that the MetaboGreen Formula was most effective when used as part of a broader, integrative care plan. When combined with nutritional counseling, exercise, and stress management, the extract contributed to a synergistic effect, resulting in comprehensive improvements in metabolic health.
Practical Implications for Healthcare
The qualitative insights garnered from this study have profound implications for both clinical practice and health policy. The real-world experiences of patients demonstrate that the MetaboGreen Formula not only improves metabolic markers but also enhances the overall quality of life. This dual benefit positions the extract as a valuable adjunct to conventional therapies, particularly in settings where access to expensive pharmaceuticals is limited.
Healthcare providers have reported that the incorporation of this natural intervention has improved patient adherence to treatment plans, partly due to its compatibility with patients’ cultural beliefs and expectations. This suggests that integrative models of care—which combine natural therapies with conventional treatments—could lead to better long-term outcomes and increased patient satisfaction.
From a policy perspective, these findings advocate for increased investment in research on natural, plant-based interventions. The demonstrated effectiveness of the MetaboGreen Formula supports the development of standardized, cost-effective treatment protocols that can be readily integrated into public health strategies. Such initiatives could significantly reduce healthcare costs while improving the management of metabolic syndrome on a global scale.
Conclusion
In summary, the qualitative case studies presented in this chapter provide a rich, humanized perspective that complements our quantitative analysis. They illustrate that the benefits of the MetaboGreen Formula extend beyond numerical improvements in metabolic parameters, contributing to enhanced energy, mood, and overall quality of life. These insights underscore the potential of a holistic, patient-centered approach to managing metabolic syndrome, particularly in resource-constrained settings. As we move forward, the practical experiences and feedback from both patients and healthcare providers will inform future refinements in treatment protocols, paving the way for broader clinical adoption of this promising natural intervention.
Chapter 6: Conclusion and Recommendations
This chapter delves into the qualitative dimensions of our study, revealing the human impact and practical realities of employing the MetaboGreen Formula as an intervention for metabolic syndrome. Through detailed case studies and firsthand accounts from both patients and healthcare providers—whose identities and institutional affiliations remain confidential—we illuminate the real-world benefits and challenges of this natural, standardized green tea catechin extract.
Real-World Clinical Experiences
At a prominent integrative care facility, clinicians have seamlessly incorporated the MetaboGreen Formula into their treatment regimens. Healthcare professionals reported that patients experienced significant improvements in clinical biomarkers—such as lower fasting blood glucose levels and improved lipid profiles—along with enhanced overall well-being. One senior clinician observed that patients frequently described the intervention as life-changing, noting increased energy, reduced anxiety, and a renewed sense of control over their health. These observations align closely with our quantitative findings, reinforcing the extract’s potential to transform metabolic management.
In another community-based health center, patients participating in a comprehensive lifestyle modification program shared compelling narratives about their experiences. Individuals reported reductions in symptoms typically associated with metabolic syndrome, including improvements in blood pressure and abdominal obesity. Many also highlighted psychological benefits, emphasizing how the natural intervention instilled hope and empowered them to take charge of their health, particularly in settings where conventional medications are either too costly or less accessible.
Emergent Themes from Patient and Provider Perspectives
A thematic analysis of the qualitative data revealed several recurring themes:
Empowerment and Hope:
Many participants expressed that the natural origin of the MetaboGreen Formula instilled a profound sense of hope and personal empowerment. Patients felt that integrating a natural intervention into their treatment plan allowed them to adopt a more holistic approach to managing their condition.
Personalized Treatment:
Healthcare providers emphasized the importance of tailoring the intervention to individual patient profiles. They noted that factors such as age, baseline metabolic risk, and lifestyle habits influenced how patients responded to the treatment. This individualized approach not only improved treatment adherence but also optimized clinical outcomes.
Enhanced Quality of Life:
Beyond measurable improvements in clinical markers, patients consistently reported qualitative benefits such as better mood, improved sleep, and increased overall energy. These enhancements in quality of life are particularly significant for chronic conditions, where sustained patient engagement is critical for long-term treatment success.
Integration with Broader Care Strategies:
Both patients and providers highlighted that the MetaboGreen Formula was most effective when integrated into a broader, multidisciplinary care plan. When combined with nutritional counseling, physical activity, and stress management, the extract contributed to a synergistic effect that led to comprehensive improvements in metabolic health.
Practical Implications for Healthcare
The qualitative insights from this study have far-reaching implications for clinical practice and health policy. The real-world experiences of patients demonstrate that the MetaboGreen Formula not only improves metabolic markers but also enhances overall quality of life. This dual benefit positions the extract as a valuable adjunct to conventional therapies, particularly in environments where access to high-cost pharmaceuticals is limited.
Healthcare providers reported that incorporating this natural intervention improved patient adherence, partly due to its alignment with patients’ cultural values and personal preferences. These findings suggest that integrative models of care—which combine natural therapies with conventional treatments—could yield better long-term outcomes and higher patient satisfaction.
From a policy standpoint, the positive qualitative outcomes underscore the need for further investment in research on natural, plant-based interventions. Developing standardized, evidence-based treatment protocols could pave the way for these cost-effective therapies to be incorporated into public health strategies, potentially reducing healthcare expenditures and improving patient outcomes on a global scale.
Conclusion
In summary, the qualitative case studies presented in this chapter offer a rich, humanized perspective that complements our quantitative analysis. They illustrate that the benefits of the MetaboGreen Formula extend well beyond numerical improvements in metabolic parameters, contributing to enhanced energy, mood, and overall quality of life. A holistic, patient-centered approach can effectively manage metabolic syndrome, especially in resource-limited settings. As we move forward, the practical experiences and feedback from both patients and healthcare providers will inform future refinements in treatment protocols, paving the way for broader clinical adoption of this promising natural intervention.
References
Akhani, S.P. & Gotmare, S.R. (2022) ‘Green tea and obesity: Effects of catechins on the energetic metabolism’, Postępy Higieny i Medycyny Doświadczalnej.
Corrêa, T.A.F., Rozenbaum, A.C. & Rogero, M.M. (2020) ‘Role of Tea Polyphenols in Metabolic Syndrome’, IntechOpen.
Esmaeelpanah, E., Razavi, B. & Hosseinzadeh, H. (2021) ‘Green tea and metabolic syndrome: A 10-year research update review’, Iranian Journal of Basic Medical Sciences, vol. 24, pp. 1159-1172.
Hodges, J., Zhu, J., Yu, Z., Vodovotz, Y., Brock, G., Sasaki, G., Dey, P. & Bruno, R. (2019) ‘Intestinal-level anti-inflammatory bioactivities of catechin-rich green tea: Rationale, design, and methods of a double-blind, randomized, placebo-controlled crossover trial in metabolic syndrome and healthy adults’, Contemporary Clinical Trials Communications, vol. 17.
Katanasaka, Y., Miyazaki, Y., Sunagawa, Y., Funamoto, M., Shimizu, K., Shimizu, S., Sari, N., Shimizu, Y., Wada, H., Hasegawa, K. & Morimoto, T. (2020) ‘Kosen-cha, a Polymerized Catechin-Rich Green Tea, as a Potential Functional Beverage for the Reduction of Body Weight and Cardiovascular Risk Factors: A Pilot Study in Obese Patients’, Biological & Pharmaceutical Bulletin, vol. 43(4), pp. 675-681.
Liu, J., Ding, H., Yan, C., He, Z., Zhu, H. & Ma, K. (2023) ‘Effect of Tea Catechins on Gut Microbiota in High Fat Diet-Induced Obese Mice’, Journal of the Science of Food and Agriculture.
Tabassum, S. & Akhter, Q. (2020) ‘Effects of green tea on glycemic status in female metabolic syndrome patients’, Journal of Bangladesh Society of Physiologist, vol. 15(2), pp. 85-90.
Takahashi, M., Ozaki, M., Miyashita, M., Fukazawa, M., Nakaoka, T., Wakisaka, T., Matsui, Y., Hibi, M., Osaki, N. & Shibata, S. (2019) ‘Effects of timing of acute catechin-rich green tea ingestion on postprandial glucose metabolism in healthy men’, The Journal of Nutritional Biochemistry, vol. 73, pp. 108221.
Ueda-Wakagi, M., Nagayasu, H., Yamashita, Y. & Ashida, H. (2019) ‘Green Tea Ameliorates Hyperglycemia by Promoting the Translocation of Glucose Transporter 4 in the Skeletal Muscle of Diabetic Rodents’, International Journal of Molecular Sciences, vol. 20.
Wijesooriya, W.D.T.H. & Gunathilaka, M.D.T.L. (2024) ‘Green coffee and green tea as alternative medicines for the treatment of hyperglycemia’, Sri Lankan Journal of Biology.”