

Applied Decision Models for Technical Risk, Reliability, and Systems Execution
A DOCTORAL PUBLICATION
Samuel A. Nneke
New York Center for Advanced Research (NYCAR)
Research Division — Engineering Systems and Decision Science
Date: June 2026
Publication No.: NYCAR-TTR-2026-RP046
DOI: https://doi.org/10.5281/zenodo.20581384
Peer Review Status: This doctoral publication has undergone independent peer review conducted under the joint editorial framework of the New York Center for Advanced Research (NYCAR) and The Thinkers’ Review. Independent reviewers assessed the manuscript for academic coherence, source integrity, technical and mathematical rigor, methodological soundness, engineering voice, and APA 7th edition alignment. Each quantitative result was independently re-derived, every cited source independently verified, and the work cleared for release only on the basis of that independent assessment.
Table of Contents
Abstract
Engineering mathematics is usually hidden behind the finished object: the aircraft that returns safely, the rover that lands between hazards, the power grid that holds frequency after a generator trips, the bridge that does not fatigue under repeated loading, and the factory process that keeps tolerance despite heat, vibration, and material variation. The discipline earns its value at the point where physical judgment must become computable without becoming naïve. Competent engineers do not solve hard problems by writing equations for their own elegance. They reduce uncertainty, expose impossible trade-offs, test design margins, and decide which risks can be accepted before a technical choice becomes irreversible.
The work that follows treats engineering mathematics as a practical decision discipline for complex technical problem-solving. The concern is not classroom mathematics separated from engineering consequence, but the working mathematics used in systems design, reliability analysis, optimization, control, simulation, measurement, and verification. Public case evidence is drawn from the NASA Apollo 13 crisis, NASA Mars 2020 and Perseverance terrain-relative navigation, Great Britain’s electricity-system operability work under low-carbon transition pressure, and the verification, validation, and uncertainty-quantification practice codified by NIST and ASME. These cases span different technologies and different stakes, yet they share one operating truth: a technical problem becomes solvable once constraints are measured, assumptions are named, the model is checked against reality, and the decision stays tied to physical consequence.
Three applied tools are developed for managers and technical teams: an Engineering Model Credibility Index, a Constraint-Resolution Priority Matrix, and a Reliability and Uncertainty Exposure Score. None is offered as a universal formula. Each is a structured prompt for engineering judgment, with worked numerical illustrations that show how the scores behave and where they can be abused. A high-fidelity simulation with poor validation should not be trusted because it looks sophisticated. A mathematically optimal design that fails manufacturing tolerance is not optimal in the real system. A control strategy that performs under nominal conditions but collapses under disturbance is not robust. The argument closes on a single standard: engineering mathematics should be judged by disciplined usefulness — whether it clarifies the problem, protects safety margins, improves technical decisions, and keeps complex systems from being governed by intuition alone.
Keywords: engineering mathematics, complex technical problem-solving, reliability analysis, optimization, uncertainty quantification, verification and validation, control systems, model credibility, NASA, National Grid, NIST, ASME, NYCAR.
Document map: Abstract · Chapter 1 Introduction · Chapter 2 Technical Foundations and Literature Review · Chapter 3 Methodology and Applied Quantitative Framework · Chapter 4 Public Case Evidence · Chapter 5 Analysis and Discussion · Chapter 6 Recommendations and Professional Standards · Chapter 7 Conclusion · References · Internal Editorial Review Report.
Chapter 1: Introduction
1.1 Problem Setting
Complex technical problems do not arrive as clean exercises. They arrive with partial measurements, competing objectives, damaged hardware, incomplete models, stressed teams, limited time, and consequences that can move from financial loss to human harm in a few bad decisions. A power grid cannot pause while engineers debate perfect theory. A spacecraft cannot wait for a complete laboratory replication of a fault. A bridge, aircraft, medical device, pipeline, data center, or automated production line is already embedded in material reality by the time its problem becomes visible. Engineering mathematics matters because it gives teams a disciplined way to think when the physical system refuses to simplify itself.
The weak reading of engineering mathematics treats it as calculation. The stronger reading treats it as constraint discipline. A model identifies what must be conserved, bounded, estimated, optimized, monitored, or rejected. A differential equation describes change only when the state variables and boundary conditions have been chosen honestly. A finite element mesh produces insight only when the load path, material model, contact assumptions, and validation evidence deserve confidence. A reliability equation helps only when failure modes have not been hidden for convenience. That distinction separates technical maturity from mathematical theatre, and it runs through every case examined later.
Modern engineering raises the difficulty because systems are increasingly coupled. Software changes hardware behavior. Sensors change maintenance strategy. Cloud computation changes operations. Renewable generation changes grid stability. Additive manufacturing changes material variation. Autonomy changes how uncertainty must be handled. A technical issue that once belonged to one discipline now crosses mechanics, electronics, software, data science, control, human factors, regulation, supply chains, and finance. The mathematics has to travel across those boundaries without losing physical meaning, and the people who own it have to travel with it.
The aim here is to examine the managerial and engineering value of that discipline. The concern is neither to celebrate mathematics as pure abstraction nor to reduce complex work to formulas. The concern is to show how engineering mathematics lets competent teams impose order on uncertainty, choose between imperfect options, and defend technical decisions in front of safety boards, regulators, operators, executives, and the public. Used well, mathematics makes assumptions visible. Used badly, it hides them behind precision, and a hidden assumption is the most expensive line item in any engineering programme.
1.2 Aim and Objectives
The aim of this research publication is to examine engineering mathematics as an applied problem-solving capability in technically complex environments. Mathematical modeling, optimization, reliability analysis, simulation, verification, validation, and uncertainty quantification are treated as parts of one decision system rather than as separate academic specialisms. The intent is not to produce a specialist monograph in a single branch of applied mathematics, but to show how mathematical reasoning supports engineering judgment when failure, cost, time, and operational constraints have to be managed together.
Five objectives organize the work. The leading objective is to clarify the difference between mathematical calculation and engineering model credibility, because the two are routinely confused in practice. A second objective reviews the foundations most relevant to high-consequence technical decisions — dimensional analysis, dynamic systems, optimization, reliability, control, simulation, and uncertainty. A third objective develops practical indices and diagnostic models that technical managers can adapt to real projects, complete with worked examples. A fourth objective analyzes documented public case studies from organizations whose technical challenges are a matter of record, including NASA, National Grid Electricity System Operator, NIST, and the professional verification communities served by ASME. A closing objective proposes a disciplined standard for deciding when an engineering model is credible enough to influence design, operation, or crisis response.
1.3 Research Questions
The inquiry is built around a set of connected questions. How should engineering mathematics be understood when technical problems involve physical uncertainty, operational pressure, and institutional accountability at the same time? Which mathematical tools are most useful for solving complex technical issues without oversimplifying the system they describe? How should engineers judge the credibility of simulations and analytical models before decisions come to depend on them? What can public case studies reveal about trajectory correction, autonomous navigation, power-system stability, and computational model validation? Which management practices keep mathematical analysis from drifting away from physical evidence, operator knowledge, and safety margins?
These questions are deliberately practical. They assume the reader already accepts the value of mathematics; the harder issue is governance — who owns assumptions, how errors are detected, where uncertainty is carried, and when a result is mature enough to guide action. In serious engineering, a number is not persuasive merely because it has decimals. It becomes persuasive when the chain from measurement to model to decision has survived scrutiny, and when someone with authority is willing to put their name on that chain.
1.4 Significance of the Work
The significance of the argument lies in the gap between technical complexity and decision confidence. Organizations are surrounded by models: digital twins, simulations, dashboards, forecasts, optimization engines, reliability tools, and automated diagnostics. Many of those tools are valuable. Some are fragile. Others are trusted well beyond what the evidence permits. Engineering leaders need a way to ask not only whether a model is advanced, but whether it is relevant, verified, validated, calibrated, explainable, and safe enough for the specific decision in front of them.
The topic also matters because mathematical failure is rarely announced as mathematical failure. It surfaces as underestimated load, poor tolerance stack-up, unstable control behavior, hidden fatigue, false precision, overfitted forecasting, brittle automation, or a plan that looked optimal until the real system moved outside its assumptions. The public sees a bridge closure, a grid warning, a mission delay, a production defect, or a safety incident. Inside the engineering record, the cause often traces back to a weak model, a missed boundary condition, a neglected uncertainty, or a decision-maker who accepted a calculation without asking what it left out.
1.5 Scope and Limitations
Several boundaries should be stated plainly so the contribution is not over-read. The analysis is integrative rather than experimental; it does not estimate empirical coefficients from a controlled dataset, and the weights proposed in the diagnostic tools are provisional values meant for expert recalibration, not validated constants. The case evidence is restricted to public, citable material, which protects against confidentiality problems but also means the internal engineering records of each programme are visible only through what their owning institutions chose to publish. The mathematical treatment favors breadth across disciplines over depth in any one method, on the judgment that decision-makers gain more from seeing how the tools connect than from a single exhaustive derivation. Where depth matters — reliability models, verification error, control stability — the relevant equations are stated and their assumptions named, so the reader can see exactly where credibility is conditional.
A further limitation is cultural rather than technical. The recommendations assume an organization willing to let mathematical evidence override schedule pressure when safety is at stake. In settings where that willingness is absent, no index or matrix will substitute for the missing governance, and the tools should be read as instruments for organizations that already want to think clearly, not as a cure for organizations that do not.
1.6 Positioning Relative to Existing Frameworks
The argument advanced here does not arrive on empty ground. Model verification and validation has a mature literature in computational mechanics, codified in community standards that distinguish verification, the question of whether the equations are solved correctly, from validation, the question of whether the correct equations are being solved. Reliability engineering has an equally mature apparatus of failure-mode analysis, fault trees, and probabilistic risk assessment. Decision analysis offers structured methods for ranking actions under uncertainty. The contribution of this work is not to displace any of these traditions but to connect them, because in everyday engineering practice they are too often kept in separate documents owned by separate specialists, and the decision that needs all three at once receives none of them in an integrated form.
Where the established verification-and-validation standards concentrate on the technical adequacy of a model in isolation, the instruments proposed here ask the adjacent question that those standards leave implicit: given a model of known and limited credibility, how much should it be allowed to influence a specific decision with specific stakes. That question is unavoidably about governance and consequence, not only about numerical accuracy, and it is the question that determines whether a sound model is used well or a flawed model is used recklessly. The three instruments are therefore best read as a translation layer between the deep technical practices that assess a model and the organizational decisions that consume it, rather than as a replacement for either.
This positioning also clarifies the work’s scope. It does not propose new numerical methods, new reliability mathematics, or new decision theory; each of those fields is deeper than any single framework could summarize. It proposes a disciplined way of bringing their outputs to bear on the moment of decision, expressed in instruments simple enough that a working team will actually use them and structured enough that their use leaves an auditable trace. A contribution of this kind is judged less by mathematical novelty than by whether it changes behavior in the room where the decision is made, which is the standard against which the case studies and the implementation guidance should be read.
Chapter 2: Technical Foundations and Literature Review
2.1 Engineering Mathematics as Working Judgment
Engineering mathematics begins with a severe demand: the abstraction must still answer to the object. A beam model must answer to a beam. A navigation filter must answer to a moving vehicle. A thermal model must answer to heat flow through material, joints, coatings, and ambient conditions. When the model is beautiful but the boundary conditions are fantasy, the beauty is irrelevant. Working engineers know this instinctively, and the literature on systems engineering, verification, validation, and uncertainty quantification gives the instinct formal structure rather than replacing it.
NASA’s Systems Engineering Handbook (National Aeronautics and Space Administration [NASA], 2016) frames systems engineering as a methodical, multidisciplinary approach spanning the design, realization, technical management, operation, and retirement of a system, and it links analysis directly to the use of mathematical modeling and analytical techniques for predicting compliance with requirements. That framing places mathematics inside a project life cycle rather than outside it. A calculation does not stand alone; it supports requirements, design choices, verification evidence, risk management, operations, and disposal. Mathematical work that cannot be connected to a system decision becomes intellectual residue rather than engineering evidence, and a mature programme treats it accordingly.
The practical distinction between calculation and judgment is visible in most major technical programmes. A load calculation may be correct under its assumptions yet useless when the design is manufactured to different tolerances. A forecast may be statistically elegant yet operationally dangerous when its tail risks drive safety. A control system may behave well in simulation yet fail when sensor noise, actuator delay, or human intervention changes the loop. Engineering mathematics is therefore judged by fit — fit to the decision, fit to the scale, fit to the evidence, and fit to the consequence of being wrong. The remainder of this chapter walks through the foundations that recur across the case evidence, with that test of fit kept in view throughout.
2.2 Dimensional Analysis, Scaling, and Physical Sanity
Dimensional analysis is one of the least glamorous and most protective habits in engineering. Before a team trusts a complicated model, it should know whether the quantities make physical sense. Units catch errors that sophistication misses. Scaling arguments expose impossible expectations. Non-dimensional numbers often reveal which forces dominate before detailed computation begins. Reynolds number, Mach number, Froude number, Biot number, Strouhal number, and dimensionless stiffness ratios are not academic decoration; they are compact tests of physical regime that a competent reviewer can apply in minutes.
The Buckingham Pi theorem formalizes the intuition: a physical relationship among n variables expressed in k independent dimensions can be rewritten as a relationship among n minus k dimensionless groups. The value is not the reduction of variables alone; it is the discipline of asking which combinations actually govern behavior. A heat-transfer correlation written in dimensionless form transfers across geometries that a dimensional fit cannot. A model that cannot be expressed in consistent dimensionless terms usually conceals a confusion about what it is really computing.
The habit matters because complex systems invite numerical seduction. A simulation may generate contour plots, convergence histories, and polished animations while the physical scale is wrong. A cost-optimization model may treat time as linear when delays compound. A structural model may report stress to four significant figures while the real uncertainty lives in the load assumptions. Dimensional analysis cannot solve every problem, but it frequently prevents teams from solving the wrong one, and it does so cheaply enough that skipping it is rarely defensible.
Scaling also protects against naïve transfer. A prototype that works at laboratory scale may fail at production scale because heat transfer, friction, turbulence, vibration, or material variability changes regime. A control strategy tuned in a quiet environment may behave differently under field noise. A process that appears efficient in a pilot plant may turn unstable once batch size, residence time, or mixing geometry change. Engineering mathematics therefore keeps asking whether the model has crossed a regime boundary that the project’s language has failed to notice — the kind of boundary that turns a validated correlation into a confident error.
2.3 Optimization Under Constraint
Optimization is often misunderstood as the search for the best answer. In serious engineering, it is the disciplined search for the best admissible compromise. The design must meet safety limits, cost limits, manufacturability limits, weight limits, thermal limits, control limits, maintenance limits, regulatory limits, and operating limits at once. Optimizing one variable while quietly violating another produces a number that may be mathematically clean and technically unusable.
Constrained optimization is most valuable where trade-offs are unavoidable. Aerospace design balances mass, fuel, thrust, structural strength, thermal protection, reliability, and mission envelope. Power-system operation balances generation, demand, frequency stability, reserves, inertia, emissions, and cost. Manufacturing balances throughput, yield, tolerance, energy use, maintenance, and quality risk. In each setting the mathematical task is not to maximize ambition but to locate feasible movement — the direction in design space that improves the objective without breaching a constraint that cannot be breached.
Formally, the engineer minimizes an objective f(x) subject to inequality constraints g_i(x) less than or equal to zero and equality constraints h_j(x) equal to zero. The Karush-Kuhn-Tucker conditions describe the stationary point where the gradient of the objective is balanced by a weighted sum of constraint gradients, with the multipliers revealing which constraints are active. Those multipliers carry engineering meaning: a large multiplier on a weight constraint says that relaxing weight would buy a large improvement elsewhere, which is precisely the kind of trade-off a design review should discuss rather than bury. An optimum where no constraint is active is often a sign that the model has been posed too loosely to be useful.
A workable optimization framework begins with three questions that sound simple and rarely are: what is the objective, what cannot be violated, and how will uncertainty change the result? The objective may represent cost, weight, time, energy, risk, reliability, or value. Constraints may be hard or soft. Uncertainty may enter through loads, demand, weather, human behavior, material properties, sensor error, or market conditions. A model that ignores uncertainty can be useful for exploration, but it should not be treated as final engineering direction once the real system is known to be disturbed. Robust and stochastic optimization exist precisely to keep the answer honest when the inputs are not fixed.
2.4 Reliability, Failure Probability, and Technical Risk
Reliability mathematics gives engineers a language for the uncomfortable fact that systems can satisfy design intent and still fail. Reliability is not the same as quality inspection. It is the probability that a system performs its required function for a specified time under stated conditions. That phrase carries several traps. The function must be defined. The time interval must be defined. The operating conditions must be stated. A reliability claim without those boundaries is vague reassurance dressed as a number.
The familiar exponential model R(t) = exp(−λt) is useful when the failure rate λ can be treated as constant, but many engineering systems do not behave so simply.
R(t) = exp(−λt), with hazard rate h(t) = λ constant only during useful life.
Early-life failures, wear-out behavior, common-cause events, maintenance quality, environmental stress, software faults, operator action, and aging all break the constant-rate assumption. The familiar bathtub curve captures this: a decreasing hazard during infant mortality, a roughly flat hazard during useful life, and an increasing hazard during wear-out. The two-parameter Weibull distribution, with shape parameter beta and scale parameter eta, spans all three regimes — beta less than one for infant mortality, beta near one for the constant-rate region, and beta greater than one for wear-out — which is why it is the workhorse of life-data analysis. Fault trees, event trees, Markov chains, Bayesian updating, Monte Carlo simulation, and physics-of-failure methods extend the toolkit further. Selection of the model should follow the failure mechanism, not analyst habit or software default.
Reliability analysis also changes the culture of technical conversation. Instead of asking only whether a design works, the team asks how it fails, how failure propagates, whether failure is detectable, whether redundancy is real, and whether maintenance restores the intended state. In high-consequence systems a single component may meet its specification while the system stays vulnerable to coupling, software logic, human response, or maintenance delay. The mathematics should force those vulnerabilities into the open, which is exactly what the Reliability and Uncertainty Exposure Score introduced in Chapter 3 is designed to do.
2.5 Verification, Validation, and Uncertainty Quantification
Verification and validation are not interchangeable rituals. Verification asks whether the model or code solves the equations correctly. Validation asks whether those equations and assumptions represent the real system adequately for the intended use. Uncertainty quantification asks how much confidence should be placed in the result once input uncertainty, numerical error, model-form error, measurement error, and validation evidence have all been considered. Oberkampf and Roy (2010) give the canonical statement of this separation, and the verification, validation, and uncertainty-quantification standards of the American Society of Mechanical Engineers (ASME, 2006, 2009, 2024) exist because computational models have become influential enough that credibility must be disciplined rather than assumed.
Code verification and solution verification are distinct activities within the first question. Code verification confirms that the discrete algorithm converges to the governing equations, often through the method of manufactured solutions, which Roache (1998) helped establish. Solution verification estimates the discretization error in a specific calculation, typically through systematic mesh refinement and a grid-convergence index (Roy, 2005; American Institute of Aeronautics and Astronautics [AIAA], 1998). Skipping these steps and moving straight to comparison with experiment confuses two different sources of error and makes any apparent agreement difficult to trust, because a model can match data for the wrong reasons when numerical error and model-form error happen to cancel.
A summary of industrial verification, validation, and uncertainty-quantification procedures for simulation models (Raunak & Kuhn, 2021) stresses the sources of inaccuracy, the procedures for verification and validation, and the use of graded validation levels. The logic is not confined to fluid dynamics. The same structure applies across computational mechanics, thermal analysis, additive manufacturing (National Institute of Standards and Technology [NIST], 2024), structural dynamics, electromagnetics, and coupled multiphysics simulation. A model used for a low-risk screening decision does not require the same evidence as a model used for certification, mission safety, or the operation of public infrastructure. Credibility is graded because the stakes are graded.
Good practice changes the governing question from “is the model right?” to “is the model credible for this decision?” The shift matters because every model simplifies. Some simplifications are acceptable and some are lethal, and the difference depends on the decision rather than on the model in isolation. A simulation of a simple bracket may tolerate assumptions that would be indefensible in a coupled aeroelastic system. A model used for concept screening can be rough. A model used to authorize operation near a structural or thermal limit must be far stronger. Engineering mathematics matures at the moment it accepts that credibility is conditional and states the condition out loud.
2.6 Control, Estimation, and Feedback
Control theory supplies the mathematics for systems that must act while they are changing. A stable static design is not enough when the system is dynamic, sensed through imperfect measurements, and forced to respond in real time. Feedback loops, state estimation, observers, Kalman filters, robust control, model predictive control, and fault-tolerant control all exist because technical systems rarely sit still. Vehicles fly, grids fluctuate, robots move, temperatures drift, pressure waves propagate, and operators intervene at the least convenient moment.
Estimation is often the quiet center of control. A controller can act only on what it believes the state to be. The Kalman filter (Kalman, 1960) gives the optimal recursive estimate of a linear system’s state under Gaussian noise by blending a model prediction with a new measurement in proportion to their relative uncertainty. The same idea, extended and approximated, underlies the navigation filters that let a spacecraft know where it is. When sensor fusion is weak, a sophisticated control law will make confident decisions from poor information. When latency is ignored, the system responds to the past. When noise is treated as harmless, a controller chases fluctuations. When uncertainty is not bounded, the system can operate outside safe margins without knowing it.
Robust and predictive control address the gap between the nominal model and the real plant. Robust control seeks performance that degrades gracefully across a defined set of plant variations rather than performance that is excellent for one nominal model and brittle around it. Model predictive control repeatedly solves a constrained optimization over a finite horizon, which lets the controller respect actuator limits and safety constraints explicitly rather than hoping they are never reached. Both reflect the same engineering instinct that runs through this chapter: design for the disturbed system, not the convenient one.
2.7 Simulation, Digital Twins, and Model Governance
Simulation has become a central engineering instrument because it lets teams explore design space before physical testing becomes possible, expensive, or unsafe. Digital twins extend the idea by linking models with live operational data. Used well, these tools support predictive maintenance, performance monitoring, process optimization, and anomaly detection. Used carelessly, they manufacture false authority. A digital twin that is not maintained, calibrated, or connected to the right signals becomes a model wearing operational clothing, and the clothing is often more convincing than the model underneath.
Model governance is therefore a technical necessity rather than an administrative afterthought. Organizations need registers of models, owners, assumptions, validation evidence, version history, decision scope, uncertainty limits, and retirement triggers. The language sounds bureaucratic, but the function is pure engineering discipline. When a model changes without review, when input data drifts, when a parameter is reused outside its validation range, or when the operating environment shifts, the model can quietly lose credibility while its interface still looks reliable. The failure is silent precisely because the dashboard keeps rendering.
The rise of machine learning sharpens the issue. A physics-based model may fail because the physics is incomplete; a data-driven model may fail because the data does not represent future operating conditions. Hybrid models can be powerful, but they inherit both forms of risk and add the new risk of opacity. Engineering mathematics in the coming decade will increasingly require teams that can combine differential equations, statistics, optimization, software verification, and domain knowledge without letting any single method dominate the evidence. The governance question — who is accountable for this model in this decision — becomes more important, not less, as the methods grow more capable.
2.8 Human Factors and the Limits of Models
A foundation that the literature sometimes underweights is the human element inside the loop. Reason’s (1997) work on organizational accident causation and Rasmussen’s (1997) framing of risk management in dynamic socio-technical systems both show that complex failures rarely come from a single broken equation. They come from the migration of a whole system toward the boundary of safe operation under cost and workload pressure, with each local decision appearing reasonable at the time. A model that captures only the physical subsystem and ignores how operators, maintainers, and managers actually behave will misjudge where the real margin lies.
The practical consequence is that engineering mathematics should be embedded in a representation of the work as performed, not only the work as imagined. An emergency procedure that assumes unrealistic operator attention, an optimized maintenance interval that assumes a crew never defers a task, or an automation scheme that assumes a human will reliably take back control in two seconds are all mathematically clean and operationally fragile. The cases in Chapter 4 are partly stories about hardware, but they are equally stories about teams that understood, or failed to understand, the boundary between calculated behavior and human behavior.
2.9 Literature Gap
The literature on applied mathematics, systems engineering, verification, validation, reliability, and optimization is large and mature. The managerial gap is narrower but urgent. Technical leaders often need a practical structure for deciding how mathematical evidence should influence design and operations, and the specialist literature, while rich on method, offers less on judgment. Project teams need to know whether a method is mature enough for a given decision, whether uncertainty has been carried properly through the analysis, and whether the physical consequences of model error have been considered before the result is allowed to carry weight.
The contribution that follows sits in that gap. Rather than adding another method to an already crowded toolkit, the next chapter assembles the existing foundations into three diagnostic instruments aimed squarely at the decision: is this model credible enough to act on, which constraint should bind first, and how much hidden exposure is the system carrying? The instruments are deliberately simple to compute and deliberately hard to fake, which is the combination that survives contact with a real design review.
2.10 Numerical Methods and Discretization Error
Most engineering mathematics that matters in practice is not solved in closed form; it is solved numerically, and the numerical solution introduces its own error that has nothing to do with whether the underlying physics is right. A finite-element stress field, a finite-volume flow solution, and a time-stepped dynamic simulation are all approximations whose accuracy depends on mesh density, time-step size, element type, and solver tolerance. Treating the numerical answer as if it were the exact answer is one of the most common and least discussed errors in computational engineering, because the software rarely advertises its own discretization error on the same screen as the result.
Solution verification exists to quantify that error. Systematic mesh refinement, paired with a grid-convergence index, estimates how far a given solution sits from the mesh-independent answer and whether the solver is converging at its theoretical order of accuracy (Roy, 2005). When refinement does not reduce the error in the expected way, the problem is usually not the physics; it is a coding error, a singularity, a poorly posed boundary condition, or a solution that has not entered the asymptotic range. A team that reports a single-mesh result without a convergence study is reporting a number with an unknown error bar, and a decision built on that number inherits the unknown. The discipline is unglamorous and occasionally expensive, which is exactly why it is so often skipped and so often the root cause when a trusted simulation turns out to be wrong.
The managerial implication is that computational results should arrive with two error statements, not one. The first concerns model-form error, the gap between the equations and reality, which validation against experiment addresses. The second concerns numerical error, the gap between the discrete solution and the exact solution of those equations, which verification addresses. Confusing the two is how a model can appear validated while remaining numerically unconverged, agreeing with data only because two errors happened to cancel. The Engineering Model Credibility Index keeps the two separate by scoring verification and validation evidence as one weighted component while treating boundary-condition quality and uncertainty propagation as their own terms, so that a team cannot earn full marks by addressing one error and ignoring the other.
2.11 Probability, Statistics, and the Honest Error Bar
Probability and statistics enter engineering wherever a quantity is uncertain, which is almost everywhere once the system leaves the drawing board. Material properties scatter. Loads vary. Sensors carry noise. Manufacturing introduces tolerance. Demand fluctuates. The discipline is not the manipulation of distributions for their own sake; it is the honest expression of how much is not known and how that ignorance propagates into the decision. An engineer who reports a mean without a variance has reported half a result, and frequently the less important half, because the decision often turns on the tail rather than the center.
Two failures recur. The first is treating a fitted distribution as if it described the future when it only described a limited past, which is how a hundred-year load gets exceeded in year forty because the record was short and the climate or the usage changed. The second is propagating uncertainty through a nonlinear model by pushing the mean through and reporting the output, ignoring that the mean of a function is not the function of the mean. Monte Carlo propagation, polynomial chaos, and interval methods exist to handle this honestly, and the choice among them is itself an engineering judgment about how much the nonlinearity and the tail behavior matter for the decision at hand. None of these methods rescues a model whose input distributions were guessed; uncertainty quantification is only as honest as its inputs, which returns the burden to measurement discipline.
2.12 Coupled and Multiphysics Systems
The hardest contemporary problems are coupled: a structure that deforms changes the flow around it, which changes the load on the structure; a battery that heats changes its own chemistry, which changes how it heats; a control loop that acts on a plant changes the plant state the loop is trying to estimate. Coupling defeats the convenient habit of analyzing each subsystem in isolation and adding the results, because the interaction terms can dominate the behavior. Engineering mathematics for coupled systems has to represent the feedback between domains, and the credibility of such a model depends as much on the fidelity of the coupling as on the fidelity of each individual physics.
Coupling also reshapes uncertainty. An error in one subsystem can amplify through the interaction rather than staying contained, and a redundancy that looks robust in one domain can be defeated by a shared dependence in another. The Reliability and Uncertainty Exposure Score weights common-cause vulnerability heavily for exactly this reason: in a coupled system, the shared condition that links two supposedly independent paths is the failure that the component-level analysis never sees. A mature treatment of a coupled system therefore spends its scrutiny on the interfaces, because the interfaces are where the surprises live and where the isolated analyses quietly disagree with one another.
2.13 Linear Systems, Conditioning, and the Limits of Precision
A great deal of engineering computation reduces, somewhere in its interior, to the solution of a linear system. The deceptive feature of such systems is that a problem can be perfectly well-defined and still be nearly impossible to solve accurately, because the matrix that represents it is ill-conditioned. Conditioning measures how much a small perturbation in the input can be amplified into a large change in the output, and an ill-conditioned system amplifies the unavoidable rounding of finite-precision arithmetic and the unavoidable noise of measured inputs into an answer that may share few significant figures with the truth. The mathematics gives a clean warning in the form of the condition number, yet the warning is routinely ignored because the solver returns an answer without complaint.
The practical consequence is that an engineer cannot judge the trustworthiness of a computed result from the result alone. Two calculations can be set up identically, run on the same software, and return numbers of wildly different reliability because one problem was well-conditioned and the other was not. This is one of the clearest illustrations of the paper’s central theme: mathematical machinery that is internally flawless can still deliver an untrustworthy answer, and only an explicit examination of conditioning, residuals, and sensitivity reveals the difference. The Engineering Model Credibility Index folds this concern into its verification-evidence and sensitivity-analysis terms, because a team that has never examined the conditioning of its core computation cannot honestly claim to know its own numerical error.
2.14 Dimensional Analysis and the Discipline of Scaling
Dimensional analysis is among the oldest and most powerful tools in engineering mathematics, and it remains underused relative to its value. By insisting that equations be dimensionally consistent and by organizing variables into dimensionless groups, it reduces the number of independent parameters in a problem, exposes the scaling laws that govern behavior across size and speed, and catches a large class of formulation errors before any computation begins. A model that is dimensionally inconsistent is wrong regardless of how well it fits a particular data set, and a result that does not scale sensibly when its governing dimensionless groups are varied is a result to distrust.
Scaling discipline also guards against one of the most expensive errors in applied work: assuming that a result validated at one scale transfers to another. Behavior that is benign in a laboratory model can become dominant at full scale because a dimensionless group has crossed a threshold, and a design validated only at small scale carries a hidden extrapolation that the credibility index would flag under data sufficiency and misuse risk. Treating dimensional reasoning as a routine check rather than a textbook curiosity is one of the cheapest ways an organization can raise the baseline credibility of its mathematical work, because the check costs minutes and the error it prevents can cost a programme.
Chapter 3: Methodology and Applied Quantitative Framework
3.1 Research Design
The research design is integrative and applied. It combines literature-based synthesis, public case analysis, and the development of practical quantitative models for technical decision support. No confidential company data are used. The cases are drawn from public materials issued by NASA, National Grid Electricity System Operator, NIST, the ASME-linked verification communities, and related technical authorities. The design protects against legal and confidentiality problems while still grounding the analysis in real engineering situations rather than invented examples.
The method follows a four-step discipline that runs through every case. The opening step identifies technical settings in which mathematics carried operational consequence. The next step examines the type of mathematical reasoning involved — trajectory analysis, control, state estimation, simulation credibility, reliability, optimization, or power-system dynamics. A subsequent step extracts managerial lessons about evidence, constraints, uncertainty, and decision timing. The final step translates those lessons into tools that technical teams can adapt to their own projects. The sequence is deliberately repeatable so that a reader can apply it to a case the analysis does not cover.
This is not an empirical coefficient-estimation exercise, and it does not claim to prove universal weights for all engineering systems. The weighting in the proposed indices is provisional and should be recalibrated by domain experts. A nuclear safety case, an aerospace mission, a software-defined grid, a medical device, and a consumer product do not deserve identical risk weights, and any tool that pretends otherwise should be distrusted. The contribution is a usable structure for disciplined analysis, not a closed formula that removes the need for judgment.
3.2 Source Selection and Case Logic
Source selection prioritizes official and reputable public evidence. NASA materials support the Apollo 13 and Mars 2020 terrain-relative navigation cases because they document high-consequence engineering under mission constraints. National Grid Electricity System Operator materials are used because grid operability under low-carbon transition pressure is a current technical problem involving frequency, inertia, system stability, and balancing. NIST and ASME-linked materials are used because verification, validation, and uncertainty quantification provide the formal credibility framework behind computational engineering. Foundational texts — Oberkampf and Roy on verification and validation, Roache on computational verification, Kalman on estimation — anchor the methods in their primary literature rather than in secondary summaries.
The case logic is comparative by design. Each case was chosen to stress a different part of the mathematical decision system: crisis-time constraint management, autonomous estimation and guidance, dynamic stability under changing physics, and computational credibility under certification pressure. The comparison is what makes the cross-case lessons in Chapter 4 defensible, because a pattern that recurs across radically different technologies is more likely to reflect something real about engineering mathematics than a pattern observed in a single domain.
3.3 Engineering Model Credibility Index
The Engineering Model Credibility Index, abbreviated EMCI, is a diagnostic for judging whether a mathematical or computational model deserves influence over a technical decision. It is expressed as a weighted sum of eight positive components minus a misuse penalty.
EMCI = 0.18·FV + 0.16·VD + 0.14·BQ + 0.13·UP + 0.12·SA + 0.10·DS + 0.09·TR + 0.08·GO − 0.12·MU
FV is formulation validity, VD is verification and validation evidence, BQ is boundary-condition quality, UP is uncertainty propagation, SA is sensitivity analysis, DS is data sufficiency, TR is traceability, GO is governance ownership, and MU is misuse risk. Each component is scored from 0 to 100. The eight positive weights sum to exactly 1.00, so a model that scores perfectly on every positive component with zero misuse risk reaches 100, and the misuse penalty can pull a superficially strong model below the threshold an organization sets for action.
The weights are not universal. Formulation validity carries the highest weight because a model built on the wrong physics or the wrong decision logic cannot be rescued by later polish. Verification and validation evidence follows closely, because numerical sophistication does not prove credibility. Boundary-condition quality, uncertainty propagation, and sensitivity analysis carry substantial weight because they are the common failure points in complex technical work. Misuse risk enters as a penalty because even a strong model becomes dangerous the moment it is used outside the scope where its evidence applies.
Table 1
Engineering Model Credibility Index Components
| Component | Weight | Technical meaning |
| Formulation validity (FV) | 0.18 | The governing equations, assumptions, and abstractions match the physical or operational problem. |
| Verification and validation evidence (VD) | 0.16 | The implementation is checked, and the model has been compared against relevant evidence. |
| Boundary-condition quality (BQ) | 0.14 | Loads, inputs, interfaces, constraints, and operating envelopes are stated and defensible. |
| Uncertainty propagation (UP) | 0.13 | Input, numerical, model-form, and measurement uncertainty are carried into the result. |
| Sensitivity analysis (SA) | 0.12 | The team knows which variables drive the outcome and where the model is fragile. |
| Data sufficiency (DS) | 0.10 | Calibration and validation data are adequate for the intended decision. |
| Traceability (TR) | 0.09 | Assumptions, versions, sources, and decision links can be audited. |
| Governance ownership (GO) | 0.08 | A qualified owner controls use, update, limitation, and retirement of the model. |
| Misuse risk (MU) | −0.12 | Penalty for likely use outside the validated range or decision scope. |
Figure 1
Engineering Model Credibility Index component weights. Positive weights (navy) sum to 1.00; the misuse term (gold) enters as a penalty.
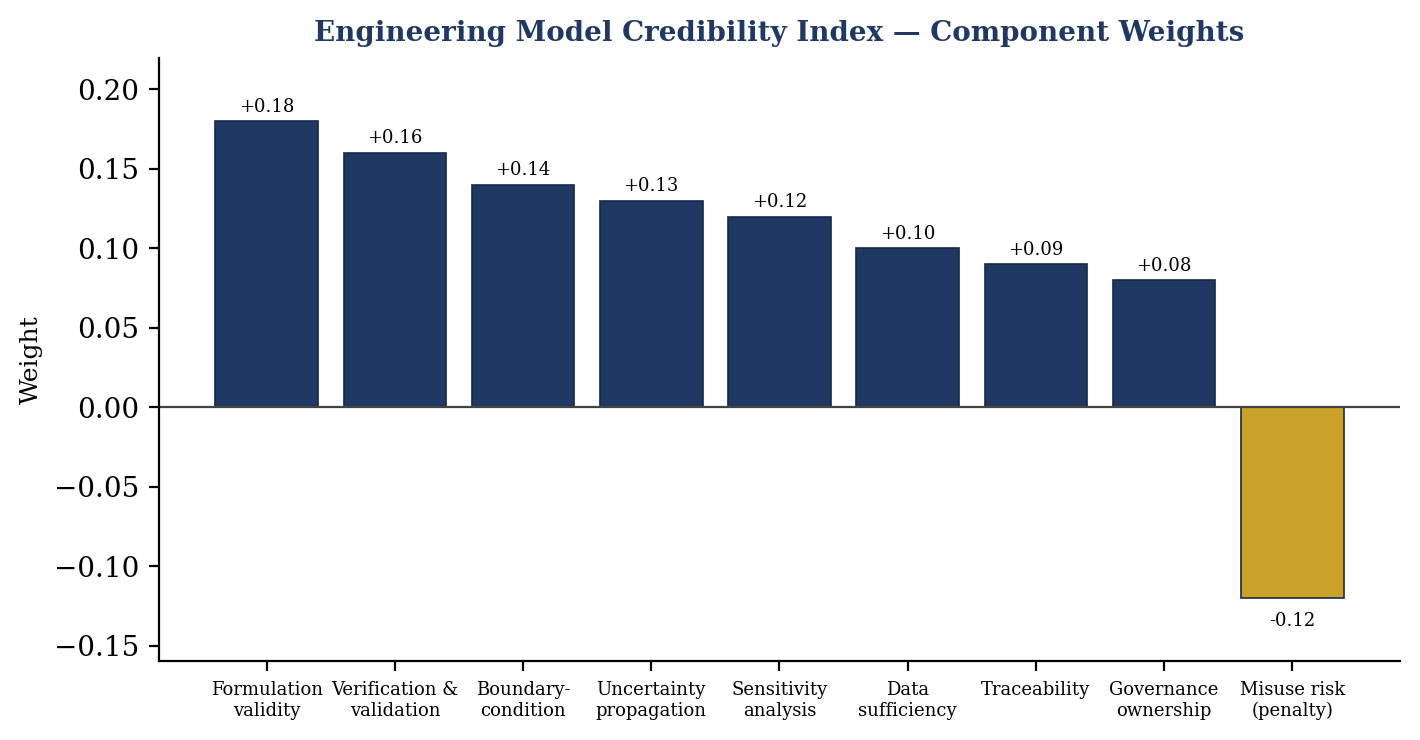
A worked illustration shows how the index disciplines a conversation. Consider a computational fluid-dynamics model proposed to justify operating a heat exchanger closer to a thermal limit. Suppose the review scores formulation validity at 85, verification and validation evidence at 55, boundary-condition quality at 60, uncertainty propagation at 40, sensitivity analysis at 50, data sufficiency at 45, traceability at 70, governance ownership at 65, and misuse risk at 60. The positive contribution is 0.18(85) + 0.16(55) + 0.14(60) + 0.13(40) + 0.12(50) + 0.10(45) + 0.09(70) + 0.08(65), which equals 15.3 + 8.8 + 8.4 + 5.2 + 6.0 + 4.5 + 6.3 + 5.2, or 59.7. The misuse penalty is 0.12(60), or 7.2, giving an EMCI of about 52.5. A model that looked authoritative in a slide deck lands in the middle of the scale, and the reason is visible: validation evidence, uncertainty propagation, and data sufficiency are weak for a decision that operates near a limit. The index does not forbid the decision; it tells the team exactly which evidence to strengthen before the decision earns its authority.
EMCI should be used as a conversation before it becomes a score. Disagreement among engineers is valuable because it exposes hidden assumptions. One analyst may believe validation is adequate because the model matched a single test. Another may know the operating regime will differ. A project manager may see traceability as paperwork; a safety engineer may see the same traceability as evidence survival after an incident. The scoring process forces those views into the same room and makes the disagreement explicit rather than letting it surface later as a surprise.
3.4 Constraint-Resolution Priority Matrix
Complex technical problems rarely fail because a single objective is difficult. They fail because objectives collide. The Constraint-Resolution Priority Matrix ranks constraints by safety criticality, irreversibility, uncertainty, time sensitivity, and cascading effect, so that scarce attention goes where violation is most consequential. A simplified composite score is written as a weighted sum whose weights again total 1.00.
CRP = 0.25·SC + 0.20·RV + 0.18·UN + 0.17·TS + 0.20·CE
SC is safety criticality, RV is irreversibility, UN is uncertainty, TS is time sensitivity, and CE is cascading effect. Higher scores demand earlier attention. The matrix is useful in crisis settings and in routine design reviews alike. During Apollo 13, power, trajectory, carbon-dioxide removal, water, thermal limits, and crew survival interacted at once. In grid operation, frequency, inertia, reserve, demand, generation mix, and weather interact continuously. In manufacturing, tolerance, throughput, quality, thermal behavior, and maintenance interact. The matrix keeps teams from treating the loudest problem as the most important one.
Table 2
Constraint-Resolution Priority Matrix
| Dimension | Diagnostic question | Why it matters |
| Safety criticality (SC) | Can violation cause injury, mission loss, or public harm? | Safety-critical constraints cannot be negotiated like cost preferences. |
| Irreversibility (RV) | Will a wrong action close future options? | Irreversible decisions need stronger evidence and clearer authority. |
| Uncertainty (UN) | How much is unknown about the constraint? | High uncertainty can turn an apparently safe margin into a fragile assumption. |
| Time sensitivity (TS) | Does delay change the feasible set? | Some technical choices lose value once the window closes. |
| Cascading effect (CE) | Can this constraint propagate into other subsystems? | Coupled systems punish narrow fixes that ignore the coupling. |
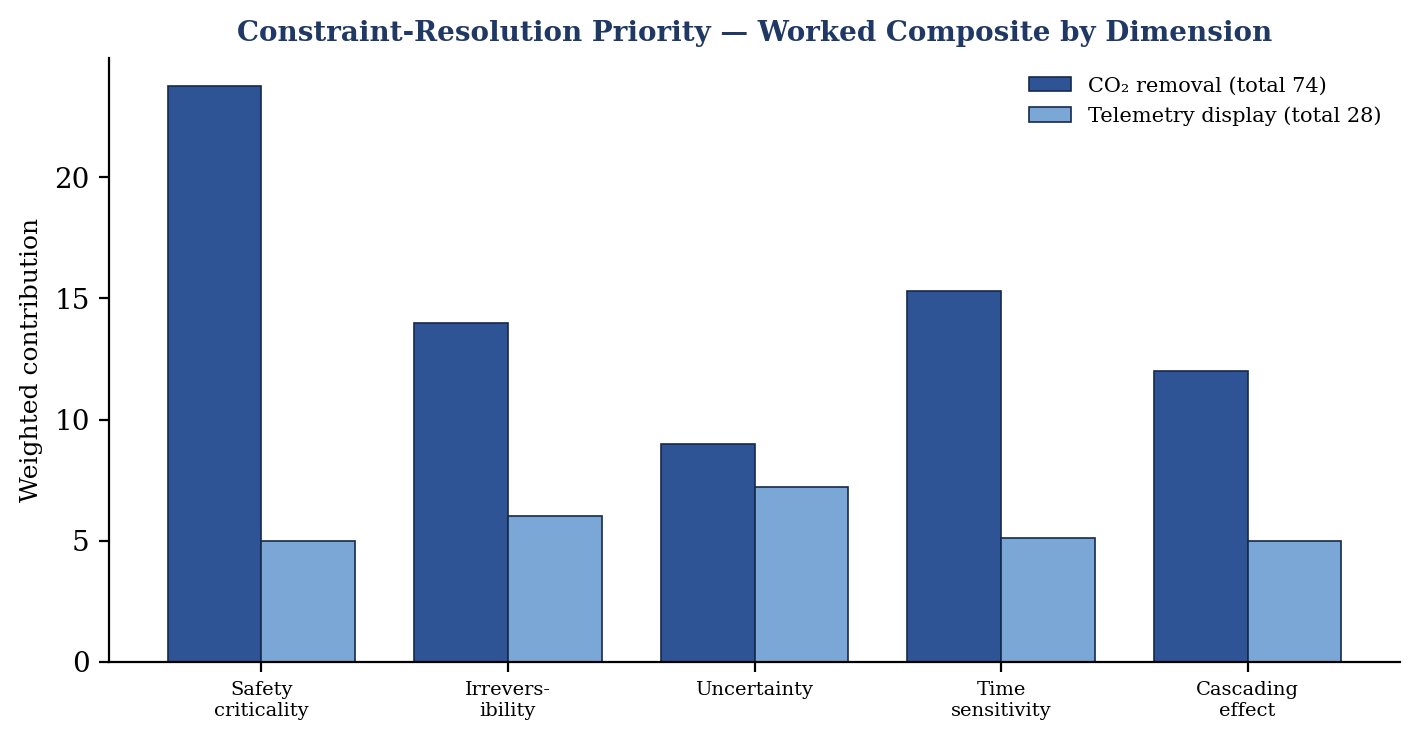
A short numerical example clarifies the ranking. In a crisis, suppose carbon-dioxide removal scores 95 on safety criticality, 70 on irreversibility, 50 on uncertainty, 90 on time sensitivity, and 60 on cascading effect, while a non-critical telemetry display scores 20, 30, 40, 30, and 25 on the same dimensions. The composite for carbon-dioxide removal is 0.25(95) + 0.20(70) + 0.18(50) + 0.17(90) + 0.20(60), which equals 23.75 + 14 + 9 + 15.3 + 12, or about 74. The telemetry display scores 0.25(20) + 0.20(30) + 0.18(40) + 0.17(30) + 0.20(25), which equals 5 + 6 + 7.2 + 5.1 + 5, or about 28. The gap is not a matter of opinion or volume; it is a structured statement that breathing air must be resolved before display cosmetics, and it survives the kind of pressure that distorts unaided judgment.
Figure 2
Constraint-Resolution Priority worked composite by dimension. Carbon-dioxide removal (74) outranks the telemetry display (28), driven chiefly by safety criticality and time sensitivity.
3.5 Reliability and Uncertainty Exposure Score
The Reliability and Uncertainty Exposure Score, abbreviated RUES, helps teams identify whether a technical system is operating with unacceptable hidden exposure. It is expressed as a weighted sum of seven components whose weights total 1.00.
RUES = 0.22·FM + 0.18·CM + 0.16·UF + 0.14·DD + 0.12·MD + 0.10·HR + 0.08·ER
FM is failure-mode severity, CM is common-cause vulnerability, UF is the uncertainty factor, DD is detectability deficit, MD is maintenance dependency, HR is human-response complexity, and ER is environmental range. A higher score signals larger exposure that calls for mitigation, more evidence, or operational restriction. The naming is deliberate. The instrument is not called a risk score because risk language is often diluted until it means nothing. Exposure emphasizes that the system carries a burden whether or not the team has chosen to notice it.
Table 3
Reliability and Uncertainty Exposure Score Components
| Component | Weight | Technical meaning |
| Failure-mode severity (FM) | 0.22 | How damaging the consequences are if the failure mode occurs. |
| Common-cause vulnerability (CM) | 0.18 | Whether redundant elements can fail together under a shared condition. |
| Uncertainty factor (UF) | 0.16 | How poorly the failure behavior and its drivers are characterized. |
| Detectability deficit (DD) | 0.14 | How hard the failure is to detect before it causes harm. |
| Maintenance dependency (MD) | 0.12 | How strongly safe operation relies on timely, correct maintenance. |
| Human-response complexity (HR) | 0.10 | How demanding the required operator response is under stress. |
| Environmental range (ER) | 0.08 | How wide and variable the operating environment is. |
Common-cause vulnerability matters because redundant components may fail together under a shared condition such as a common power supply, a shared software fault, or a single environmental insult. Detectability deficit matters because a failure mode that cannot be seen early is more dangerous than one that announces itself. Human-response complexity matters because an emergency procedure can fail when it assumes unrealistic attention, time, or training. A worked case makes the point: a redundant sensor pair sharing one power rail might score 80 on failure-mode severity, 90 on common-cause vulnerability, 60 on uncertainty, 70 on detectability deficit, 40 on maintenance dependency, 50 on human-response complexity, and 30 on environmental range, giving 0.22(80) + 0.18(90) + 0.16(60) + 0.14(70) + 0.12(40) + 0.10(50) + 0.08(30), or about 67. The high common-cause term flags that the redundancy is partly an illusion, which is precisely the exposure a component-level reliability number would have concealed.
RUES pairs naturally with reliability modeling. A component-level reliability estimate can look acceptable while system exposure stays high because the failure is hard to detect, affects multiple subsystems, or depends on hurried human interpretation. Technical managers should therefore use reliability numbers alongside failure-mode review, detectability analysis, and operational drills rather than treating a single probability as a complete safety answer. The three instruments are complementary: EMCI asks whether to trust the model, CRP asks which constraint to resolve first, and RUES asks how much the system is silently carrying.
3.6 Optimization and Sensitivity Protocol
The optimization protocol used here follows a practical sequence: define the objective, identify non-negotiable constraints, quantify uncertainty, run a baseline optimization, test sensitivity, examine boundary solutions, and compare the mathematical optimum against manufacturing, operational, and maintenance reality. The last step is the one that most often separates engineering from pure mathematics. A design can optimize a numerical objective while creating a maintenance burden, a supply-chain dependence, an inspection difficulty, or an operator confusion that the objective function never included.
Sensitivity analysis is not optional. When a result depends strongly on one poorly known parameter, the decision should shift from optimization to evidence acquisition, because buying information is worth more than refining a fragile answer. When many parameter changes push the design in the same direction, confidence improves. When the model flips its recommendation under small perturbations, leadership should not present the result as settled. The discipline is as useful for executives as for engineers, because it shows when a technical recommendation is robust and when it is a fragile artifact of assumptions that nobody has tested.
3.7 Validity, Reliability, and Ethical Safeguards
Because the three instruments are scoring tools applied by people, their own credibility must be defended. Construct validity is addressed by tying each component to a documented failure mode in the engineering literature rather than to intuition; content validity is addressed by covering formulation, evidence, uncertainty, and governance rather than any single dimension. Inter-rater reliability is supported by scoring each component independently before discussion, so that the spread of scores becomes diagnostic information rather than noise to be averaged away. The instruments are intended to be auditable: every score should carry a one-line justification that a later reviewer, or an incident investigator, can examine.
The ethical safeguard is the most important and the easiest to neglect. A scoring tool can be gamed to manufacture confidence, which would make it worse than no tool at all. The defense is to require evidence for high scores and to treat a high score with thin justification as a finding in itself. Used honestly, the instruments make optimism expensive and force teams to show their work; used dishonestly, they decorate a decision that has already been made. The difference is governance, and the recommendations in Chapter 6 exist to protect it.
3.8 Worked Integration: One Decision Through Three Lenses
The three instruments are most useful applied together to a single decision, because each answers a question the others do not. Consider a manufacturer deciding whether to certify a metal additive-manufactured bracket for a flight-critical load path on the strength of a process-and-structure simulation, rather than building the larger physical test campaign that tradition would require. The decision is attractive because the simulation is fast and the test campaign is slow and expensive, which is precisely the situation in which mathematical evidence is most likely to be over-trusted.
Running the Engineering Model Credibility Index first tells the team whether the simulation deserves to influence the certification at all. Suppose formulation validity scores 70 because the melt-pool and residual-stress physics are only partially represented, verification evidence scores 75, boundary-condition quality scores 65, uncertainty propagation scores 35, sensitivity analysis scores 45, data sufficiency scores 30 because the validation coupons do not span the build orientations of the real part, traceability scores 80, governance ownership scores 70, and misuse risk scores 70 because the model is being pushed toward a use its validation does not cover. The positive sum is 0.18(70) + 0.16(75) + 0.14(65) + 0.13(35) + 0.12(45) + 0.10(30) + 0.09(80) + 0.08(70), which equals 12.6 + 12.0 + 9.1 + 4.55 + 5.4 + 3.0 + 7.2 + 5.6, or about 59.45. The misuse penalty is 0.12(70), or 8.4, leaving an index near 51. For a flight-critical certification, that is well below any defensible threshold, and the low data-sufficiency and uncertainty-propagation terms point straight at what is missing.
The Constraint-Resolution Priority Matrix then orders what to fix. Structural integrity under fatigue loading scores high on safety criticality and irreversibility; build-orientation coverage in the validation data scores high on uncertainty; the certification deadline scores high on time sensitivity; and the possibility that an undetected residual-stress mode could affect a family of parts scores high on cascading effect. The matrix tells the team that closing the validation-data gap and characterizing the residual-stress failure mode must precede the certification decision, rather than being deferred as refinements. The Reliability and Uncertainty Exposure Score, applied to the bracket in service, then flags detectability deficit and common-cause vulnerability as the dominant exposures, because a residual-stress failure may not announce itself and may affect every part built in the same orientation. Read together, the three instruments convert a tempting shortcut into a clear, defensible programme: strengthen the validation data, characterize the dominant failure mode, and revisit the credibility index before the certification proceeds.
3.9 Calibrating the Weights for a Domain
The default weights in the three instruments are starting points, and an organization that adopts them without recalibration is misusing them in the same way it might misuse any borrowed model. A nuclear-safety case will raise the weight on failure-mode severity and verification evidence far above the defaults. A fast-moving consumer-product team will tolerate lower validation evidence for exploratory decisions while still refusing to relax safety criticality. A software-defined system will raise the weight on common-cause vulnerability because a shared code path can defeat redundancy that looks independent in hardware. The recalibration itself is a useful exercise, because the act of arguing about the weights forces a team to state what it actually values and fears, which is information worth having before a decision rather than after an incident.
A disciplined recalibration keeps each instrument’s positive weights summing to unity so that scores remain comparable across projects, documents the rationale for any departure from the defaults, and revisits the weights when the domain changes — a new regulatory regime, a new failure discovered in the field, a new class of model brought into service. The weights are not the contribution; the structured conversation they provoke is the contribution, and a frozen set of weights that nobody questions has already begun to decay into the false precision the instruments were built to resist.
3.10 Scoring Consistency and Inter-Rater Reliability
An instrument that depends on expert scoring inherits a methodological obligation that purely automatic measures avoid: it must demonstrate that different competent assessors, scoring the same model against the same evidence, arrive at compatible results. If two qualified engineers score the same model’s formulation validity at 40 and 80, the instrument is measuring the assessors rather than the model, and its outputs cannot support the auditable decisions it promises. Acknowledging this openly is part of using the instruments honestly, because the alternative — presenting a subjectively assigned score as if it carried the authority of a measurement — reproduces exactly the false precision the framework was built to resist.
Three practices keep scoring consistent enough to be useful. The first is anchored rubrics: each scoring band is tied to concrete, observable evidence, so that a score of 70 on verification evidence means a stated set of verification activities was performed and documented, not that the assessor felt reasonably confident. The second is paired scoring on consequential models, in which two assessors score independently and reconcile their differences in a recorded conversation, with the disagreement itself treated as information about where the evidence is ambiguous. The third is periodic calibration, in which a team re-scores a past model whose outcome is now known and compares its scores against what hindsight revealed, tightening the rubrics where the instrument proved optimistic. None of these practices makes the scoring objective in the sense that a length measurement is objective, but together they make it reproducible enough that the resulting decisions rest on the model rather than on the mood of the reviewer.
This is also the honest answer to the natural objection that the instruments merely dress subjective judgment in numerical clothing. The judgment is indeed subjective; the discipline lies in making it explicit, decomposed, anchored to evidence, and open to challenge, which is a categorical improvement over the unstructured and unrecorded judgment that the instruments replace. A decomposed judgment that two assessors can argue about term by term is more trustworthy than a holistic impression that no one can interrogate, and it is the structure, not a false claim of objectivity, that earns the instruments their place in a credible process.
Chapter 4: Public Case Evidence
4.1 NASA Apollo 13: Constraint Mathematics Under Crisis
Apollo 13 remains a severe case because it stripped engineering mathematics of comfort. The mission was meant to land on the Moon, but after the oxygen-tank explosion the problem changed into survival, navigation, energy management, carbon-dioxide control, and re-entry. NASA describes Apollo 13 as a mission that became a successful failure, and official mission materials describe the lunar module Aquarius being pressed into service as a lifeboat (NASA, 2020). The phrase can sound heroic; technically, it meant that a vehicle designed for one operating envelope had to be reassessed for another while three lives depended on the reassessment being right the first time.
The mathematics was not confined to a single calculation. Trajectory decisions had to return the spacecraft safely to Earth on a free-return path that the explosion had disturbed. Power budgets had to preserve enough energy for the operations that could not be skipped. Consumables had to be tracked under radically altered use. Thermal conditions had to be managed with very limited options. Carbon-dioxide removal required improvisation because the canisters intended for one module did not fit the other. Each decision narrowed or widened the feasible set, and the work became constraint management with no room for ornamental analysis. The Constraint-Resolution Priority Matrix in Chapter 3 is, in effect, an attempt to make that crisis reasoning teachable in calmer conditions.
Apollo 13 also shows why model credibility is contextual. Engineers and flight controllers did not need a perfect model of every physical detail. They needed analysis reliable enough for urgent decisions, backed by mission experience, ground simulations, test knowledge, and disciplined procedure. A slow perfect answer would have been useless and a fast careless answer would have been fatal. The achievement was not calculation alone but calibrated trust — knowing which approximations could be accepted and which constraints could not be violated under any circumstances.
For contemporary engineering management, the lesson is direct. Organizations should not wait for a crisis to learn their constraint structure. Power, thermal behavior, communications, supply, control authority, redundancy, data access, and human procedures should be mapped before they are needed. Apollo 13 is remembered as improvisation, but the improvisation was possible only because deep engineering preparation already existed; the crisis revealed the value of preparation that had been done years earlier and could not have been done in the moment.
4.2 NASA Mars 2020 and Perseverance: Navigation Between Hazards
Mars landing and rover navigation place mathematics inside a physical environment that cannot be negotiated with in real time. The communication delay between Earth and Mars rules out joystick control. The terrain is uneven. Dust, lighting, slopes, rocks, and uncertainty complicate perception. NASA’s account of terrain-relative navigation (NASA, 2021) explains how onboard imagery is matched against a stored map of the landing area to produce a map-relative position fix, allowing the descending spacecraft to retarget toward safer ground and away from hazards. That is engineering mathematics operating as autonomous judgment under time pressure measured in seconds.
The technical structure combines imaging, map matching, state estimation, guidance, and control. The system must infer where it is, compare that estimate against stored hazard maps, and adjust within a narrow landing timeline. The mathematics is impressive less because it is difficult in theory — though it is — and more because it must work inside a mission sequence where the correction window is short and the consequences are total. The estimator must be fast enough, accurate enough, and robust enough for the decision it controls, and there is no opportunity for a second attempt.
Perseverance surface navigation adds another layer. A rover crossing Martian terrain must balance science goals, energy, hazard avoidance, wheel protection, communication windows, and route efficiency at once. Research on learning-enhanced rover navigation (Daftry et al., 2022) has explored machine-learning heuristics while preserving model-based safety checks, a pattern that recurs across modern autonomy: data-driven methods may improve efficiency, but safety-critical decisions still require physics-aware guards and explicit verification. The machine learning proposes; the verified model disposes.
The case challenges a common misunderstanding about automation. Autonomy does not remove engineering responsibility; it relocates that responsibility into models, sensors, verification tests, software assurance, operational constraints, and fallback logic. Engineers remain accountable for the assumptions the autonomous system carries into a place where no one can intervene. A rover that makes a safe decision on Mars is the visible result of mathematical, software, and systems-engineering choices made long before the drive began, and the credibility of those choices is exactly what the Engineering Model Credibility Index is built to interrogate.
4.3 Great Britain’s Electricity System: Inertia, Frequency, and Operability
Power-system engineering shows that mathematics can become public service. Great Britain’s electricity system is changing as coal and gas generation decline and renewable resources expand. The National Grid Electricity System Operator’s public explanation of inertia (National Grid Electricity System Operator [NGESO], 2025b) notes that traditional coal and gas generators provide inertia as a by-product of their large spinning masses, while wind and solar do not couple to the grid in the same synchronous way. The System Operability Framework (NGESO, 2025a) takes a holistic view of the changing energy landscape to assess the requirements of future operation. Behind those plain statements sits a demanding mathematical problem: how to keep the system stable when the physical behavior of the generation fleet is itself changing.
Frequency control is not a theoretical concern. A grid must balance supply and demand second by second, and frequency is the visible signature of that balance. Inertia slows the rate of change of frequency after a disturbance; lower inertia means the system moves faster after a fault, leaving less time for corrective action. The swing equation that governs this behavior relates the rate of change of frequency to the imbalance between mechanical and electrical power divided by twice the system inertia constant, which is why a falling inertia constant directly shortens the time available to respond. The wider mathematics involves differential equations, dynamic stability, reserve sizing, probabilistic forecasting, control response, demand behavior, and contingency analysis. A secure grid is not secured against average conditions; it is secured against credible disturbances.
The low-carbon transition makes the problem technically and institutionally complex at the same time. Operators need new services, new markets, new controls, and new monitoring. Batteries, synchronous condensers, demand response, interconnectors, grid-forming inverters, and faster frequency-response services can all contribute, but each has its own technical behavior that must be modeled before it can be trusted. The system is far too large to manage by intuition. The mathematics decides how much response is needed, where it should sit, how fast it must act, and how the uncertainty in weather and demand should be carried through the decision.
The case matters because it connects engineering mathematics to public trust. Most consumers notice the grid only when it fails. They never see frequency stability, dynamic response, reserve margins, or the system studies that keep the lights on. The absence of failure is the product. Technical managers in this environment need models that are conservative enough for public reliability yet flexible enough to support decarbonization. False certainty can slow innovation; weak modeling can endanger stability. The leadership task is to hold both risks in view at once rather than collapsing into either complacency or paralysis.
4.4 NIST, ASME, and the Credibility of Computational Engineering
Computational engineering is now embedded in design, testing, certification, manufacturing, and operations, which creates a governance problem: when should a simulation be believed? Work on industrial verification, validation, and uncertainty quantification for simulation models (Raunak & Kuhn, 2021) addresses the sources of simulation inaccuracy and the procedures for assessing credibility. The verification, validation, and uncertainty-quantification resources of the American Society of Mechanical Engineers (ASME, 2024) similarly emphasize standards that help practitioners assess and improve the credibility of computational models. These frameworks are essential because modern engineering decisions increasingly depend on models too complex for casual review.
The issue is not whether simulation is useful; it is indispensable. The issue is whether simulation is being asked to do more than its evidence supports. Computational models can reduce physical testing, explore design space, and surface risks before prototypes exist. They can also mislead when mesh convergence is weak, turbulence models are unsuitable, material properties are uncertain, boundary conditions are wrong, or the validation data does not match the intended use. A colored contour plot is not a safety argument, however convincing it looks projected on a wall.
The additive-manufacturing model-validation work of the National Institute of Standards and Technology (NIST, 2024) makes the credibility problem even more current. Metal additive manufacturing involves process parameters, melt pools, thermal gradients, microstructure, residual stress, and final part properties that interact in ways still being characterized. Models can help, but only when measurement, statistical comparison, and validation datasets are strong enough to support the claim being made. This is engineering mathematics at the edge of manufacturing innovation: powerful, necessary, and dangerous when overtrusted, because the very novelty that makes the models valuable also means the validation evidence is still being assembled.
The managerial lesson is that model credibility must be budgeted like any other engineering resource. Organizations routinely fund software licenses and analyst time while underfunding validation experiments, metrology, data management, and uncertainty analysis. The economy is false. A model without credible validation may still be useful for learning, but it should not be permitted to carry certification, safety, or investment decisions as though its authority were already established. The Engineering Model Credibility Index exists partly to make that underfunding visible, because a low validation score is hard to ignore once it sits in a table next to a decision.
4.5 Cross-Case Lessons
The cases differ in technology, but the pattern is consistent. Apollo 13 required rapid constraint management under damage. Perseverance required autonomous estimation and guidance through uncertain terrain. Grid operability requires dynamic stability under changing generation physics. Computational engineering requires evidence discipline before simulation results acquire decision authority. In each setting, mathematics is valuable because it converts a confusing technical situation into controlled questions: what is conserved, what is uncertain, which constraint binds first, which model is credible, and which decision cannot wait.
The cases also warn against mathematical overconfidence. A model can be sophisticated and still wrong for the decision. A controller can be stable under nominal assumptions and dangerous under disturbance. A reliability estimate can ignore common-cause failure and report a comforting number. An optimization can land on a boundary point that cannot be manufactured, maintained, or operated safely. Engineering mathematics becomes professional only when it is paired with humility about the model’s limits, and the three diagnostic instruments are simply structured ways of enforcing that humility before a decision rather than discovering it after an incident.
4.6 Reading the Cases Through the Instruments
Applying the instruments retrospectively sharpens the lessons. An Engineering Model Credibility Index applied to the Apollo 13 trajectory work would score formulation validity and governance high, because the physics and the chain of authority were well understood, while honestly recording that data sufficiency was constrained by the damaged spacecraft. A Constraint-Resolution Priority Matrix applied to the same crisis would rank carbon-dioxide removal and trajectory above almost everything else on safety criticality and time sensitivity. A Reliability and Uncertainty Exposure Score applied to a low-inertia grid scenario would flag common-cause vulnerability and detectability deficit as the terms that deserve attention, because a fast frequency excursion gives operators little time to detect and respond.
The point of the exercise is not to re-litigate decisions made by skilled teams under real pressure. The point is to show that the instruments name, in advance and in ordinary language, the same factors that those teams managed through experience and discipline. A tool that merely re-describes good judgment is still useful, because it lets an organization extend that judgment to people and projects that have not yet earned it through years of exposure to consequence.
4.7 Structural Fatigue and the Mathematics of Slow Failure
Not every instructive failure is sudden. Some of the most consequential failures in civil and mechanical engineering are slow, accumulating invisibly through millions of load cycles until a crack reaches a critical length and the structure fails with little warning. Fatigue is the mathematics of slow failure, and it is a useful counterpoint to the crisis and autonomy cases because it shows engineering mathematics operating on a timescale of decades rather than seconds, where the danger is complacency rather than panic.
The fatigue problem is governed by the relationship between cyclic stress amplitude and the number of cycles to failure, classically captured in stress-life and strain-life curves and, for cracked components, by fracture-mechanics laws describing crack growth per cycle as a function of the stress-intensity range. The mathematics is well established, but its application is fragile because it depends on inputs that are hard to know: the true load spectrum a structure will experience, the size and location of initial defects, the material’s behavior at the relevant stress ratio, and the effect of the actual environment on crack growth. A fatigue calculation can be numerically immaculate and still wrong because the load spectrum assumed in design did not match the loads the structure met in service.
The case maps cleanly onto the three instruments. An Engineering Model Credibility Index applied to a fatigue assessment will usually find formulation validity reasonable and data sufficiency weak, because the load spectrum and the initial-defect distribution are precisely the inputs that field reality tends to violate. A Constraint-Resolution Priority Matrix will rank inspectability and irreversibility highly, because a fatigue failure can be catastrophic and a structure that cannot be inspected offers no second chance to catch a growing crack. A Reliability and Uncertainty Exposure Score will flag detectability deficit as the dominant term, since the entire danger of fatigue is that it progresses silently. The instruments do not perform the fatigue calculation; they tell the organization that the calculation’s credibility rests on inspection and load characterization, and that a design which forecloses inspection has transferred a hidden risk to whoever operates the structure for the next forty years.
The professional lesson generalizes beyond fatigue to every slow-accumulation failure mode: corrosion, creep, wear, insulation breakdown, and software entropy alike. Slow failures are dangerous because they reward neglect for a long time before they punish it suddenly, and because the people who make the design assumptions are rarely the people who inherit the consequences. Engineering mathematics serves its purpose here by keeping the long-term failure mode visible in the present-tense decision, which is the only moment at which it can be cheaply addressed.
4.8 A Counter-Case: When the Mathematics Was Right and Disregarded
The cases examined so far concern mathematics that was flawed, over-trusted, or incomplete. A complete account must also treat the opposite failure, which is in some ways more troubling: the occasions on which the analysis was substantially correct, the warning was raised, and the organization proceeded anyway. These failures are not failures of engineering mathematics at all; they are failures of the organizational pathway that connects a correct result to a decision, and they reveal that a credible analysis is necessary but not sufficient for a sound outcome.
The pattern recurs across industries with painful regularity. An engineer or a small group produces an analysis showing that a planned action carries unacceptable risk. The analysis is technically sound but inconvenient, arriving against a deadline, a budget commitment, or a management expectation already set. The result is then discounted through a familiar sequence: the uncertainty in the analysis is emphasized to weaken its authority, the burden of proof is quietly inverted so that the analyst must prove danger rather than the proponent prove safety, and the decision proceeds on the grounds that the warning was not conclusive. When the predicted failure then occurs, the subsequent inquiry frequently discovers that the mathematics had been right all along and that the institution had been organizationally incapable of acting on it.
This counter-case sharpens the purpose of the three instruments. Their value is not only to expose weak analysis but to give strong analysis a defensible structure that is harder to discount. A Constraint-Resolution Priority Matrix that ranks a hazard high on safety criticality and irreversibility creates a recorded artifact that an organization must explicitly overrule rather than quietly set aside, and a Reliability and Uncertainty Exposure Score that flags a dominant exposure converts a lone engineer’s worry into a documented institutional finding. The instruments cannot compel a decision, and they should not; engineering judgment must remain answerable to human authority. What they can do is raise the cost of ignoring a sound warning by making the warning explicit, structured, and auditable, so that disregarding it becomes a recorded choice with an owner rather than an unexamined drift. In the failures that follow ignored warnings, it is almost always the absence of that recorded ownership, rather than the absence of the warning itself, that the inquiry finds most damning.
Chapter 5: Analysis and Discussion
5.1 Complex Technical Issues Are Constraint Systems
Complex technical issues should be read first as constraint systems. Teams often begin by searching for solutions, but a solution cannot be judged until the constraint structure is understood. Safety, physics, cost, schedule, materials, environment, human action, regulation, and operational continuity together define the feasible region. The work is not glamorous. It is the discipline of discovering what cannot be wished away, and it is usually the difference between a design that survives review and one that collapses when its hidden boundaries are finally exposed.
This view changes project behavior. Instead of treating constraints as late obstacles, mature teams bring them forward. A structural analyst asks about manufacturability early. A software engineer asks about sensor uncertainty. An operations manager asks whether the procedure can be executed under stress rather than on paper. A reliability engineer asks whether redundancy is defeated by a shared environment. A financial manager asks whether a mathematically optimal design creates a lifecycle cost the programme cannot sustain. The technical problem grows clearer because its boundaries stop hiding, and the cost of discovering a constraint falls when the discovery happens during design rather than during operation.
Constraint thinking also helps in executive communication. Leaders do not need every equation. They do need to understand which constraints are binding and which assumptions control the recommendation. When technical teams present only a final result, leaders may accept a decision without grasping the margins. A mature engineering organization presents the feasible set and the binding constraints, not just the chosen point, because the chosen point means little to a decision-maker who cannot see what surrounds it.
5.2 Model Credibility Is a Management Duty
Model credibility is often treated as a specialist concern, left to analysts or simulation engineers. The delegation is a mistake. Once a model influences investment, design release, safety assessment, or operations, its credibility becomes a management duty. Leaders must know what decision the model is being used for, what evidence supports it, where it has been validated, how uncertainty was carried, and what happens if the model is wrong. None of that requires the leader to derive the equations, but all of it requires the leader to ask the right questions and to refuse comfortable answers.
The duty does not turn executives into specialists in every method. It requires them to build review systems that prevent unsupported authority. Model review boards, assumption registers, validation plans, sensitivity summaries, independent checks, and post-decision learning all belong to technical governance. In smaller organizations the same discipline can be lighter without being absent. Someone must own the question that the Engineering Model Credibility Index makes unavoidable: why do we trust this model for this decision, and what would change our mind?
The index is useful precisely because it makes that question hard to evade. When formulation validity is weak, the model is fragile at its foundation. When validation evidence is thin, the model may be exploratory rather than decisive. When boundary conditions are poor, the result may be accurate only in a world the system will never inhabit. When uncertainty propagation is missing, the precision on the screen is counterfeit. The score itself matters less than the interrogation it forces, and an organization that runs the interrogation honestly will rarely be surprised by its own models.
5.3 Optimization Can Hide Risk
Optimization is productive when constraints are complete and damaging when they are not. A design that minimizes weight may become too hard to inspect. A schedule that minimizes time may strip out the slack that testing needs. A grid dispatch that minimizes cost may erode the stability margin. A manufacturing process that maximizes throughput may raise defect risk. Every optimization is a statement about what has been valued and what has been ignored, and the ignored terms are where the risk usually hides.
The danger grows when leaders admire optimality without examining the objective function. The word optimal can shut down conversation when it should open one. What exactly was optimized? Under what assumptions? Which constraints were binding? Which variables were excluded from the objective entirely? How sensitive is the answer to the inputs nobody measured carefully? What happens when demand, load, temperature, human response, or a material property drifts outside expectation? An optimum that cannot answer those questions is a liability wearing the costume of an achievement.
In complex engineering, robust solutions are frequently better than sharp optima. A slightly heavier design with better tolerance to uncertainty may outperform a lighter design balanced on a fragile assumption. A route that is not the shortest may be the safest. A control rule that sacrifices a little nominal efficiency may preserve stability under disturbance. Mathematics should not be used to chase perfection inside a narrow model when the real system rewards resilience, and a good engineering culture treats a brittle optimum as a warning rather than a trophy.
5.4 Human Expertise Still Matters
The strongest mathematical systems still depend on human expertise. Engineers choose the abstraction, define the variables, decide what to ignore, interpret anomalies, and judge whether a result makes physical sense. Automation can accelerate analysis, but it cannot absolve the team from understanding the system. A digital twin cannot know that a sensor was mounted poorly unless the data or the governance process reveals it. An optimizer cannot know that a supplier routinely misses a tolerance unless that knowledge enters the model. A simulation cannot know that a maintenance crew will bypass an awkward procedure unless human factors are taken seriously enough to be modeled.
Human expertise is not a romantic alternative to mathematics; it is the condition that makes mathematics useful. Experienced engineers notice scale problems, boundary-condition errors, unrealistic assumptions, and operational contradictions before they become failures. Junior engineers acquire that discipline through review, testing, mentoring, and exposure to real systems with real consequences. Organizations that treat mathematical software as a substitute for engineering judgment weaken themselves quietly, because the weakness only becomes visible when a model is asked to carry a decision that judgment would have questioned.
5.5 Data Quality and Measurement Discipline
Every mathematical model depends on measurement, whether the measurements are direct sensor readings, material tests, field data, laboratory experiments, or historical failure records. Poor data quality can corrupt excellent mathematics. Missing timestamps, miscalibrated sensors, inconsistent units, biased sampling, undocumented filtering, or unrepresentative test conditions can move error quietly into the model and from there into the decision, where it is far harder to detect.
Measurement discipline is therefore not support work; it is engineering mathematics in material form. Metrology, calibration, uncertainty statements, test procedures, data lineage, and sensor validation decide whether a model has reality beneath it. NIST’s emphasis on measurement and validation in advanced manufacturing points to the same deeper truth: the credibility of a calculation is bounded by the credibility of the measurement chain that feeds it, and no amount of computational sophistication can raise that bound.
Organizations should track measurement risk with the seriousness they reserve for schedule and cost. A project that lacks validation data should not present model results as settled. A sensor network that has not been calibrated should not feed safety-critical automation without safeguards. A field dataset gathered under mild operating conditions should not be used to validate performance under extremes. Data is not evidence until its origin and its limits are known, and a model fed by unexamined data inherits every flaw the data carries.
5.6 Engineering Mathematics and Ethical Responsibility
Engineering mathematics carries ethical weight because it can authorize action. A calculation can release a design, delay a recall, approve a flight path, justify a bridge load rating, size a medical device, or determine whether a grid can operate securely. When the mathematics is weak, the consequences are rarely confined to the analyst. The public inherits the risk, usually without ever knowing a calculation was involved.
Ethical practice requires more than honest intent. It requires technical habits that make deception and self-deception harder. Assumptions should be documented. Uncertainty should be stated rather than buried. Limits should be explicit. Disagreement should be recorded rather than smoothed over. Sensitivity should be tested. Independent review should be welcomed rather than resented. A team that hides uncertainty because the answer is inconvenient is not protecting the project; it is transferring risk to people who never consented to carry it, which is the precise definition of an engineering ethics failure.
The ethical dimension also protects engineers. Technical professionals often work under schedule, budget, and leadership pressure. A clear mathematical governance process gives them language for refusing unsafe shortcuts. It lets a young analyst say that the model has not been validated for that use. It lets a project engineer point out that the optimal solution violates a hidden constraint. It lets a chief engineer delay a release until the evidence is adequate. Ethics becomes operational the moment an organization gives technical truth a place to stand, and the instruments in this work are designed to be that place.
5.7 Boundaries of the Proposed Tools
Honesty about the instruments requires naming what they cannot do. They do not measure anything in physical units; they organize expert judgment, and they are only as good as the judgment and evidence behind each score. They can be gamed by a team determined to reach a predetermined answer, and a high composite score with thin justification should be read as a warning rather than a reassurance. They do not replace domain-specific analysis — a reliability calculation, a stability study, a verification campaign — but sit on top of it, summarizing whether that analysis has been done well enough to act on. Read with those limits in mind, the tools are a structured conscience for technical decision-making. Read without them, they risk becoming the very false precision the rest of this argument warns against.
5.8 Model Risk in Data-Driven and Machine-Learning Systems
Data-driven models deserve a separate caution because their failure modes differ from those of physics-based models, and because their fluency can be mistaken for understanding. A trained model interpolates well within the distribution of its training data and can fail without warning outside it, yet nothing in its confident output signals that it has left the region where it was validated. A physics-based model that is extrapolated at least carries equations a reviewer can inspect; a data-driven model extrapolated beyond its training distribution offers no such handhold, and its error can be both large and silent.
The governance response is not to ban such models but to bound them. A data-driven component used in a safety-relevant decision should be wrapped in checks that detect when the input has drifted away from the training distribution, paired with a physics-aware guard that can override an implausible output, and monitored in service for the degradation that comes as the world moves away from the data the model learned. The Perseverance navigation pattern — machine learning proposes, verified model disposes — is the right template, and the Reliability and Uncertainty Exposure Score captures the new risk through its uncertainty-factor and detectability-deficit terms. A model whose failures are hard to detect and whose behavior outside its training set is poorly characterized scores high on exposure regardless of how impressive its in-distribution accuracy appears.
5.9 Communicating Uncertainty to Decision-Makers
A technical result is only as useful as the decision it informs, and the translation from analysis to decision is where much engineering mathematics is wasted. Decision-makers rarely need the derivation; they need to know what the result means, how confident they should be, what would change the recommendation, and what happens if the analysis is wrong. An uncertainty buried in an appendix is an uncertainty that did not inform the decision, and a recommendation presented as a single number invites a confidence the analysis may not justify.
Good communication of uncertainty is concrete rather than hedged. It states the central estimate, the range that matters for the decision, the assumptions that drive that range, and the specific evidence that would tighten it. It distinguishes between uncertainty that more analysis can reduce and uncertainty that is irreducible given the available data, because the two call for different responses — one for an investment in measurement, the other for a margin or a hedge. The sensitivity summaries recommended in Chapter 6 are the mechanism for this, and an organization that insists on them turns uncertainty from a source of either false comfort or paralysis into an ordinary input that leadership can weigh against cost and schedule like any other.
5.10 Relationship to Established Credibility Standards
Several established standards already address pieces of the problem this paper treats, and an honest account must say where the proposed instruments overlap with them and where they add something. Standards for the verification and validation of computational models specify, in considerable technical depth, how to establish that a model solves its equations correctly and represents the relevant physics adequately. Standards for model credibility assessment in high-consequence settings define maturity scales across dimensions such as verification, validation, and input pedigree. Risk-management standards prescribe how organizations should identify, analyze, and treat risk in general terms. Each of these is deeper in its own domain than the present framework attempts to be.
What the three instruments add is integration at the point of decision and accessibility to a general engineering team. The detailed standards are authoritative but heavy, owned by specialists, and applied to the model rather than to the decision the model serves; a team facing a Friday-afternoon release decision rarely has the time or the standing to invoke them in full. The credibility index borrows the verification-and-validation distinction and the input-pedigree concern from those standards and compresses them into a form a non-specialist can apply in an hour, while the priority matrix and the exposure score connect the resulting credibility judgment to consequence and to failure exposure. The relationship is therefore complementary: where a formal verification-and-validation programme exists, its results feed directly into the credibility index’s technical terms, and where one does not yet exist, the index reveals its absence as a low score rather than letting it pass unnoticed.
5.11 Threats to the Validity of the Proposed Instruments
Intellectual honesty requires naming the ways the instruments themselves can fail, because a framework that audits other people’s models must be willing to audit its own. The first threat is gaming: any scored instrument tied to a decision creates an incentive to produce the score the decision wants, and weights or rubrics can be quietly adjusted until the desired number emerges. The countermeasure is governance — separating the assessor from the advocate, recording the rationale for scores, and reviewing scores against outcomes — but no instrument can fully defend itself against an organization determined to misuse it, and pretending otherwise would be its own form of overconfidence.
The second threat is false comfort. A completed credibility index produces a tidy number, and a tidy number invites the very over-trust the paper warns against, now attached to the audit rather than to the model. The defense is to treat the score as a summary of an argument rather than a verdict, and to insist that the underlying term-by-term evidence travel with it, so that a reader can see why the number is what it is and where it is weak. The third threat is scope drift, in which instruments designed for high-consequence decisions are applied indiscriminately to trivial ones, generating bureaucratic overhead that discredits the whole approach; the implementation guidance addresses this by reserving the instruments for decisions whose stakes justify the effort. Naming these threats does not neutralize them, but it places them where a careful reader can watch for them, which is the most any framework of structured judgment can honestly offer.
5.12 Reproducibility and the Documentation Burden
A result that cannot be reproduced is a result that cannot be trusted, and reproducibility in engineering mathematics depends on documentation that is too often treated as an afterthought completed, if at all, once the interesting work is done. A computation is reproducible when another competent engineer, given the recorded inputs, assumptions, software versions, and procedures, can regenerate the result and arrive at the same answer within a stated tolerance. That standard is demanding in practice because so much of what determines a result lives in undocumented choices: a solver setting left at its default, a boundary condition adjusted late and never recorded, a data file cleaned by hand, a parameter tuned until the output looked right. Each such choice is invisible in the final number and decisive for it.
The credibility instruments depend on this documentation and also motivate it. The traceability term in the Engineering Model Credibility Index scores precisely whether the path from inputs and assumptions to outputs is recorded well enough that another engineer could follow it, and a model that cannot be reproduced cannot score well on that term no matter how sophisticated its mathematics. The discipline required is modest in any single instance — record the version, freeze the inputs, note the assumptions as they are made rather than reconstructing them later — but it is cumulatively demanding because it must be sustained when no one is asking for it. The payoff arrives at the worst moments: when a result is challenged after a failure, when a model must be revived years after its authors have left, or when a regulator asks how a number was produced. An organization that documents only when forced will find, at exactly those moments, that the record it needs was never made, and that an analysis it once trusted has become impossible to defend.
Chapter 6: Recommendations and Professional Standards
6.1 Build a Model Credibility Register
Organizations that rely on engineering models should maintain a model credibility register. The register should identify each significant model along with its owner, version, purpose, domain of validity, input sources, verification status, validation evidence, uncertainty treatment, decision scope, and retirement trigger. The practice need not become an expensive bureaucracy. Its purpose is to prevent the common failure in which a model built for one use quietly migrates into another with no review and no record of how its authority was acquired.
The register should be risk-tiered. Low-consequence design exploration can tolerate lighter documentation. Safety-critical, certification, public-infrastructure, and mission-critical models require deeper evidence. The decision scope should be explicit: a model may be approved for screening concepts but not for final design release, or approved for nominal operations but not for extreme events. Credibility is bounded, and the register keeps those bounds visible so that no one can borrow authority the evidence does not support.
6.2 Require Sensitivity Before Authority
No complex technical recommendation should gain authority without sensitivity analysis. Teams should identify which parameters drive the outcome, which assumptions are uncertain, and which changes would reverse the recommendation. The practice belongs in design reviews, safety boards, and investment decisions involving engineered systems. A result that stays stable under plausible perturbation deserves more confidence. A result that changes direction under small uncertainty should be treated as provisional regardless of how precise its central value appears.
Sensitivity summaries should be written in engineering language, not buried in a technical appendix that decision-makers never open. Leaders should see which variables matter and why. When a recommendation depends heavily on a material property that has not yet been tested, that dependence should be visible. When performance depends on an operator responding within an unrealistic time window, that should be visible. When a grid stability margin depends on particular weather and demand assumptions, that should be visible too. Sensitivity analysis is not a mathematical ornament; it is a decision safeguard, and treating it as optional is how fragile recommendations acquire undeserved authority.
6.3 Separate Exploratory, Operational, and Safety Models
A common organizational error is to treat all models as though they share the same authority. Exploratory models help teams learn. Operational models support routine decisions. Safety-critical models influence decisions where failure can cause severe consequences. The categories should not be blurred. A quick spreadsheet used to test an idea should not become a release calculation. A machine-learning forecast used for planning should not quietly become a control input. A simulation used for conceptual comparison should not be cited later as validation evidence it was never built to provide.
Classification protects both innovation and safety. Exploratory models can stay fast and flexible because they are not burdened with certification demands. Safety-critical models receive the scrutiny they deserve. Operational models are monitored for drift and degraded performance. The organization becomes more agile, not less, because it knows which evidence standard belongs to which decision and stops applying heavy process to light decisions or light process to heavy ones.
6.4 Integrate Mathematicians, Engineers, Operators, and Maintainers
Complex technical issues require several forms of knowledge that rarely live in one person. Mathematicians and analysts understand the model structure. Design engineers understand the architecture. Operators understand field behavior. Maintainers know where systems age, jam, leak, loosen, drift, or confuse their users. Safety engineers understand consequences. Project leaders understand constraints and trade-offs. A model built without these perspectives may be technically impressive and operationally naïve at the same time, and the gap between the two is where incidents are born.
Review meetings should be designed to expose mismatch rather than to perform consensus. Operators should be allowed to challenge assumptions without penalty. Maintainers should be asked whether an optimized design can actually be inspected and repaired. Analysts should explain uncertainty in plain technical terms rather than hiding behind notation. Managers should state which decision they expect the model to support. Cross-disciplinary review is not inefficiency; it is how complex systems defend themselves against the narrow expertise that any single discipline brings.
6.5 Use Public Case Learning Without Mythology
Organizations should use cases such as Apollo 13, Perseverance, grid operability, and computational verification as learning material while avoiding the mythology that grows around them. Apollo 13 was not saved by inspirational culture alone; it was saved by technical preparation, disciplined procedures, mathematics, deep mission knowledge, and calm execution under pressure. Perseverance navigation is not magic autonomy; it is a chain of estimation, mapping, hazard logic, and verification. Grid stability is not a political slogan; it is dynamic-systems engineering under changing physics. Verification and validation are not paperwork; they are the credibility system behind computational decisions. Mythology flatters; engineering learns.
6.6 Reform Professional Education
Engineering education should treat applied mathematics as a professional reasoning discipline rather than a sequence of solved problems. Students should still learn calculus, differential equations, linear algebra, probability, optimization, statistics, numerical methods, and control theory. They should also learn when those tools fail, how uncertainty enters a problem, how an assumption becomes dangerous, how validation evidence is actually built, and how a technical recommendation is communicated to people who will never see the equations. Mathematics taught without failure literacy is incomplete preparation for a profession whose errors are paid for by the public.
6.7 Adopt the Instruments as Living Practice
The three instruments in this work should be adopted as living practice rather than as one-time checklists. An Engineering Model Credibility Index recorded at design release and revisited when the operating environment changes will catch the silent migration of authority that the credibility register is meant to prevent. A Constraint-Resolution Priority Matrix rehearsed in calm conditions builds the muscle that a crisis later demands. A Reliability and Uncertainty Exposure Score tracked over a system’s life reveals exposure that creeps in through aging, modification, and changing use. The weights should be recalibrated by each organization for its own domain, and the justifications behind each score should be retained so that the instruments leave an audit trail an investigator could follow. Used this way, the tools become part of how an organization thinks, not a form it fills in to satisfy a reviewer.
6.8 An Implementation Roadmap
Adopting these practices in an organization that does not yet have them is itself a project with constraints, and treating the adoption as a flip of a switch is a reliable way to ensure it fails. A workable sequence begins by establishing the model credibility register for the handful of models that already carry the highest-consequence decisions, rather than attempting to catalogue every spreadsheet at once. With those models documented, the credibility index can be applied at the next natural decision point for each, which surfaces the weakest evidence without disrupting work that is already in flight. The constraint-priority matrix and the exposure score follow naturally once teams have seen the credibility index pay for itself, because by then the value of structuring judgment is no longer an abstract claim.
The cultural conditions matter as much as the procedural ones. The instruments only work where a low score can be reported without career penalty, where a maintainer can challenge an analyst without being dismissed, and where leadership treats a delayed release backed by honest evidence as a success rather than a failure of nerve. An organization that punishes the messenger will quickly find its scores drifting upward toward whatever the decision already wanted, at which point the instruments have become decoration. The roadmap therefore ends where it began: the tools are a structured conscience, and a conscience requires an organization that wants to hear it.
6.9 Competence, Training, and the Human Prerequisite
The instruments presume a level of engineering competence that cannot be assumed into existence, and any honest implementation plan must address the human prerequisite directly. A credibility index scored by someone who does not understand the difference between verification and validation will produce numbers, but the numbers will be noise dressed as signal. The framework does not lower the competence required to do credible engineering; it organizes and makes visible the judgment of people who already have it, and it is actively dangerous in the hands of people who do not, because it can lend an unearned appearance of rigor to an uninformed assessment.
This implies that adoption must be paired with development of the underlying judgment, through the kinds of measures that build engineering maturity in any organization: mentoring that pairs less experienced engineers with those who have seen failures firsthand, structured review of past decisions including the ones that went wrong, and a deliberate practice of articulating the assumptions behind a model rather than absorbing them tacitly. The scoring rubrics can themselves serve as teaching instruments, because a junior engineer who must justify a verification-evidence score learns what verification evidence actually consists of. The framework is in this sense a scaffold for developing judgment as well as a means of recording it, and an organization that treats it purely as a compliance exercise will get compliance rather than competence.
6.10 The Cost of Credibility and How to Justify It
Every practice recommended here costs time, and an argument that ignored cost would be exactly the kind of one-sided analysis the paper criticizes. Convergence studies consume computer time and engineer attention. Uncertainty propagation is more expensive than pushing a mean through a model. Maintaining a credibility register and scoring models against it is overhead that produces no product directly. A team under schedule pressure will reasonably ask what all of this buys, and the answer must be honest about the fact that, on any individual decision, the disciplined approach will often confirm what the quick approach already suggested, at greater cost.
The justification is not found in the average case but in the tail. The cost of credibility is paid steadily and visibly; the cost of its absence is paid rarely but catastrophically, in the failures that destroy hardware, careers, and lives, and that on inquiry are traced to an over-trusted model or an ignored warning. The economics are those of insurance, and they are easy to resent precisely because, when the discipline works, nothing happens and the premium looks wasted. An organization that understands this will scale the rigor to the consequence — spending little on reversible, low-stakes decisions and a great deal on irreversible, high-stakes ones — which is exactly the proportioning the Constraint-Resolution Priority Matrix is designed to make explicit. Credibility is not free, and the framework’s purpose is not to maximize it everywhere but to invest it where the consequences justify the premium and to withhold it where they do not.
Chapter 7: Conclusion
Engineering mathematics solves complex technical issues when it stays loyal to physical consequence. Its value is not the appearance of precision, the complexity of the software, or the elegance of the equations. Its value lies in clarifying the feasible set, naming uncertainty, testing margins, exposing fragile assumptions, and guiding action when intuition cannot hold the full system in view. The public case evidence assembled here shows the discipline working across radically different settings — spacecraft crisis response, planetary navigation, electricity-system stability, and computational model credibility — with the same underlying logic in each.
The central professional lesson is that mathematical analysis must earn its decision authority rather than inherit it. A model should not be trusted because it is advanced; it should be trusted because its formulation, evidence, boundaries, uncertainty treatment, and governance match the decision being made. An optimized answer should not be accepted because it is optimal; it should be accepted only after the team understands what was optimized, what was constrained, and what was left outside the objective function. A reliability claim should not stand because the probability is small; it should stand only after failure modes, common causes, detectability, human response, and operating environment have been examined honestly.
Complex systems are becoming more coupled, more digital, more automated, and more dependent on models. That trend raises both the value of engineering mathematics and the danger of misusing it. The answer is not less mathematics; it is more disciplined mathematics — better verification, better validation, better uncertainty communication, better sensitivity analysis, better model governance, and better integration of human expertise. Technical organizations that build those habits will make stronger decisions under pressure. Those that confuse computation with credibility will stay vulnerable even when their dashboards look modern and their slide decks look certain.
7.1 Limitations of the Present Work
The framework advanced here carries limitations that bound its claims and that further work would need to address. It has been developed and illustrated through reasoned analysis and through documented engineering cases drawn from the public record, rather than validated through controlled deployment across many organizations; the evidence that the instruments improve decisions is therefore argumentative and illustrative rather than empirical. The scoring rubrics, while anchored to observable evidence, have not been subjected to a formal inter-rater reliability study of the kind a mature instrument eventually requires, and the default weights, though constructed to be defensible, have not been calibrated against a large body of outcomes. These are limitations of maturity rather than of principle, but they are real, and a reader should weigh the framework as a structured proposal supported by reasoning and precedent rather than as an empirically established result.
A further limitation concerns generality. The instruments were shaped by problems in which physical consequence and model credibility are the dominant concerns — aerospace, civil, mechanical, and energy systems among them. Their transfer to domains with different risk structures, such as financial modeling, epidemiological forecasting, or large-scale software, is plausible and partly argued here, but it is not demonstrated, and each such domain carries failure modes the present treatment may underweight. The framework should be read as offering a transferable structure of thought rather than a finished instrument ready for any field, and its adoption in a new domain should begin with the recalibration the methodology itself prescribes.
7.2 Directions for Future Work
Several lines of work would strengthen the framework materially. The most important is empirical validation: applying the instruments prospectively across a portfolio of real decisions and tracking, over time, whether decisions made with them produce better-calibrated outcomes than decisions made without them. Such a study would also yield the data needed to calibrate the weights against outcomes rather than against reasoning, and to establish the inter-rater reliability of the scoring rubrics under realistic conditions. A second line of work would develop domain-specific instantiations, in which the general structure is specialized to the failure modes and regulatory context of a particular field, with weights and rubrics tuned accordingly and tested against that field’s own history of success and failure.
A third direction concerns integration with the tools engineers already use. The instruments will be adopted in proportion to how little friction they add, and embedding the credibility register in existing model-management and configuration-control systems, rather than maintaining it as a separate document, would lower that friction substantially. A fourth direction concerns the data-driven systems treated in Chapter 5, whose distinctive failure modes — silent extrapolation, distributional drift, and opacity — deserve instruments of their own that extend the exposure score with terms specific to learned models. Each of these directions shares a premise with the paper as a whole: that the goal is not a more elaborate theory of credibility but a more reliable practice of it, and that the measure of success is whether engineers in the room where decisions are made reach for these instruments and are better for having done so.
Taken together, these directions describe a research programme rather than a finished result, and that framing is deliberate. The instruments offered here are meant to be used, criticized, and revised in contact with real decisions, and the most valuable contribution this work can make is not to settle the question of model credibility but to give a working community a shared and improvable structure for arguing about it. A framework that is adopted, tested against experience, and amended where it fails will, over time, become something more trustworthy than any single author could specify in advance — which is, in the end, the same standard of accumulated and audited evidence that the paper asks engineers to apply to their models.
The final judgment is practical. Engineering mathematics is one of the strongest safeguards available to a technical organization, but only when it is handled as evidence rather than decoration. It should make decisions harder to fake, assumptions harder to hide, and risks harder to transfer silently to operators, users, and the public. The three instruments offered here — a credibility index, a constraint-priority matrix, and an exposure score — are small contributions to that larger obligation, and they succeed only to the extent that they make honesty easier and false confidence more expensive. That is the professional obligation of the discipline, and meeting it is the work.
References
American Institute of Aeronautics and Astronautics. (1998). Guide for the verification and validation of computational fluid dynamics simulations (AIAA G-077-1998). AIAA.
American Society of Mechanical Engineers. (2006). Guide for verification and validation in computational solid mechanics (ASME V&V 10-2006). ASME.
American Society of Mechanical Engineers. (2009). Standard for verification and validation in computational fluid dynamics and heat transfer (ASME V&V 20-2009). ASME.
American Society of Mechanical Engineers. (2024). VVUQ standards: Verification and validation resource hub. ASME. https://www.asme.org/codes-standards/vvuq-standards
Daftry, S., Abcouwer, N., Del Sesto, T., Venkatraman, S., Igel, L., Byon, A., Rosolia, U., Yue, Y., & Ono, M. (2022). MLNav: Learning to safely navigate on Martian terrains. arXiv. https://arxiv.org/abs/2203.04563
Kalman, R. E. (1960). A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 82(1), 35–45. https://doi.org/10.1115/1.3662552
National Aeronautics and Space Administration. (2016). NASA systems engineering handbook (NASA/SP-2016-6105 Rev2). NASA. https://www.nasa.gov/wp-content/uploads/2018/09/nasa_systems_engineering_handbook_0.pdf
National Aeronautics and Space Administration. (2020). Apollo 13: The successful failure. NASA. https://www.nasa.gov/missions/apollo/apollo-13-the-successful-failure/
National Aeronautics and Space Administration. (2021). Terrain-relative navigation: Landing between the hazards. NASA. https://science.nasa.gov/science-research/science-enabling-technology/technology-highlights/terrain-relative-navigation-landing-between-the-hazards/
National Grid Electricity System Operator. (2025a). System Operability Framework. National Energy System Operator. https://www.neso.energy/publications/system-operability-framework-sof
National Grid Electricity System Operator. (2025b). What is inertia? National Energy System Operator. https://www.neso.energy/energy-101/electricity-explained/how-do-we-balance-grid/what-inertia
National Institute of Standards and Technology. (2024). Metrology for additive manufacturing model validation. NIST. https://www.nist.gov/programs-projects/metrology-am-model-validation
Oberkampf, W. L., & Roy, C. J. (2010). Verification and validation in scientific computing. Cambridge University Press. https://doi.org/10.1017/CBO9780511760396
Rasmussen, J. (1997). Risk management in a dynamic society: A modelling problem. Safety Science, 27(2–3), 183–213. https://doi.org/10.1016/S0925-7535(97)00052-0
Raunak, M. S., & Kuhn, D. R. (2021). Metamorphic testing on the continuum of verification and validation of simulation models. National Institute of Standards and Technology.
Reason, J. (1997). Managing the risks of organizational accidents. Ashgate.
Roache, P. J. (1998). Verification and validation in computational science and engineering. Hermosa Publishers.
Roy, C. J. (2005). Review of code and solution verification procedures for computational simulation. Journal of Computational Physics, 205(1), 131–156. https://doi.org/10.1016/j.jcp.2004.10.036
Yeo, D. H. (2020). A summary of industrial verification, validation, and uncertainty quantification procedures in computational fluid dynamics (NIST Technical Note). National Institute of Standards and Technology.