

Mayo Clinic Case Study
Research Publication by Nancy Onyinye Ugwu
Institutional Affiliation: New York Center for Advanced Research (NYCAR)
Publication No.: NYCAR-TTR-2026-RP007
Date: June 2026
DOI: https://doi.org/10.5281/zenodo.20357324
Peer Review Status:
This research paper was reviewed and approved under the internal editorial peer review framework of the New York Center for Advanced Research (NYCAR) and The Thinkers’ Review. The process was handled independently by designated Editorial Board members in accordance with NYCAR’s Research Ethics Policy.
Copyright © June 2026 Nancy Onyinye Ugwu. All rights reserved.
Mayo Clinic, Clinical Transformation, and the Governance of AI-Enabled Medicine
Abstract
Artificial intelligence is becoming part of the practical language of hospital reform, yet its clinical value remains conditional. A hospital can acquire predictive tools, decision-support software, remote-monitoring systems, imaging algorithms, and trial-matching platforms without changing the experience of care in a meaningful way. Transformation occurs only when computational intelligence enters the real conditions of clinical work: the timing of diagnosis, the quality of professional judgment, the burden placed on clinicians, the safety of patient pathways, the protection of sensitive data, and the trust that patients place in the institution. This research paper examines Mayo Clinic as a case study in AI-enabled clinical transformation, using the institution’s public AI priorities and cardiovascular AI work as the case anchor. The study argues that AI in hospitals should be understood as accountable intelligence rather than machine medicine. Its best use is not to replace clinical responsibility, but to strengthen the human capacity to notice risk earlier, interpret complex evidence, personalize treatment, connect patients to research opportunities, and monitor care beyond the traditional clinic encounter.
The analysis draws on healthcare AI scholarship, reporting guidance for clinical AI evaluation, international ethics and regulatory sources, and Mayo Clinic’s public materials on artificial intelligence and cardiovascular medicine. It develops a qualitative case-study argument supported by seven author-developed visual models that describe clinical use cases, transformation priorities, readiness dimensions, sources of value, implementation risks, potential clinical gains, and multidimensional readiness. These figures are illustrative decision aids, not official Mayo Clinic performance measures. The central conclusion is that hospital AI succeeds when data capability, workflow design, clinician trust, governance, patient-safety monitoring, and equity review mature together. Sophisticated algorithms cannot compensate for weak implementation, poor explanation, inadequate oversight, or professional distrust. A responsible hospital does not ask clinicians to defer to technology; it gives them better instruments, clearer evidence, safer systems, and stronger institutional support. Mayo Clinic’s case therefore points to a demanding standard for AI-enabled medicine: clinical intelligence must remain answerable to human judgment, patient dignity, and continuous safety discipline.
Keywords: artificial intelligence, hospital transformation, Mayo Clinic, clinical governance, patient safety, clinical decision support, cardiovascular AI, digital health, physician judgment, accountable intelligence
Contents
Chapter 1: Introduction: Accountable Intelligence as Hospital Strategy
Chapter 2: Literature Review: Clinical Augmentation, Governance, and Safety
Chapter 3: Methodology: Case Logic, Readiness Modeling, and Source Discipline
Chapter 4: Case Analysis: Mayo Clinic and AI-Enabled Clinical Transformation
Chapter 5: Discussion: Governance, Trust, and the Conditions for Responsible Transformation
Chapter 6: Recommendations and Conclusion: Building Trustworthy AI-Enabled Hospitals
Chapter 7: Implementation Blueprint: From AI Adoption to Accountable Clinical Practice
Chapter 8: Limitations, Future Research, and Final Research Position
List of Figures
Figure 1. Mayo Clinic AI-Enabled Clinical Use Cases.
Figure 2. AI Transformation Priorities in a Hospital Setting.
Figure 3. Transformation Readiness Dimensions.
Figure 4. Sources of Clinical Value from Hospital AI.
Figure 5. Implementation Risks That Can Undermine Hospital AI.
Figure 6. Potential Clinical Gains from AI-Supported Care.
Figure 7. Mayo Clinic AI Readiness Profile.
Chapter 1: Introduction: Accountable Intelligence as Hospital Strategy
1.1 The hospital problem behind the AI question
Hospitals are not ordinary digital organizations. They carry a kind of risk that most technology settings do not face. A flawed recommendation, a delayed alert, an unclear interface, or a poorly governed prediction can reach a patient through the hands of a professional who is already working under pressure. The promise of AI therefore needs a more severe test than technical elegance. It must be judged by whether it improves the conditions under which care is actually delivered. A hospital does not transform because it owns an algorithm. It transforms when clinical teams can use new intelligence to make safer, earlier, more precise, and more compassionate decisions.
The public conversation around AI in healthcare often moves too quickly from possibility to celebration. Machines can classify images, identify patterns in electronic health records, match patients to trials, and estimate risk across large data sets. Those abilities matter, and the strongest systems already show potential in imaging, cardiology, oncology, remote monitoring, and operational support. Yet the central hospital question remains practical. What changes at the bedside, in the clinic room, in the multidisciplinary meeting, in the emergency department, or in the conversation where a patient asks what a prediction means for their life? If that question is avoided, AI becomes a form of institutional theater.
Mayo Clinic is a useful case because its public AI priorities are connected to clinical work rather than detached digital branding. The institution describes AI in relation to clinical trial matching, remote health monitoring, imaging technologies, earlier recognition of disease risk, and cardiovascular medicine (Mayo Clinic, n.d.; Mayo Clinic, 2025). That framing allows this research paper to study AI as a clinical capability, not as an abstract computing project. The point is not to claim that one institution has solved the governance of medical AI. The point is to ask what hospital transformation requires when a leading medical center places AI inside diagnosis, prediction, monitoring, research access, and individualized care.
The title of this research paper uses the phrase accountable intelligence deliberately. Hospital AI is intelligence only if it helps clinicians reason more carefully and institutions act more responsibly. It is accountable only if its use can be explained, monitored, corrected, and governed. A prediction that cannot be questioned is unsafe. A model that performs well in aggregate but poorly for a subgroup is incomplete. A tool that adds burden to the clinician while advertising efficiency to the executive suite has misunderstood clinical work. A technology that turns a patient into a score without explanation has injured the meaning of care.
1.2 Why Mayo Clinic is a strong case
Mayo Clinic brings together several features that make its AI activity analytically useful: a major academic medical environment, a visible commitment to research and innovation, deep specialist practice, a public reputation for complex diagnosis, and an institutional interest in individualizing care. These features create a high-information case. They do not make the case universally transferable, but they allow the paper to examine what AI integration looks like when the setting already possesses clinical depth, data resources, research infrastructure, and a culture of specialty expertise.
The case also carries a warning. A strong institution can still encounter the familiar risks of hospital AI: model drift, automation bias, privacy concern, uneven performance across patient groups, workflow disruption, and professional distrust. Reputation does not validate a model. Prestige does not remove the need for lifecycle monitoring. A clinical tool that touches diagnosis, treatment, triage, or patient access needs evidence in the setting where it will operate. The Mayo Clinic case is valuable precisely because it permits a mature argument: advanced capacity creates opportunity, but it also increases the obligation to govern well.
Mayo Clinic’s public AI material describes a future in which AI helps select and match patients with clinical trials, supports remote health monitoring, uses imaging technology to detect conditions that may not be visible to ordinary review, and anticipates disease risk years before the disease becomes obvious (Mayo Clinic, n.d.). Its cardiovascular AI program is publicly framed around early risk prediction and diagnosis of serious or complex heart problems (Mayo Clinic, 2025). These examples are clinically rich. They allow the paper to examine AI where the stakes are concrete: a person’s heart disease risk, a patient’s access to a trial, a subtle imaging signal, a remote monitoring alert, a treatment decision that needs better evidence.
1.3 Research purpose and questions
This research paper examines how AI-enabled hospital transformation becomes clinically meaningful when predictive capability is joined to workflow design, professional trust, governance, patient-safety oversight, and equity review. The paper treats Mayo Clinic as a case anchor and reads the case alongside the broader literature on machine learning in medicine, AI reporting standards, ethical governance, medical-device oversight, and clinical implementation. It does not claim access to proprietary Mayo Clinic data, internal performance dashboards, confidential committee work, or patient-level outcomes. The analysis is based on public material, verified scholarly sources, and author-developed diagnostic models.
The inquiry is organized around a practical problem: how can hospitals convert algorithmic capability into trustworthy clinical practice? Several subsidiary questions follow from that problem. What forms of clinical value can AI plausibly support in hospitals? Which institutional conditions separate useful transformation from symbolic adoption? How does a major health system’s AI activity illustrate the connection between prediction, workflow, safety, and trust? What governance disciplines are needed when AI influences diagnosis, risk estimation, patient monitoring, or access to research?
The contribution is applied rather than speculative. The paper does not ask whether AI is generally good or bad for healthcare. That argument is too blunt for hospital realities. It asks where AI helps, when it creates risk, how clinicians should remain in command of interpretation, and what a responsible institution needs before scaling a system. The research therefore belongs to hospital management, digital health governance, clinical quality improvement, and patient-safety scholarship.
1.4 Structure of the research paper
Chapter 1 introduces the research problem and case logic. Chapter 2 reviews scholarship on clinical augmentation, machine learning in medicine, reporting standards, ethics, regulation, workflow, bias, and lifecycle monitoring. Chapter 3 explains the qualitative case-study method and the interpretive readiness model used in the paper. Chapter 4 analyzes Mayo Clinic’s AI-enabled clinical transformation with attention to imaging, cardiovascular medicine, trial matching, remote monitoring, individualized care, professional judgment, and governance. Chapter 5 discusses the managerial and ethical implications for hospitals. Chapter 6 presents recommendations for publication-level practice and closes with the central conclusion.
Seven colorful charts support the analysis. They are not official Mayo Clinic measures. They are author-developed illustrations designed to make the argument visible for academic, executive, and teaching use. Each figure is watermarked and copyrighted in the author’s name, with June 2026 marked for publication control. The charts help readers see the paper’s core claim: AI transformation is a system problem. It concerns clinical use cases, implementation priorities, readiness, sources of value, risk pressures, potential gains, and the balance among multiple institutional dimensions.
Chapter 2: Literature Review: Clinical Augmentation, Governance, and Safety
2.1 Clinical augmentation rather than professional replacement
The strongest healthcare AI literature does not present the future of medicine as a contest between doctors and machines. Topol (2019) describes high-performance medicine as a convergence of human and artificial intelligence, where computational systems help professionals interpret complexity while allowing greater attention to the human dimensions of care. That framing matters because hospital adoption becomes dangerous when it is sold as a shortcut around professional judgment. Medicine is not a mechanical selection of outputs. It involves uncertainty, competing harms, prognosis, preference, dignity, family context, and the ethical weight of responsibility.
Rajkomar, Dean, and Kohane (2019) argue that machine learning offers medicine a way to process large and complex data in ways that traditional systems have struggled to do. Electronic health records, imaging, laboratory data, physiologic monitoring, genomic information, prescriptions, free-text notes, and clinical history create volumes of information that exceed unaided human cognition. The point is not that clinicians become obsolete. The point is that modern clinical information systems need better methods for turning data into usable knowledge. Machine learning can help, but only when its outputs enter clinical judgment safely.
The difference between augmentation and replacement shapes every part of this paper. An augmented clinician receives better information and remains responsible for interpretation. A replaced clinician becomes a passive relay for a tool they may not understand. The former can strengthen medicine; the latter undermines professional ethics and patient trust. In hospital settings, the burden of proof therefore rests on the institution. It must show that AI supports clinical reasoning without making clinicians dependent on opaque authority.
2.2 The translation gap between model performance and clinical effect
Healthcare AI has produced impressive research results, especially in image-rich fields such as radiology, dermatology, pathology, ophthalmology, and cardiology. Yet good technical performance in a retrospective data set does not guarantee that a system will improve care in routine practice. Kelly et al. (2019) warn that healthcare AI faces major challenges in moving from promising models to clinical impact. The gap is rarely caused by one factor. It can involve weak validation, poor workflow fit, inadequate regulation, narrow outcome measures, clinician distrust, incomplete data, and failure to monitor systems after deployment.
Hospitals need to distinguish model performance from clinical usefulness. Sensitivity, specificity, area under the curve, calibration, and error rates matter. They do not answer the whole question. A model may be accurate but arrive too late for a decision. It may improve prediction but increase alert fatigue. It may identify risk but create no actionable pathway. It may perform well for the average patient while failing a subgroup. It may be technically impressive but clinically irrelevant because professionals ignore it. The translation gap is the space between what the system can calculate and what the hospital can responsibly use.
Reporting standards have developed in response to these problems. CONSORT-AI extends clinical trial reporting for AI interventions by asking researchers to describe the AI system, human-AI interaction, input data, intended use, and handling of errors (Liu et al., 2020). DECIDE-AI offers guidance for early-stage clinical evaluation of AI-driven decision-support systems and emphasizes real-world context, user interaction, and implementation setting (Vasey et al., 2022). These frameworks are important because they shift attention from algorithmic novelty to clinical accountability. A hospital tool does not deserve trust because it is advanced; it earns trust through transparent evaluation and disciplined use.
2.3 Ethics, governance, and the patient’s right to explanation
WHO’s 2021 guidance on ethics and governance of AI for health places autonomy, safety, transparency, responsibility, inclusiveness, and public benefit at the center of health AI governance (World Health Organization, 2021). These principles are not philosophical decorations. They translate into concrete hospital duties: protect patient data, clarify responsibility, test for bias, monitor performance, inform patients when AI meaningfully affects care, and ensure that technological decisions do not undermine human rights or clinical trust.
Patients may experience hospital AI very differently from executives, clinicians, or data scientists. A predictive system that feels efficient to administrators may feel strange or threatening to patients if the role of the technology is never explained. A risk score may carry emotional weight. A trial-matching recommendation may raise hopes. A remote-monitoring alert may alter how a patient sees their own body. Hospitals therefore need language that ordinary patients can understand. Explaining AI is not a courtesy added after deployment. It is part of responsible care.
The patient’s right to explanation does not require every mathematical detail of a model to be translated into lay language. It does require honesty about the role the tool plays. Patients deserve to know when AI meaningfully supports diagnosis, prediction, monitoring, or treatment planning; which professional remains accountable; how the information will be used; and whether alternatives or uncertainties exist. A hospital that cannot explain its use of AI in humane terms has not completed the work of implementation.
2.4 Bias, equity, and data inheritance
AI systems learn from the data they receive, and health data carry the history of unequal access. Some patients have detailed records because they have long been inside advanced care systems. Others appear in fragmented form because their care has been delayed, intermittent, underinsured, geographically dispersed, or poorly documented. If an algorithm learns from those patterns without correction, it may reproduce the very inequities that medicine should overcome. Average performance can conceal unequal harm.
Bias in healthcare AI is rarely a single event. It can enter through data selection, missingness, label definition, documentation habits, device differences, clinical practice variation, and outcome measurement. A model trained on one population may perform differently in another. A prediction built on healthcare use may confuse access with need. A system that uses historical treatment decisions may absorb prior disparities in referral, diagnosis, or intensity of care. Hospitals need equity review before and after deployment, not just a generic statement of fairness.
Mayo Clinic’s case is significant because a major institution has the capacity to pursue subgroup analysis, quality oversight, and post-deployment review. Yet the standard applies to every health system. Responsible AI needs evidence across race, ethnicity, sex, age, disability, geography, insurance status, language, and clinical complexity where those variables are relevant and ethically handled. If an institution lacks enough evidence to know how a model performs for vulnerable groups, the uncertainty itself must be treated as a safety concern.
2.5 Regulation and lifecycle monitoring
The regulatory environment for medical AI continues to develop. The FDA maintains a public list of AI-enabled medical devices authorized for marketing in the United States, describing the list as a transparency resource for identifying devices that incorporate AI technologies (U.S. Food and Drug Administration, 2026). The FDA has also described lifecycle considerations for AI-enabled device software functions, reflecting a central problem in the field: an AI system may change, drift, or behave differently as clinical conditions and data environments change (U.S. Food and Drug Administration, 2025).
The International Medical Device Regulators Forum’s 2025 good machine learning practice principles also emphasize safe, effective, and high-quality development across the medical-device lifecycle (International Medical Device Regulators Forum, 2025). For hospitals, this means AI oversight cannot stop at procurement, validation, or launch. A tool may work at installation and weaken later. Patient populations may shift. Documentation patterns may change. New equipment may alter input data. Clinicians may use the system differently from the intended use. Monitoring has to continue as long as the tool influences care.
Lifecycle monitoring requires practical ownership. Someone has to know which AI tools are active, what they do, who uses them, what data they read, how they were validated, when performance was last reviewed, how safety events are reported, and what happens when a tool produces unacceptable error patterns. Without this inventory and review discipline, hospital AI becomes invisible infrastructure. Invisible infrastructure can fail quietly.
2.6 Literature gap addressed by this research paper
The literature provides strong guidance on technical performance, reporting standards, ethics, regulation, and implementation. What hospital leaders often still lack is an integrated management frame. They need a way to connect clinical use cases to workflow, governance, clinician trust, patient communication, equity review, and lifecycle safety. The case approach used here answers that need by reading Mayo Clinic’s public AI activity through a practical transformation lens.
This paper therefore avoids a narrow technology-adoption story. It treats AI-enabled transformation as the alignment of clinical problems, institutional capacity, professional interpretation, and patient-centered safeguards. The model is intentionally modest. It does not rate Mayo Clinic as an official institution, and it does not claim access to internal outcome data. It provides a research-grounded way to think about the conditions under which hospital AI becomes clinically serious.
Chapter 3: Methodology: Case Logic, Readiness Modeling, and Source Discipline
3.1 Research design
The study uses a qualitative case-study design supported by illustrative modeling. The method fits the subject because hospital AI is not a single measurable event. It is a set of interacting conditions: data maturity, clinical relevance, workflow placement, professional adoption, governance, equity, safety monitoring, and patient communication. A purely technical method would miss institutional behavior. A purely theoretical method would risk becoming detached from the specific clinical settings in which AI is being used.
Mayo Clinic is used as the central case because its public materials present AI as part of clinical transformation rather than as a detached technology initiative. The institution’s AI priorities include clinical trial matching, remote monitoring, imaging-based detection, and risk anticipation (Mayo Clinic, n.d.). Its cardiovascular AI work is publicly described in relation to early risk prediction and diagnosis of serious or complex heart problems (Mayo Clinic, 2025). These use cases allow the study to examine the relationship between computational tools and clinical decisions.
The design is documentary and interpretive. Sources include Mayo Clinic public pages, peer-reviewed medical AI literature, international ethics and reporting guidance, and regulatory materials. No confidential Mayo Clinic information is used. No claims are made about internal performance metrics, proprietary models, patient outcomes, or staff perceptions. This boundary is important. It protects the research from overclaiming and keeps the case analysis grounded in verifiable public evidence.
3.2 Case logic and analytical categories
The case is read through six analytical categories: clinical intelligence, workflow integration, clinician trust, governance maturity, patient-safety monitoring, and equity discipline. Clinical intelligence refers to the ways AI helps professionals detect patterns, anticipate risk, or connect patients to options. Workflow integration concerns whether the information reaches clinicians at a useful time and in a usable form. Clinician trust addresses adoption as judgment, not compliance. Governance maturity refers to decision rights, validation, accountability, privacy, and review. Patient-safety monitoring concerns post-deployment oversight. Equity discipline asks whether benefits and risks are distributed fairly.
These categories are not accidental. They reflect recurring concerns in the literature. Rajkomar et al. (2019) emphasize the role of machine learning in processing medical data. Kelly et al. (2019) warn of the gap between promising systems and clinical impact. Liu et al. (2020) and Vasey et al. (2022) stress reporting and early clinical evaluation. WHO (2021) places ethics and human rights at the center of health AI. FDA and IMDRF sources reinforce the lifecycle dimension of regulatory and quality oversight (International Medical Device Regulators Forum, 2025; U.S. Food and Drug Administration, 2025, 2026).
3.3 Conceptual readiness model
The research uses a simple readiness model as a teaching and decision aid. It is not a statistical audit. It helps readers see how AI-enabled clinical capability depends on multiple institutional conditions. The model is expressed as: ΔC = mA + b. In this expression, ΔC represents change in clinical transformation capacity, A represents AI-enabled clinical capability, m represents the marginal transformation effect associated with that capability, and b represents baseline clinical capacity before AI integration.
The formula is deliberately simple because the purpose is conceptual clarity. A hospital with excellent AI tools but weak governance will not transform responsibly. A hospital with good data but poor workflow integration may generate unused alerts. A hospital with strong model performance but weak clinician trust may create resistance. A hospital with sophisticated prediction but poor patient communication may damage confidence. The readiness model therefore treats AI capability as a composite condition rather than a single score.
For illustrative purposes, the paper uses five dimensions of AI-enabled clinical capability: data infrastructure, clinical use cases, physician adoption, governance maturity, and patient-safety monitoring. The scores used in the charts are author-developed and interpretive. They are derived from the logic of public case materials and scholarly expectations, not from internal Mayo Clinic data. The visual models are designed to support analysis, classroom use, and executive discussion. They do not provide official institutional ratings.
3.4 Figure protocol and evidence discipline
Each figure in this research paper is clearly marked as illustrative. The charts translate the argument into visual form, but they do not create new empirical facts. This distinction matters because colorful figures can appear more authoritative than the evidence permits. The paper therefore uses figure notes to prevent misinterpretation. Readers should treat the charts as structured case-study illustrations that support discussion of hospital readiness, clinical value, and implementation risk.
The charts are also copyrighted and watermarked in the author’s name. This supports publication control and protects the intellectual design of the paper. The use of charts in a master’s-level research publication is appropriate when the visuals clarify relationships that prose alone can obscure. In this case, the charts show that AI transformation involves more than model performance. It requires a system of clinical, operational, ethical, and professional conditions.
Read also: Managed Care Models In Healthcare By Cynthia Anyanwu
Chapter 4: Case Analysis: Mayo Clinic and AI-Enabled Clinical Transformation
4.1 Mayo Clinic’s public AI profile
Mayo Clinic’s public AI materials frame the technology around clinical usefulness. The institution describes AI as supporting clinical trial matching, remote health monitoring, imaging-based detection, and earlier disease-risk anticipation (Mayo Clinic, n.d.). These domains are significant because they touch several moments in the patient journey: identifying risk, interpreting evidence, selecting pathways, monitoring outside the hospital, and connecting patients to research. AI is therefore not presented only as a tool for back-office efficiency. It is connected to clinical attention.
That clinical orientation separates meaningful transformation from digital display. Hospitals can easily become fascinated with visible technology while leaving the quality of care unchanged. A system that helps identify subtle disease patterns, however, changes the timing of clinical knowledge. A system that helps match patients to trials can alter the boundary between routine care and research opportunity. A remote-monitoring tool can extend the hospital’s view beyond the scheduled appointment. These are serious changes because they alter when and how clinicians notice patients.
4.2 Clinical use cases and the movement from data to attention
Figure 1 presents the main clinical use-case domains used in this analysis. Imaging support receives the highest illustrative score because visual interpretation remains one of the strongest areas for machine-learning assistance. Cardiovascular AI also scores strongly because Mayo Clinic’s public cardiovascular AI material describes early risk prediction and diagnosis for serious or complex heart problems (Mayo Clinic, 2025). Predictive risk detection, individualized care, remote monitoring, and clinical trial matching complete the profile. The scores are not official measures. They express case-study weightings for discussion.
The point behind the figure is not that all AI use cases carry equal clinical force. Some systems operate near diagnosis. Others support monitoring, research access, administrative flow, or risk stratification. A hospital needs to know where an AI tool sits in the clinical chain. A system that influences diagnosis or treatment selection requires more rigorous oversight than a low-risk administrative triage tool. A remote-monitoring algorithm that triggers intervention needs different governance from a tool that sorts research records. Use-case clarity is the beginning of safety.
Clinical value depends on the movement from data to attention. A hospital already contains enormous quantities of information. The difficult question is whether that information reaches the right person in the right form at the right time. Imaging algorithms can help radiologists or specialists see patterns that are subtle. Cardiovascular tools can help clinicians identify risk earlier. Trial-matching systems can locate opportunities that busy teams may miss. Remote monitoring can reveal deterioration between appointments. These contributions are valuable only if they change clinical attention without overwhelming it.
Figure 1. Mayo Clinic AI-Enabled Clinical Use Cases.
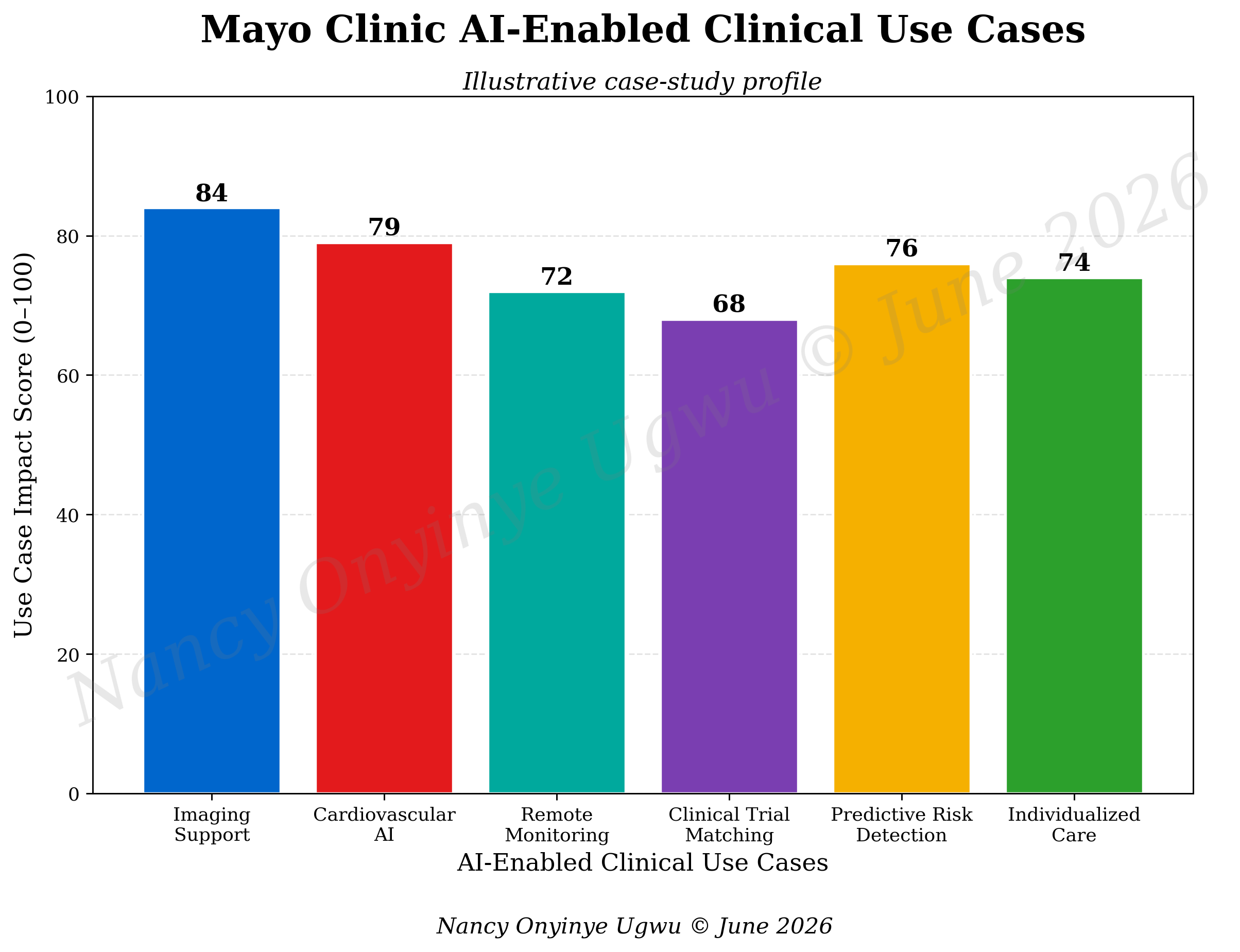
Note. Author-developed illustrative chart prepared for NYCAR research publication; values are case-study weights, not official Mayo Clinic performance measures.
4.3 Cardiovascular AI and anticipatory medicine
Cardiovascular medicine gives the case particular force. Heart disease often develops silently before a severe event occurs. Traditional clinical assessment relies on history, examination, ECGs, imaging, laboratory tests, risk factors, and specialist interpretation. These methods remain essential. AI may add another layer by detecting patterns across signals that human review may not combine at scale. Mayo Clinic’s cardiovascular AI work is publicly described as applying AI tools and technology to early risk prediction and diagnosis in heart disease (Mayo Clinic, 2025).
The deeper change is temporal. Predictive systems shift medicine from waiting for disease to present toward recognizing risk before the patient deteriorates. That shift is valuable, but it also creates responsibility. A risk prediction can alter how a patient understands their future. It may justify further testing, closer monitoring, lifestyle counseling, medication, specialist referral, or reassurance. It can also create anxiety if poorly communicated. The clinician’s role becomes more important, not less, because probability has to be translated into care.
Anticipatory medicine cannot be reduced to early alarms. A hospital needs a path from signal to action. Who receives the signal? How urgent is it? What clinical threshold requires intervention? How is uncertainty documented? What happens if the patient’s risk is high but the evidence is ambiguous? Who explains the finding? Without an answer to those questions, prediction becomes noise. With disciplined pathways, AI can help turn risk into timely and humane care.
4.4 Clinical trial matching and research access
Mayo Clinic’s public AI page describes a future in which AI helps select and match patients with promising clinical trials (Mayo Clinic, n.d.). This is a clinically important use case because research access is often uneven. Eligibility criteria can be complex, patient records can be fragmented, and clinicians may not have time to search every trial. Matching tools can make hidden possibilities visible. For a patient with a serious condition, a trial opportunity can matter deeply.
The ethical challenge is to avoid treating trial matching as a purely computational exercise. Eligibility is not the same as suitability. A patient may technically match criteria but face travel burdens, family responsibilities, language barriers, financial pressures, health limitations, or distrust of research. A tool can open a door; the institution must still support the person walking toward it. Consent, explanation, access, and patient preference remain central.
Clinical trial matching also tests equity. If the records that feed the tool are incomplete for underrepresented populations, the benefits may flow toward patients who are already more visible to the health system. A responsible trial-matching program needs monitoring across demographic and clinical groups. It also needs human outreach that does not assume a match is meaningful until the patient can understand the option and make a free decision.
4.5 Remote monitoring and the widening boundary of the hospital
Remote monitoring changes the geography of care. A hospital no longer sees the patient only during scheduled encounters. Wearables, home devices, digital symptom reporting, and connected platforms allow the institution to observe patterns outside the clinical building. AI can help sort these streams by detecting trends, escalating risk, and filtering noise. Mayo Clinic’s public AI priorities include remote health monitoring devices as part of its future-oriented AI work (Mayo Clinic, n.d.).
The benefit is clear. Chronic disease, post-discharge recovery, heart failure, arrhythmia risk, and medication-related symptoms can worsen between appointments. Remote intelligence may help clinicians intervene earlier. It may also keep some patients out of unnecessary hospital visits when monitoring shows stability. Yet the risks are equally real. More data can create more alerts, more worry, more responsibility, and more work. A hospital that expands monitoring without a response system may create false reassurance or operational chaos.
Remote monitoring therefore requires service design. Patients need to know what is being monitored, what the hospital will do with the information, when they will be contacted, and what responsibility remains with the patient or caregiver. Clinical teams need clear thresholds, staffing, escalation protocols, and documentation practices. AI can filter signal from noise, but the institution must decide how the signal becomes care.
4.6 Workflow integration and clinician trust
AI systems enter busy clinical settings, not silent laboratories. A ward round has interruptions, family questions, medication changes, documentation demands, and urgent decisions. An emergency department faces crowding, uncertainty, and time pressure. A specialist clinic must interpret complex histories while maintaining a human conversation. In these environments, a tool that adds clicks, unclear scores, or poorly timed alerts can weaken care even when the underlying model is strong.
Clinician trust grows through repeated usefulness. A physician does not need a tool to pretend certainty. Clinicians are trained to work with uncertainty. They need to know what the output means, when it applies, where it is unreliable, and what action is appropriate. They also need freedom to challenge the system. A tool that cannot be questioned is professionally unacceptable. Trust is earned when AI behaves like a disciplined instrument, not like a hidden authority.
Figure 2 shows the transformation priorities in hospital AI, with data infrastructure, workflow integration, clinician adoption, patient-safety monitoring, governance maturity, and individualized care weighted together. The figure’s central message is that the technical system is only one part of readiness. Workflow and professional adoption carry nearly the same importance as data capability. Hospitals that ignore this balance risk building tools that exist on paper but fail at the point of care.
Figure 2. AI Transformation Priorities in a Hospital Setting.
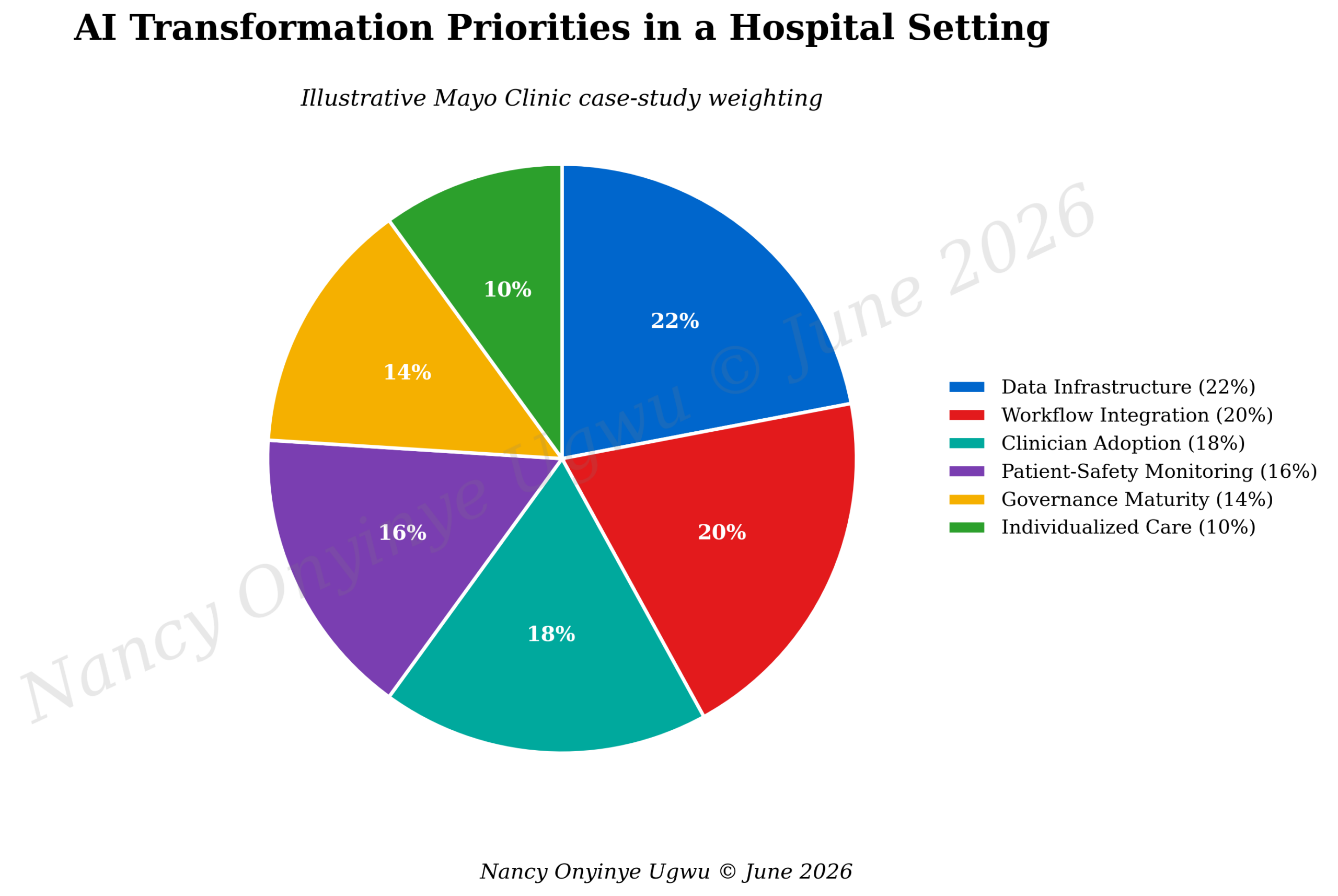
Note. Author-developed illustrative chart prepared for NYCAR research publication; percentages express conceptual weighting for the case analysis.
4.7 Individualized care without reducing the person to a profile
AI can help individualize care by connecting information across images, laboratory values, clinical history, medications, genomics, and physiologic patterns. In principle, this can move medicine away from crude averages and toward more specific treatment pathways. For Mayo Clinic, where specialty care and complex diagnosis are part of the institutional identity, individualized medicine is a natural area for AI-supported work.
The danger is that personalization becomes technical without becoming humane. A patient is not the same as a data profile. People bring fears, values, family obligations, culture, finances, past experiences, and personal tolerance for risk. A predictive output may be clinically useful and still emotionally difficult. The clinician must translate the output into a conversation that respects the whole person. AI can support individualized care only if it is brought back into human judgment.
This distinction matters for master’s-level hospital management because technology projects often count outputs rather than experiences. A model may generate a precise prediction, but the patient may leave confused. A care pathway may be personalized by data, but the person may feel standardized by the system. Hospitals need measures that include understanding, trust, access, equity, and follow-through. Clinical intelligence must serve the patient, not display the institution’s sophistication.
4.8 Governance and safety in a living system
Governance is the backbone of hospital AI. A tool that influences care requires oversight before deployment, during use, and after evidence changes. Who approves the tool? What evidence is enough for clinical use? How are errors reported? How does the hospital detect drift? Who checks subgroup performance? What happens when a vendor updates the model? Which committee can pause or remove the system? These questions sound administrative, but they are patient-safety questions.
Figure 3 presents transformation readiness dimensions. Data infrastructure, clinical AI use cases, physician adoption, governance maturity, and patient-safety monitoring are scored as linked domains. A weakness in one domain reduces the value of the others. Strong data cannot compensate for poor governance. Good governance cannot rescue a tool that clinicians find useless. Patient-safety monitoring cannot matter if no one acts when performance changes. Readiness is a relationship among domains.
Figure 4 describes sources of clinical value from hospital AI. Earlier detection, decision support, remote monitoring, personalized care, research matching, and operational coordination all contribute to value, but none works safely alone. Earlier detection needs follow-up. Decision support needs explanation. Remote monitoring needs thresholds. Personalized care needs equity. Research matching needs consent. Operational coordination needs clinical relevance. This is why hospital AI should be governed as a system of care, not as a collection of tools.
Figure 3. Transformation Readiness Dimensions.
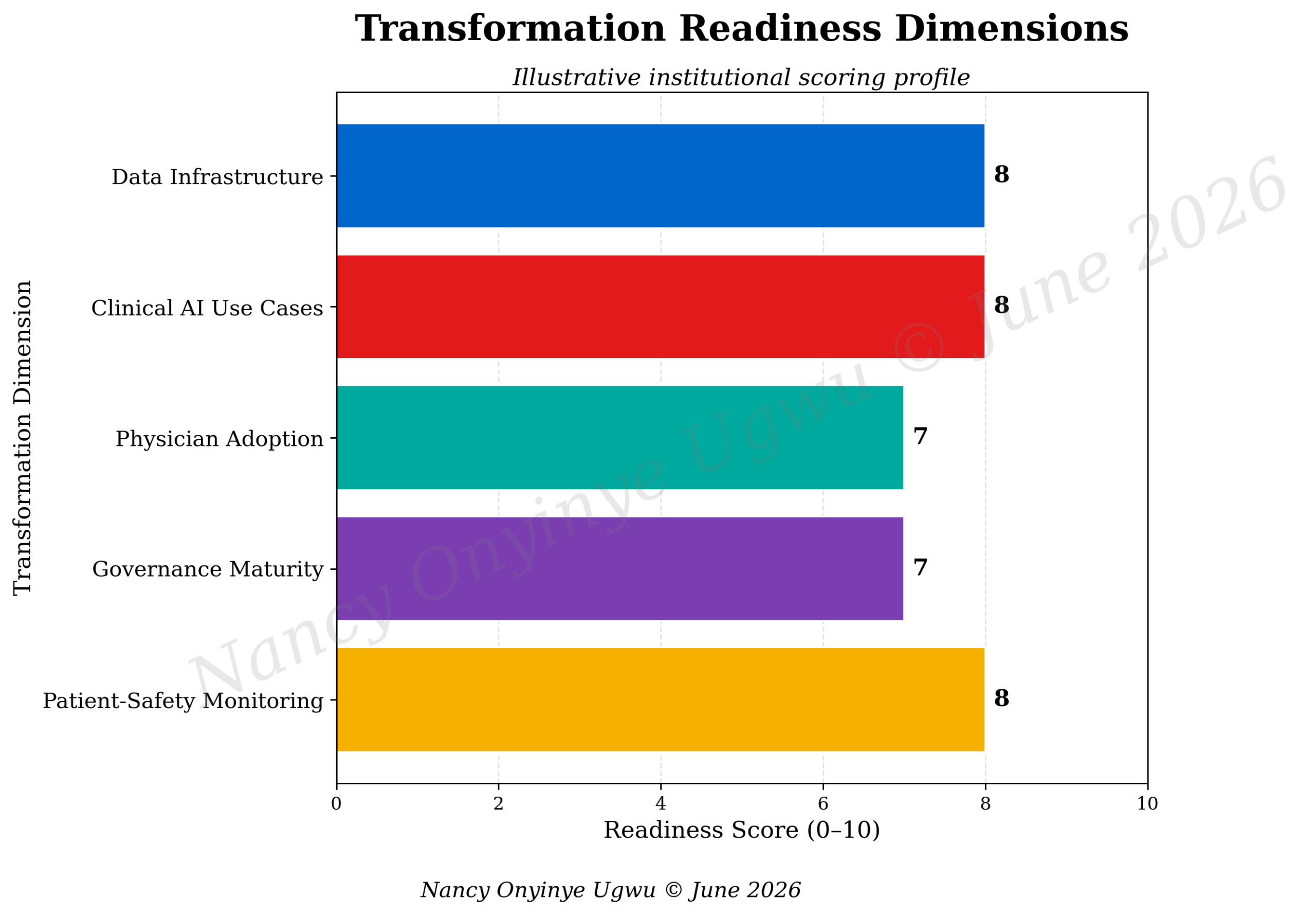
Note. Author-developed illustrative chart prepared for NYCAR research publication; scores are interpretive readiness indicators, not audited institutional ratings.
Figure 4. Sources of Clinical Value from Hospital AI.
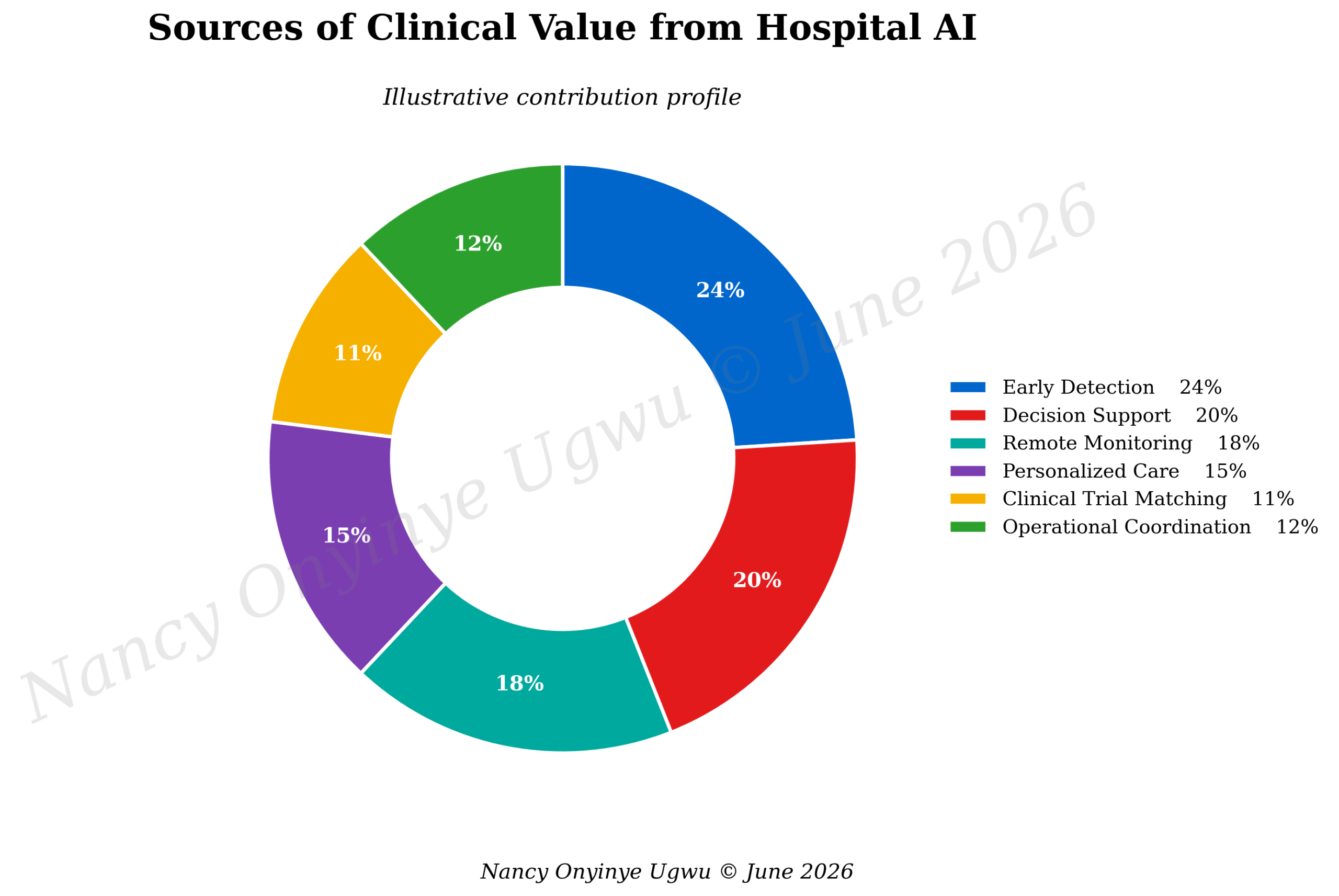
Note. Author-developed illustrative chart prepared for NYCAR research publication; percentages represent conceptual contribution weights.
4.9 Risk pressures and safeguards
Figure 5 shows risk pressures that can undermine hospital AI. Workflow burden and alert fatigue sit near the top because clinicians experience technology through time and attention. Model drift matters because performance can change. Automation bias is a danger when professionals over-trust a system because it appears mathematically confident. Data bias can reproduce unequal access. Privacy concerns can weaken patient trust even when the clinical tool is promising.
Hospital leaders sometimes treat these risks as barriers to innovation. A stronger view treats them as design requirements. Workflow burden requires co-design with clinicians. Alert fatigue requires thoughtful thresholds and user testing. Model drift requires monitoring. Automation bias requires education and professional challenge. Data bias requires subgroup analysis and corrective review. Privacy concern requires transparency, security, and ethical governance. AI becomes safer when risks are addressed as part of the operating model rather than as objections raised after launch.
Figure 6 summarizes potential clinical gains. Earlier detection, decision support, remote monitoring, care coordination, personalized treatment, and research matching all appear as high-value areas. The figure also makes a subtle point. The gains are not equal to the tool itself. They depend on whether the hospital can convert insight into action. A prediction that does not reach care coordination is wasted. A trial match that cannot be discussed with the patient is incomplete. A monitoring alert without staffing is unsafe. Clinical gain is a managed result.
Figure 5. Implementation Risks That Can Undermine Hospital AI.
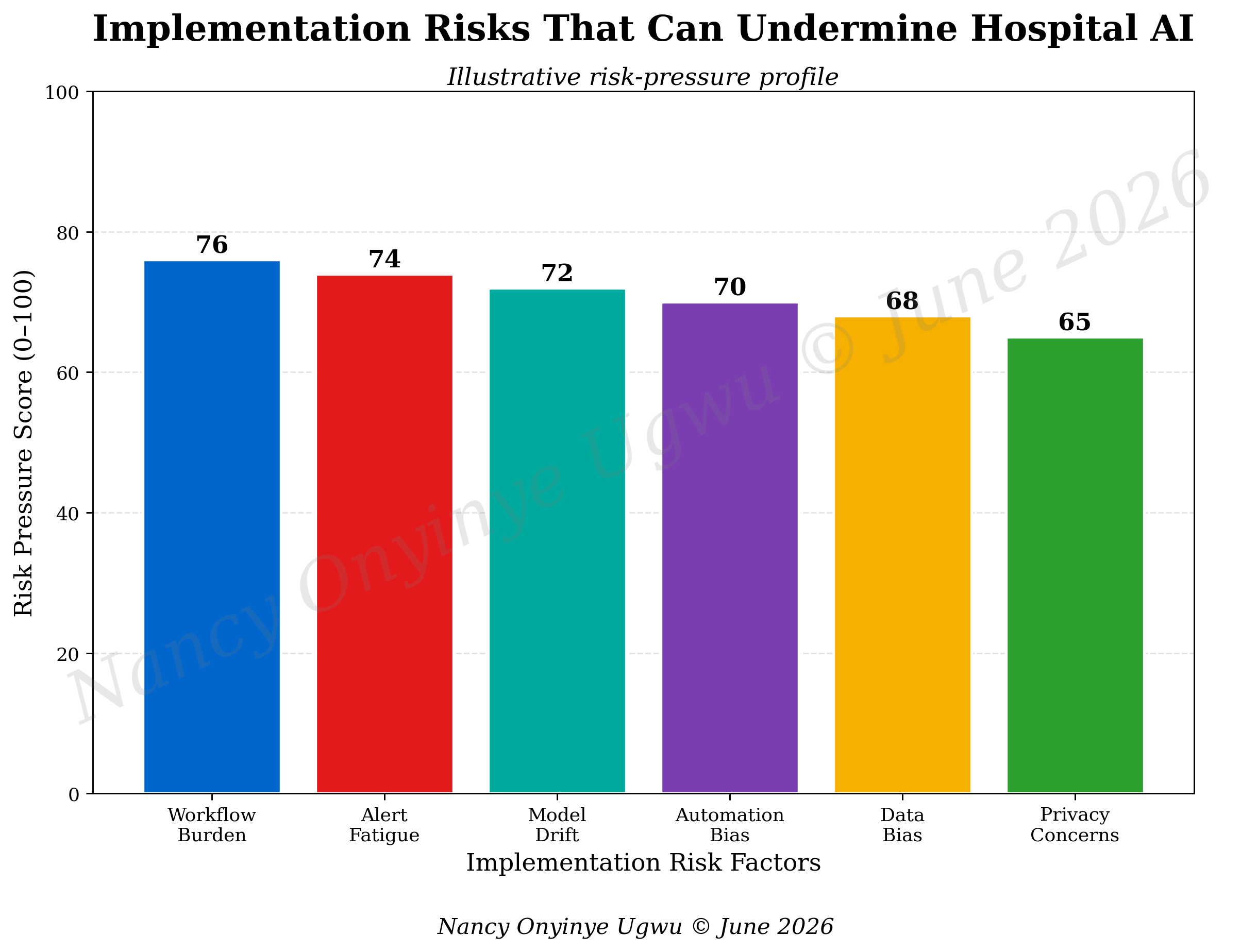
Note. Author-developed illustrative chart prepared for NYCAR research publication; risk-pressure values are diagnostic estimates for discussion.
Figure 6. Potential Clinical Gains from AI-Supported Care.
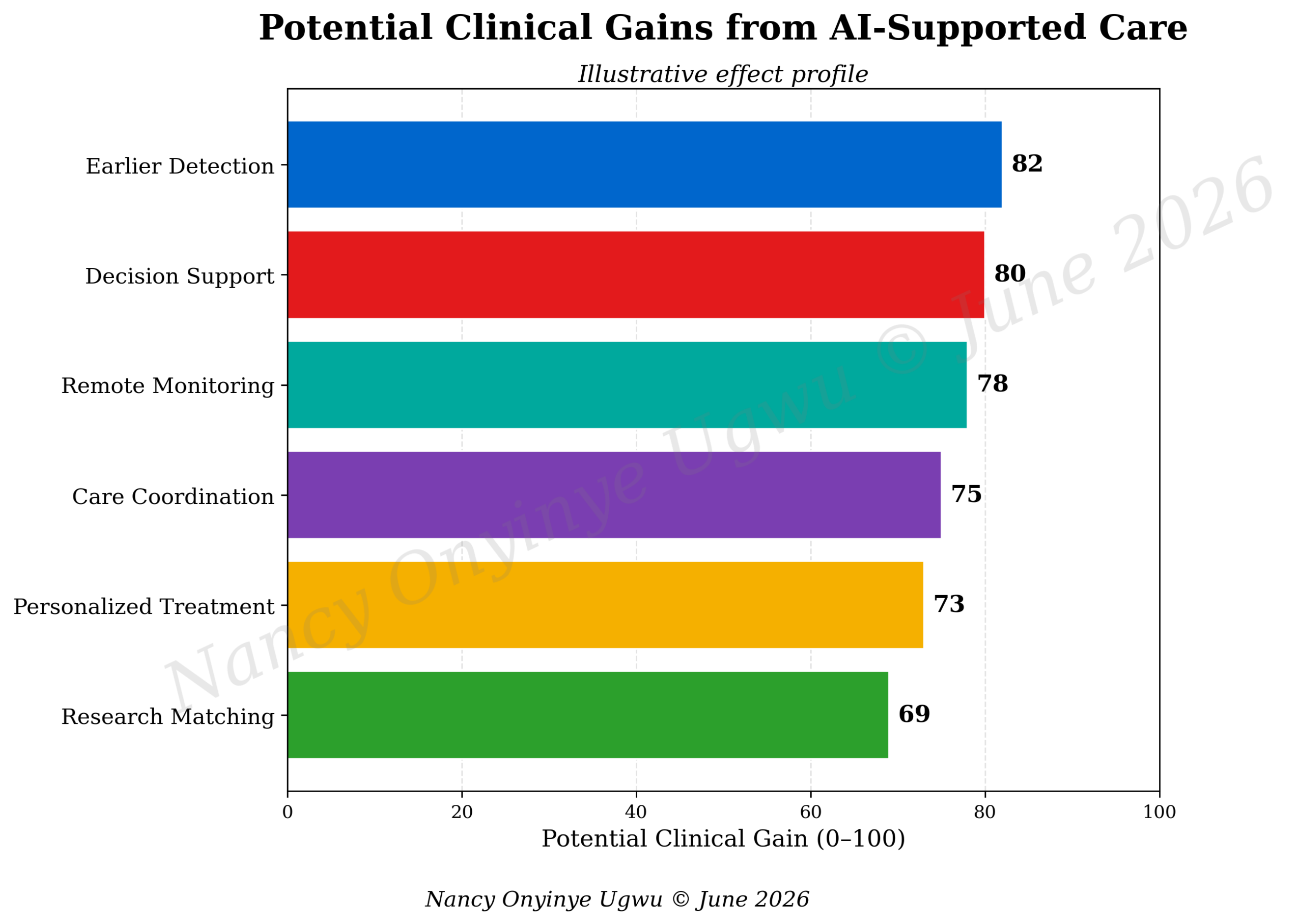
Note. Author-developed illustrative chart prepared for NYCAR research publication; values are conceptual effect scores, not official outcome data.
4.10 Mayo Clinic readiness profile
Figure 7 brings the case together as a radar profile. The figure illustrates balanced strength across data infrastructure, clinical use cases, physician adoption, governance maturity, patient-safety monitoring, and workflow integration. The profile is intentionally not perfect. It signals that even a leading institution needs continuous work in governance, adoption, and workflow. A mature hospital does not claim completion. It builds systems that keep learning.
The Mayo Clinic case points toward a model of AI-enabled transformation in which the hospital becomes more anticipatory, more evidence-sensitive, and potentially more personalized without surrendering the human center of care. That promise is real. It is also conditional. The hospital must keep clinicians in charge of interpretation, monitor systems after deployment, protect patients against inequitable performance, and explain AI-supported decisions in language that preserves trust.
Figure 7. Mayo Clinic AI Readiness Profile.

Note. Author-developed illustrative chart prepared for NYCAR research publication; radar values provide a multidimensional case profile for teaching and review.
Chapter 5: Discussion: Governance, Trust, and the Conditions for Responsible Transformation
5.1 What transformation means in hospital practice
Hospital transformation is often confused with digital modernization. The two are related, but they are not the same. Modernization can mean new platforms, new software, new dashboards, and new procurement. Transformation means a change in how care is delivered and understood. In the context of AI, transformation appears when clinicians receive better evidence at the point of decision, patients gain clearer pathways, avoidable delay is reduced, and the institution becomes more capable of detecting and correcting risk.
This distinction matters because hospitals can become crowded with tools. Each tool arrives with claims of efficiency, prediction, convenience, or integration. Clinicians then face another screen, another alert, another score, another workflow demand. The hospital may appear modern while professionals feel less able to think. A serious AI strategy therefore begins with clinical problems, not vendor capability. The question is not what the system can do. The question is which clinical risk, delay, decision, or inequity it will help the hospital address.
Mayo Clinic’s public AI framing is useful because it connects AI to clinical trial matching, disease-risk anticipation, imaging, remote monitoring, and cardiovascular medicine. These are care problems rather than abstract digital ambitions. They ask whether patients can be seen earlier, matched better, monitored more intelligently, and treated with more precise evidence. That is the right test. Hospital AI must justify itself in the life of care.
5.2 Leadership responsibilities in AI-enabled hospitals
AI transformation requires leadership beyond the technology office. Data scientists and informatics teams are necessary, but they cannot carry the whole responsibility. Hospital executives, physician leaders, nurses, patient-safety officers, privacy experts, ethics committees, legal counsel, quality teams, and patient representatives all have a role. A tool that touches care also touches institutional accountability.
Leadership needs to ask more difficult questions than those found in ordinary procurement. What clinical problem does the tool solve? Which patients will be affected? What evidence supports use in this setting? What burden will be placed on clinicians? What training is required? How will patients be informed? What subgroup performance data exist? Who monitors the tool after launch? What will cause the hospital to pause or remove it? These questions define the difference between buying technology and governing clinical intelligence.
AI leadership also needs restraint. A hospital does not need to deploy every tool that appears promising. Some systems may be premature. Some may work in one specialty but fail in another. Some may increase administrative burden without improving patient outcomes. Some may produce reputational excitement while offering little clinical value. Strategic restraint is part of responsible innovation. It protects patients, staff, and the credibility of the institution.
5.3 Physician adoption as interpretive trust
Adoption cannot be measured only by logins, clicks, or compliance. A clinician may use a system because it is mandatory and still distrust its output. Meaningful adoption is interpretive trust. The clinician understands what the tool does, where it is reliable, how uncertainty is expressed, and when professional judgment should override it. This form of adoption is intellectual, not mechanical.
Trust also requires humility from AI designers and hospital leaders. A model may process more data than a clinician, but it does not know the patient as a person. It does not hear the hesitation in a patient’s voice, recognize a family’s fear, understand the social meaning of a diagnosis, or carry responsibility for the outcome. Clinicians may resist tools that ignore these dimensions, and that resistance can be rational. Trust grows when the technology respects clinical practice rather than treating it as an obstacle.
Training needs to support this trust. Clinicians do not need to become machine-learning engineers, but they do need practical literacy. They need to understand data quality, validation, calibration, uncertainty, subgroup performance, automation bias, and error reporting. They need to know when a model’s output is a prompt for further thought rather than a command. AI literacy is becoming a patient-safety skill.
5.4 Patient communication and consent
Patients deserve plain language. If AI meaningfully contributes to diagnosis, prediction, monitoring, or treatment planning, the hospital needs a way to explain that role without hiding behind technical vocabulary. A patient does not need a lecture on model training, but they may need to know that a tool analyzed an ECG, image, clinical record, or monitoring pattern and helped the care team identify a risk. They also need to know that a human professional remains accountable.
Consent practices will vary by use case. Some tools may fall within ordinary clinical operations, while others may involve research, secondary data use, remote monitoring, or trial matching. The ethical standard is not a single form. It is respectful clarity. Patients should not feel that they were unknowingly placed inside a technological process that changed their care. Trust is strengthened when the institution explains the purpose, benefits, risks, and limits of AI-supported care at the right moment.
Communication must also address emotional consequences. A prediction can be frightening. A risk score can feel like a sentence. A trial match can create hope and anxiety. A remote monitoring alert can disturb a patient’s sense of stability. The clinician’s task is to interpret the information with care, not simply relay it. Hospitals that train clinicians in AI use also need to train them in AI explanation.
5.5 Equity as a measure of success
AI-enabled transformation is incomplete if it improves care only for patients who are already well served. Equity is not an optional value statement. It is a test of clinical validity and institutional legitimacy. A model that performs poorly for a subgroup is clinically weak even if its average score looks strong. A trial-matching tool that identifies opportunities mainly for well-documented patients may widen research inequity. A remote-monitoring program that assumes reliable devices, broadband, language access, and digital confidence may miss the very patients who need support.
Hospitals need equity monitoring throughout the AI lifecycle. Before deployment, they need to understand the data sources, patient populations, outcome labels, and validation evidence. During use, they need to examine performance across groups. After implementation, they need to ask who benefited, who was missed, and whether the tool changed access, experience, or safety. Equity review cannot be reduced to a one-time checklist.
Mayo Clinic’s case suggests the value of institutional capacity. A major health system has more resources for validation, quality review, and clinical governance than many smaller hospitals. That advantage should not become complacency. The better lesson is that capacity creates a duty. Institutions with the ability to test, monitor, and publish responsibly should set high standards for the field.
5.6 Data governance, privacy, and cybersecurity
AI systems depend on data, and hospital data are among the most sensitive forms of personal information. Clinical records contain diagnoses, medications, genetic information, mental health history, family details, images, insurance data, and deeply personal narratives. Patients may accept data use for care, but they may feel differently about secondary research, commercial partnerships, model training, or remote-monitoring streams. Governance must therefore address data purpose, access, security, retention, consent, de-identification, and accountability.
Privacy is not a legal technicality. It is part of the therapeutic relationship. A patient who fears that health information is being used without understanding or control may withhold information or lose confidence in the institution. Cybersecurity also becomes central because AI systems can create new attack surfaces. A predictive tool connected to clinical data, device input, or workflow systems must be protected with the seriousness appropriate to patient safety.
Hospital leaders need a clear inventory of AI tools and data flows. Which systems access patient data? Which vendors or partners are involved? Where is data stored? What standards apply? How are access rights controlled? How are breaches detected and reported? Without such clarity, the institution cannot credibly claim control over AI-enabled care.
5.7 From pilots to institutional learning
Hospitals often launch pilots with enthusiasm and then struggle to scale, stop, or learn from them. AI pilots are especially vulnerable to this problem because early results can be exciting while implementation burden remains hidden. A pilot may work because a small group of motivated clinicians supports it. Scaling may fail when the tool enters ordinary practice with different users, different patients, and less intensive support.
A disciplined AI program needs exit criteria as well as scale criteria. What evidence justifies expansion? What safety concern requires pause? What level of clinician burden is unacceptable? What equity gap requires redesign? What patient outcome matters? What cost is justified? These questions prevent pilots from becoming permanent experiments without accountability.
Learning also requires honest reporting. If an AI system fails to improve care, the institution should know why. Was the model weak? Was the workflow wrong? Was training inadequate? Was the clinical problem poorly chosen? Was leadership too optimistic? Failure can be useful if it is documented and examined. It becomes wasteful when buried under innovation language.
Chapter 6: Recommendations and Conclusion: Building Trustworthy AI-Enabled Hospitals
6.1 Practice recommendations for hospital leaders
Hospitals should begin AI transformation with a clear clinical problem. The problem should be specific enough to evaluate: delayed diagnosis, missed risk, inefficient trial matching, avoidable readmission, imaging backlog, deterioration between appointments, medication harm, documentation burden, or uneven access. A tool without a defined clinical problem is a technology looking for justification. A serious institution reverses the sequence. It starts with care.
Each proposed AI system should pass through a multidisciplinary review before clinical use. The review should include clinicians from the affected specialty, patient-safety leadership, informatics, data science, privacy, legal or compliance expertise, ethics, nursing or allied health representation where relevant, and patient perspective when the use case materially affects patient experience. The review should examine evidence quality, workflow impact, patient communication, equity, cybersecurity, accountability, and lifecycle monitoring.
Hospitals need a live inventory of AI-enabled clinical tools. The inventory should record the tool’s purpose, owner, affected service line, data sources, vendor or internal developer, intended users, validation evidence, go-live date, monitoring schedule, safety-reporting pathway, and retirement criteria. This may sound ordinary, but it is essential. Institutions cannot govern what they cannot see.
6.2 Recommendations for clinicians and clinical educators
Clinical education should include practical AI literacy. Physicians, nurses, pharmacists, therapists, and other professionals need training that connects model output to clinical interpretation. The training should explain what AI can and cannot mean, how uncertainty appears, how bias can enter a model, how to report unsafe outputs, and how to communicate AI-supported findings to patients. Education should be grounded in real clinical scenarios rather than abstract enthusiasm.
Clinicians should treat AI outputs as evidence prompts. A prompt may be strong or weak, clear or uncertain, urgent or exploratory. It should not be treated as a final decision. Professional responsibility includes the right to challenge, override, or seek clarification. Hospitals need to protect that right explicitly. A clinician who disagrees with a model should not be treated as obstructive when the disagreement is grounded in patient context or clinical reasoning.
Clinical educators can use the Mayo Clinic case to teach responsible adoption. Students can examine how cardiovascular AI changes timing, how trial matching affects access, how remote monitoring expands care boundaries, and how workflow determines usefulness. Such teaching moves AI from abstraction into practice. It helps future professionals see the ethical and operational work behind every digital tool.
6.3 Recommendations for patient safety and quality teams
Patient-safety teams should treat clinical AI as part of the safety system. This means tracking incidents, near misses, unexpected outputs, alert fatigue, inequitable performance, workflow workarounds, and user confusion. Safety review should not wait for a severe event. Weak signals matter. A pattern of ignored alerts, unexplained overrides, or clinician frustration can signal a design problem before patient harm becomes visible.
Quality teams should build post-deployment review into the life of every significant AI tool. Reviews should examine accuracy, calibration, false positives, false negatives, clinician response, patient outcome relevance, subgroup performance, and workflow burden. A tool that once performed well may need recalibration or retirement. The healthcare environment changes, and a responsible system changes with it.
Hospitals should also create clear pathways for patients and staff to raise concerns about AI-supported care. A patient who feels confused by AI use should have a way to ask questions. A clinician who sees a troubling pattern should know where to report it. A safety culture that ignores AI concerns because they sound technical will miss early warnings.
6.4 Recommendations for researchers
Researchers should publish with enough detail to support clinical interpretation. CONSORT-AI and DECIDE-AI provide useful standards for reporting AI interventions and early-stage decision-support evaluations (Liu et al., 2020; Vasey et al., 2022). Research papers should describe intended use, human-AI interaction, input data, workflow context, error handling, and implementation conditions. A model cannot be responsibly assessed if readers cannot tell how it was used.
Hospital AI research should also examine patient experience, clinician behavior, equity, and long-term monitoring. Too many studies focus on technical performance while giving less attention to the clinical setting. Hospitals need evidence on whether tools change decisions, reduce harm, save time, improve access, or create unintended burden. The research agenda should follow the patient pathway, not just the model output.
6.5 Final conclusion
Mayo Clinic’s case shows that AI-enabled clinical transformation is hopeful, but not simple. AI can help clinicians notice risk earlier, interpret complex data, connect patients to trials, monitor care beyond the hospital, and personalize treatment. These gains are worth pursuing. They are also conditional. Without workflow fit, professional trust, patient communication, equity review, privacy protection, and lifecycle monitoring, the same tools can create confusion, burden, bias, or unsafe overconfidence.
The future of hospital AI should not be imagined as machine medicine. That image is too thin for the moral and clinical realities of care. The better standard is accountable intelligence. In accountable intelligence, computational systems expand perception while clinicians retain judgment. Predictive tools support earlier action while governance protects safety. Data systems create insight while privacy protects dignity. Algorithms assist personalization while equity review asks who is being missed. Technology becomes part of care only when it remains answerable to the people it touches.
For hospitals, the lesson is demanding. AI cannot be treated as a purchase, pilot, or public-relations signal. It has to be governed as a clinical capability. Mayo Clinic’s public AI work offers a strong case through which to understand that capability. The institution’s example matters because it joins AI to real clinical domains, especially cardiovascular medicine, monitoring, imaging, individualized care, and research access. The wider lesson is useful for any hospital: responsible transformation begins when digital intelligence is disciplined by clinical purpose, human responsibility, and patient trust.
Chapter 7: Implementation Blueprint: From AI Adoption to Accountable Clinical Practice
7.1 The governance pathway from idea to clinical use
A hospital that wants to use AI responsibly needs a clear pathway from idea to clinical use. The pathway begins when a clinical team identifies a genuine care problem. That problem must be stated in clinical language before the technology conversation begins. “We need AI” is not a problem statement. “We miss early deterioration in a defined patient group,” “eligible patients are not being matched to trials,” “clinicians face unsafe alert volume,” or “post-discharge monitoring is not timely enough” are stronger starting points. A clear problem prevents the hospital from chasing tools that create visibility without clinical progress.
Once the problem is defined, the hospital should examine whether an AI-enabled tool is appropriate. Some problems require staffing, training, workflow repair, procurement changes, or ordinary quality improvement. AI is not always the right answer. When the tool appears justified, the institution needs evidence about intended use, validation, limitations, data sources, patient population, expected workflow, and safety risk. A clinical tool cannot enter practice because it looks promising in a vendor demonstration or retrospective study. It needs institutional scrutiny before it touches care.
The next stage is limited clinical evaluation. At this point, the hospital tests the system within a controlled environment, with clearly identified users, outcomes, reporting pathways, and review points. DECIDE-AI is useful here because it asks researchers and institutions to report the practical conditions of early clinical evaluation, including human interaction, context, and deviations from intended use (Vasey et al., 2022). This stage protects the hospital from premature scaling. A tool may succeed in one service line and fail elsewhere. It may work well for one group of clinicians and create burden for another.
Scaling should occur only when the evidence supports it and when governance can keep up. The hospital should know how training will be delivered, who owns the system, how patients will be informed, how adverse events or near misses will be reported, and what data will be reviewed after deployment. A responsible pathway also includes a stop rule. If the tool produces unacceptable errors, inequitable results, or unsustainable burden, the institution must have the courage to pause or withdraw it. Innovation without a stop rule becomes institutional vanity.
7.2 Clinical ownership and the limits of vendor confidence
Hospitals often rely on external technology partners, and those partnerships can be valuable. Vendor-built tools may bring engineering capacity, model development, user-interface expertise, and support services that hospitals cannot easily produce alone. Yet vendor confidence is not clinical proof. A company may understand model performance and still misunderstand the hospital setting. It may optimize for product adoption while clinicians worry about patient consequences. The hospital must therefore retain clinical ownership of the decision to use, scale, monitor, and discontinue the tool.
Clinical ownership means that responsible professionals can state what the system does, why the institution uses it, what evidence supports it, what risks remain, and how it is monitored. It also means that no department can treat the AI system as someone else’s problem. An imaging tool belongs to radiology and safety governance. A cardiovascular prediction tool belongs to cardiology, informatics, quality, and patient communication. A trial-matching tool belongs to research governance and clinical care. A remote-monitoring tool belongs to the service line that will respond when risk is detected.
The hospital must be especially careful when vendor materials use broad claims. “Improves efficiency,” “reduces burden,” “enhances outcomes,” and “supports clinical decision-making” are starting points for inquiry, not proof. Leaders should ask how each claim was measured, in which population, under what workflow, and with what comparison. They should also ask what harms were considered. A tool can save time in one part of the process while transferring burden elsewhere. It can reduce missed cases while increasing false positives. It can widen access for some patients while excluding others.
Mayo Clinic’s case is instructive because major academic medical centers have the capacity to develop, evaluate, and partner with sophistication. Smaller hospitals may not have the same internal expertise, which makes governance even more important. The lesson is not that every hospital can operate like Mayo Clinic. It is that every hospital needs enough clinical ownership to avoid becoming dependent on claims it cannot assess.
7.3 The human work of workflow redesign
Workflow is where AI succeeds or fails. A tool may be scientifically impressive and still unusable because it arrives in the wrong place. Clinicians do not experience technology as an abstract system. They experience it as another demand on attention, another screen, another message, another score, or another interruption in a day already saturated with tasks. Workflow redesign requires close observation of how care actually happens, not how a flow diagram says it happens.
A practical redesign process should involve the people who will use or be affected by the tool. Physicians, nurses, technicians, scheduling staff, care coordinators, and patients may all see risks that developers miss. In imaging support, the question may concern how results are displayed, how uncertainty is flagged, and how disagreement is documented. In cardiovascular risk prediction, the question may concern who receives the alert and what clinical pathway follows. In remote monitoring, the question may concern staffing, escalation, and after-hours response. In trial matching, the question may concern how a potential match enters a conversation with the patient.
Hospitals should test workflows under real pressure. A system that seems efficient during a demonstration may behave differently during clinic overload, staff absence, network downtime, or a surge in alerts. The institution should examine ordinary days and stressed days. It should study not just whether the tool works, but whether people can use it without losing clinical attention. A tool that forces clinicians to work around it is sending a message. The design has not yet learned from practice.
The human work of redesign also includes emotional labor. Clinicians may worry that AI will be used to judge their performance, replace their reasoning, or add medico-legal exposure. Patients may worry that a machine is making decisions. Managers may worry that the tool will fail to justify investment. These concerns should not be dismissed as resistance. They are part of implementation. A mature hospital addresses them openly because trust is built before scaling, not after conflict.
7.4 Patient-facing explanation as part of care quality
Patient-facing explanation is one of the most neglected parts of AI implementation. Hospitals often prepare technical documentation, governance minutes, and staff training while giving less attention to the sentence a clinician will use when speaking to a patient. Yet that sentence may decide whether the patient feels cared for or processed. A person told that “the algorithm flagged you” may react differently from a person told that “we used an additional computer-assisted tool to review your information, and it suggests a risk we want to discuss carefully with you.”
Good explanation avoids two errors. It does not exaggerate AI by making it sound like a final authority. It also does not hide AI by pretending the tool had no role in care. The right tone is honest, calm, and clinically grounded. The clinician can explain that the tool helps review patterns in data, that it supports the care team’s reasoning, that it has limits, and that the clinical decision remains human. Patients should also be invited to ask questions, especially when AI influences a significant decision.
Different use cases require different explanation. A tool that helps prioritize a radiology worklist may not need the same patient-level discussion as a system that predicts disease risk years in advance. A trial-matching tool requires consent-sensitive communication because the patient is being invited into a research pathway. A remote-monitoring system requires clarity about what will be watched, when the patient will be contacted, and what actions the patient should take. A cardiovascular prediction tool requires careful discussion of uncertainty and options.
Patient communication also protects equity. Patients with limited health literacy, language barriers, disability, prior distrust, or cultural concerns may need more than standard information. A hospital that treats explanation as a standard paragraph may miss these differences. The more consequential the AI-supported decision, the more important it becomes to ensure that communication is understandable, respectful, and responsive to the person in front of the clinician.
7.5 Evaluation after launch
AI evaluation should continue after launch because the hospital environment is alive. Patient populations shift. Staff change. Documentation habits change. Devices are updated. Clinical guidelines evolve. Model performance can drift. A tool that once helped may gradually become less reliable or more burdensome. This is why lifecycle thinking has become central in regulatory and safety discussions of AI-enabled medical tools (International Medical Device Regulators Forum, 2025; U.S. Food and Drug Administration, 2025).
Post-launch evaluation should include technical and clinical measures. Technical measures may include discrimination, calibration, missing-data sensitivity, false positives, false negatives, and drift indicators. Clinical measures may include time to intervention, diagnostic delay, patient outcomes, clinician response, ignored alerts, adverse events, and care coordination. Experience measures also matter: clinician burden, patient understanding, trust, and perceived usefulness. A tool that improves a metric while damaging professional attention may not be a true improvement.
Equity measures should be built into the same review process. Hospitals should not wait for a complaint to ask whether performance differs across patient groups. Subgroup monitoring must be designed carefully and ethically, with attention to privacy and data quality. When performance gaps appear, the institution needs a corrective pathway. That may involve recalibration, retraining, workflow change, additional validation, restricted use, or withdrawal.
Evaluation also needs public honesty at the right level. Internal details may remain confidential, and patient privacy must be protected. Still, institutions can communicate that AI tools are monitored, reviewed, and subject to correction. This builds trust. Patients and clinicians need to know that the hospital does not treat AI systems as permanent once installed. Continuous review is part of safe care.
7.6 What smaller hospitals can learn from the Mayo Clinic case
Mayo Clinic is a resource-rich academic medical center. Many hospitals cannot copy its infrastructure, specialty depth, research ecosystem, or internal analytic capacity. Copying the surface of the case would be a mistake. A smaller hospital may not need a wide portfolio of advanced AI tools. It may need a carefully selected system that addresses a specific problem, such as imaging triage, medication safety, remote monitoring for a high-risk group, or operational coordination for discharge planning.
The transferable lesson is discipline. Smaller hospitals can begin with clinical need, demand evidence, involve clinicians, protect patient communication, monitor safety, and establish clear ownership. They can also collaborate regionally, use external expertise, participate in shared evaluation networks, and adopt tools only when the governance burden is manageable. Responsible restraint may be a strength. A hospital that says no to an unsafe or poorly supported system is practicing good leadership.
Smaller institutions also need to be alert to dependency. A vendor may become the main source of technical knowledge. That creates risk if the hospital lacks enough internal literacy to ask hard questions. Even modest AI adoption requires basic competence in intended use, validation, privacy, security, equity, workflow, and post-launch review. Leaders do not need to build everything themselves, but they need enough understanding to remain accountable.
The Mayo Clinic case therefore becomes a teaching case rather than a template. It shows what happens when AI is tied to meaningful clinical domains and when transformation is imagined as a system of care. Other hospitals can adapt that logic to their size and capacity. The most important question is not whether a hospital resembles Mayo Clinic. It is whether the hospital can explain why an AI tool belongs in its care system and how it will protect patients after adoption.
7.7 Publication-level closing position
This research paper has treated hospital AI as accountable intelligence because that phrase captures the standard that healthcare deserves. Intelligence without accountability is not enough. Accuracy without workflow value is not enough. Prediction without explanation is not enough. Personalization without equity is not enough. Innovation without safety monitoring is not enough. The clinical promise of AI is real, but it becomes trustworthy only when the institution governs it with seriousness.
Mayo Clinic’s public AI work offers a strong setting for this argument because it points toward clinical domains where intelligence could matter deeply: disease-risk anticipation, cardiovascular diagnosis, imaging support, remote monitoring, clinical trial matching, and individualized care. These are not peripheral conveniences. They touch the timing, reach, and quality of medicine. They also show why the human center of care must remain protected. The more powerful the tool, the more serious the responsibility.
The final standard is practical. A hospital using AI should know what problem the tool solves, what evidence supports it, who is accountable, how clinicians use it, how patients understand it, how performance is monitored, how equity is protected, and when the system should be changed or stopped. If those questions cannot be answered, adoption is premature. If they can be answered and reviewed over time, AI may become part of a more attentive, safer, and more humane hospital.
Chapter 8: Limitations, Future Research, and Final Research Position
8.1 Limits of the case evidence
A publication-ready case study needs restraint as much as argument. Mayo Clinic’s public material gives enough evidence to examine visible AI priorities and the strategic logic around clinical transformation. It does not disclose every internal decision, committee process, validation file, staffing plan, equity audit, patient-safety report, or clinician experience. This means the analysis cannot claim to measure Mayo Clinic’s actual internal readiness. It can interpret what is visible and connect that interpretation to the wider literature on responsible hospital AI.
The distinction between public evidence and internal proof matters because healthcare AI is vulnerable to overstatement. A hospital may announce a promising tool, a research team may publish strong results, or a public page may describe future applications, yet none of those sources alone proves routine clinical improvement. The paper therefore uses careful language. It treats Mayo Clinic as a case anchor, not as an audited performance subject. The figures are illustrative, not official. The recommendations are generalizable at the level of governance principle, not institutional certification.
This restraint does not weaken the paper. It strengthens it. The most credible research on institutional transformation does not turn limited sources into sweeping claims. It asks what the evidence can support and then builds a responsible argument within that boundary. The visible Mayo Clinic case supports a serious discussion of AI use cases, cardiovascular prediction, clinical trial matching, remote monitoring, governance, and patient-safety discipline. It does not support claims about proprietary model performance, patient outcome improvements, or internal adoption rates.
8.2 Future research needs
Future research should examine how hospital AI performs after deployment, not just during development. The field needs more evidence about drift, alert response, clinician trust, subgroup performance, patient experience, and long-term outcome relevance. Retrospective model validation has value, but the practical question is how tools behave in living clinical systems. A hospital ward, clinic, emergency department, imaging service, or remote-monitoring program creates conditions that retrospective data cannot fully reproduce.
Researchers should also study the patient’s experience of AI-supported care. Much of the literature still speaks from the viewpoint of model developers, clinicians, regulators, and hospital leaders. Patients need stronger representation in research design. How do they understand AI-supported risk prediction? What information do they want? When does AI use increase confidence? When does it create fear? How do patients from underserved communities interpret data-driven medicine in light of prior mistrust or unequal access? These questions are central to ethical implementation.
Another important area is the relationship between AI and workforce burden. Health systems often justify AI through efficiency, yet clinicians may experience implementation as additional labor. Future studies should measure documentation burden, alert fatigue, interruption, workload redistribution, and professional autonomy. A tool that saves administrative time for one group while increasing cognitive burden for another may create hidden cost. Evaluating AI through workforce experience is therefore part of patient safety.
8.3 Educational use for NYCAR and health-management readers
The paper is designed for teaching as well as publication. Health-management students can use it to distinguish technology adoption from institutional transformation. Clinical leaders can use the figures as discussion aids when evaluating new tools. Policy students can use the governance sections to understand how regulation, ethics, and hospital operations intersect. The case also gives master’s-level readers a way to discuss AI without surrendering to technical jargon.
The seven charts are especially useful in a classroom or executive seminar. Students can debate whether the use-case weights are persuasive, whether the risk-pressure profile should change in different hospital types, or how the radar profile would look in a rural hospital, a safety-net hospital, or a private specialty center. Such discussion keeps the paper alive. It turns the Mayo Clinic case into a practical exercise in judgment.
A stronger health-management education will train students to ask disciplined questions before adopting technology. What problem is being solved? Who benefits? Who carries new burden? What evidence is strong enough? What will be monitored? How will patients be informed? What happens if the tool fails? These questions are not anti-innovation. They are the questions that make innovation worthy of healthcare.
8.4 Final research position
The final position of this research paper is that AI-enabled clinical transformation is neither inevitable nor impossible. It is built. It is built through data quality, clinical relevance, workflow humility, professional education, patient communication, governance, equity monitoring, and patient-safety review. Mayo Clinic’s public AI work provides a strong case because it places AI near the actual work of medicine: detecting disease, predicting risk, monitoring patients, matching research opportunities, and individualizing care. The case also reminds us that the most advanced hospital still needs discipline.
The moral center of the argument is simple. Hospitals care for people when they are vulnerable. Any technology that enters that relationship must be held to a higher standard than novelty. It must help clinicians see more clearly, act more wisely, explain more honestly, and protect patients more fully. If AI can do that under accountable governance, it belongs in the future of medicine. If it cannot, it should remain outside the patient’s care until the institution is ready.
References
International Medical Device Regulators Forum. (2025). Good machine learning practice for medical device development: Guiding principles (IMDRF/AIML WG/N88 FINAL:2025). https://www.imdrf.org/documents/good-machine-learning-practice-medical-device-development-guiding-principles
Kelly, C. J., Karthikesalingam, A., Suleyman, M., Corrado, G., & King, D. (2019). Key challenges for delivering clinical impact with artificial intelligence. BMC Medicine, 17, Article 195. https://doi.org/10.1186/s12916-019-1426-2
Liu, X., Cruz Rivera, S., Moher, D., Calvert, M. J., Denniston, A. K., Chan, A.-W., Darzi, A., Holmes, C., Yau, C., Ashrafian, H., Deeks, J. J., Ferrante di Ruffano, L., Faes, L., Keane, P. A., Vollmer, S. J., Lee, A. Y., Jonas, A., Esteva, A., Beam, A. L., … CONSORT-AI and SPIRIT-AI Working Group. (2020). Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: The CONSORT-AI extension. Nature Medicine, 26(9), 1364–1374. https://doi.org/10.1038/s41591-020-1034-x
Mayo Clinic. (n.d.). Artificial intelligence. Retrieved June 8, 2026, from https://www.mayoclinic.org/giving-to-mayo-clinic/our-priorities/artificial-intelligence
Mayo Clinic. (2025, May 10). Artificial intelligence (AI) in cardiovascular medicine. https://www.mayoclinic.org/departments-centers/ai-cardiology/overview/ovc-20486648
Rajkomar, A., Dean, J., & Kohane, I. S. (2019). Machine learning in medicine. The New England Journal of Medicine, 380(14), 1347–1358. https://doi.org/10.1056/NEJMra1814259
Topol, E. J. (2019). High-performance medicine: The convergence of human and artificial intelligence. Nature Medicine, 25(1), 44–56. https://doi.org/10.1038/s41591-018-0300-7
U.S. Food and Drug Administration. (2025, March 25). Artificial intelligence in software as a medical device. https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-software-medical-device
U.S. Food and Drug Administration. (2026). Artificial intelligence-enabled medical devices. Retrieved June 8, 2026, from https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-enabled-medical-devices
Vasey, B., Nagendran, M., Campbell, B., Clifton, D. A., Collins, G. S., Denaxas, S., Denniston, A. K., Faes, L., Geerts, B. F., Ibrahim, M., Liu, X., Mateen, B. A., Mathur, P., McCradden, M. D., Morgan, L., Ordish, J., Rogers, C., Saria, S., Ting, D. S. W., … DECIDE-AI Expert Group. (2022). Reporting guideline for the early-stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI. Nature Medicine, 28(5), 924–933. https://doi.org/10.1038/s41591-022-01772-9
World Health Organization. (2021). Ethics and governance of artificial intelligence for health: WHO guidance. https://www.who.int/publications/i/item/9789240029200